

« Recherche par mot-clé » : un usage qui a changé avec le temps
Si on parle communément de recherche ou requête par « mots-clés », le terme est en réalité ambigu. Il renvoie à l’origine, à une époque où les informations et documents étaient indexés manuellement avec des « mots-clés », « descripteurs » censés les décrire au mieux et où la recherche portait sur ces fameux « mots-clés » et non sur le texte intégral des documents.
Or aujourd’hui, une grande partie des outils de recherche et de veille indexent le texte intégral des documents et pages et font porter la recherche sur cet ensemble. Chez la majorité des bases de données et serveurs scientifiques cependant, la recherche porte toujours par défaut sur le titre, abstract et mots-clés associés aux articles.
L’association de mots-clés à des documents ou articles n’a pas pour autant disparu.
On trouve encore des listes de mots-clés associés aux mémoires universitaires, thèses ou encore articles scientifiques ajoutés par les auteurs eux-mêmes ou les éditeurs.
On peut visualiser des tags associés à des articles de presse ou billets de blogs, essentiels à la navigation et repérage des concepts.
Et c’est sans compter sur les outils et bases de données professionnels qui ont recours à des langages contrôlés, des thesauri ou des systèmes d’indexation automatique par sujet, secteur d’activité ou encore société et même parfois avec intervention humaine.
Mais aujourd’hui, l’usage du terme « mot-clé » a complètement changé.
On parle de recherche par « mot-clé » pour designer la recherche plein-texte alors que la recherche sur des keywords, tags, etc. est plus communément appelée recherche par « descripteur » ou « sujet ».
Nous nous conformerons donc à ce nouvel usage dans cet article et nous nous intéresserons à la façon d’identifier des mots-clés utilisables pour des recherches plein-texte.
Quels outils et sources utiliser pour identifier les bons mots-clés ?
Pour illustrer la méthodologie à adopter et les outils à utiliser, nous avons choisi de partir d’un exemple concret :la mise en place d’une veille sur la thématique des véhicules autonomes.
Nous partons du principe que nous sommes complètement novices sur le sujet et que nous cherchons donc à établir la liste des termes et concepts les plus importants. Dans le but de créer ensuite des requêtes et alertes dans des outils de recherche et de veille mais également d’identifier des sources pertinentes pour réaliser un sourcing fin et précis.
Rien ne vaut un bon brainstorming et un dialogue avec le client
Avant même de commencer la recherche, on pourra d’abord lister les termes venant à l’esprit. On pourra ensuite réfléchir aux catégories de mots et types d’informations dont on va avoir besoin : noms des acteurs sur le marché, noms de voitures, projets, noms de réglementation, innovation, etc.
Comme le sujet ne se limite pas à la France, on ne pourra non plus faire l’impasse sur les termes en anglais au minimum.
On pourra ainsi penser à des termes comme :
- voiture autonome / véhicule autonome
- voiture sans chauffeur
- Google Car
- autonomous car
- etc.
Et il faudra impérativement interroger le demandeur de cette veille ou des experts en interne afin d’obtenir de sa part des éléments précieux dont ils disposent déjà comme les angles importants, le vocabulaire, les noms de produits, les entreprises, les innovations, etc.
Le demandeur ne part jamais de zéro puisqu’il a déjà au minimum conscience qu’il a un besoin d’information alors qu’à l’inverse le professionnel de l’information, lui, n’est pas nécessairement familier du sujet qui lui est soumis.
Mais il sait quant à lui dialoguer avec son client pour comprendre sa question et même l’aider à définir plus précisément son besoin informationnel.
Google et ses différents services : un premier pas vers l’élaboration d’une liste
Malgré ses nombreux défauts, Google est et reste un outil intéressant pour établir le champ lexical gravitant autour d’un sujet.
On pourra déjà interroger le moteur Web de Google avec les termes et expressions dont on dispose déjà.
Le système d’autocomplétion
Le système d’autocomplétion proposé par Google, qui s’appelait avant Google Suggest, qui affiche des suggestions lors de la saisie de la requête, peut déjà fournir quelques pistes intéressantes. Ce système est basé sur ce qu’ont saisi les autres internautes dans le passé.
Lors de la saisie de voiture autonome dans le moteur Web, Google nous suggère ainsi Google, Uber, Tesla, Renault, accident, niveau 5, etc, ce qui nous fournit déjà les noms de quelques acteurs clés (voir figure 1.).
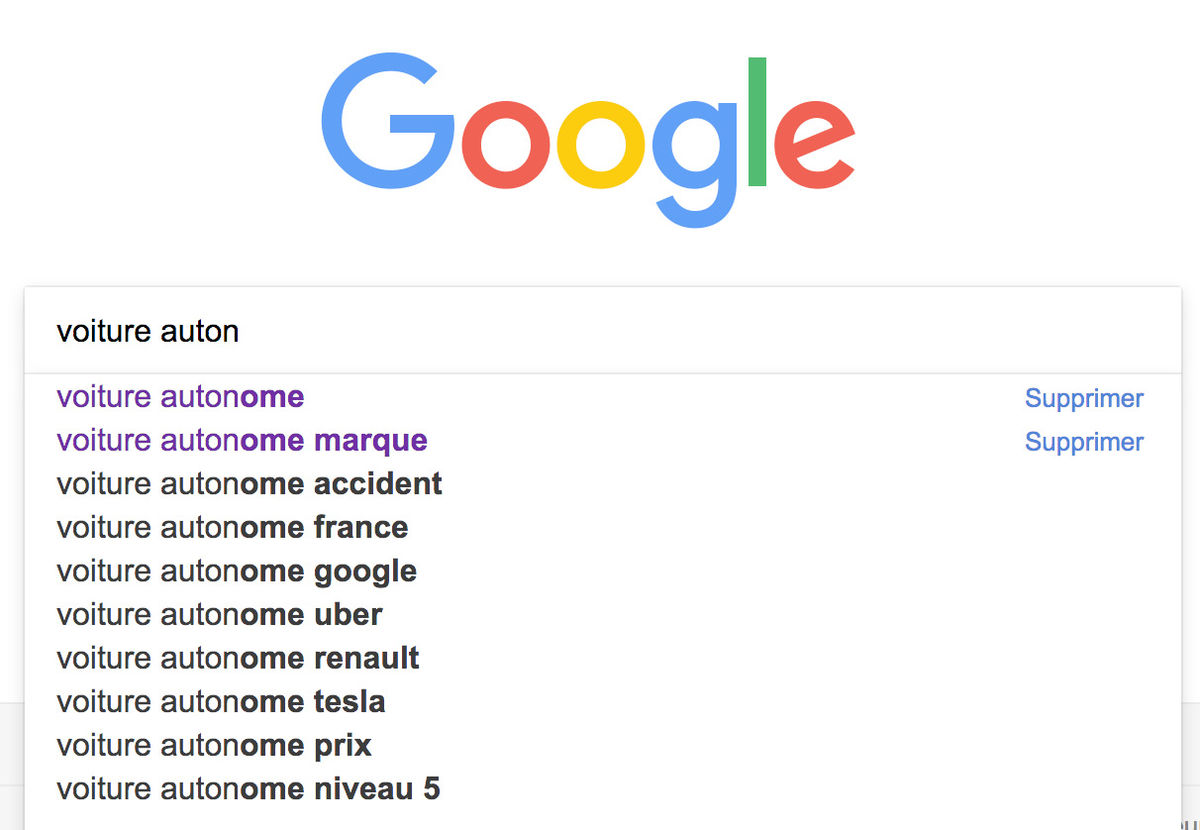
Figure 1. le système d’autocomplétion de Google
La requête voiture sans chauffeur nous suggère par exemple 2020, Rouen, Lyon, Nantes qui laisse supposer qu’il existe probablement des projets dans ces villes qu’il faudra inclure d’une manière ou d’une autre dans sa future stratégie de recherche.
Les différentes formes de « recherches associées »
Dans un second temps, on pourra également tirer parti des « recherches associées » affichées en bas de chaque page de résultats Google (voir figure 2.) qui peuvent ainsi suggérer de nouveaux termes et angles d’attaque. On constate cependant que l’autocomplétion et les recherches associées sont assez similaires même s’il y a quelques différences.

Figure 2. Les recherches associées Google
Plus intéressant encore, on ne négligera pas les « recherche associées » qui s’affichent sous certains résultats. Depuis quelques mois maintenant, Google propose sous certains résultats une liste de recherches associées. Cette liste n’apparaît qu’après avoir cliqué sur le résultat et en revenant ensuite sur la page de résultats Google.
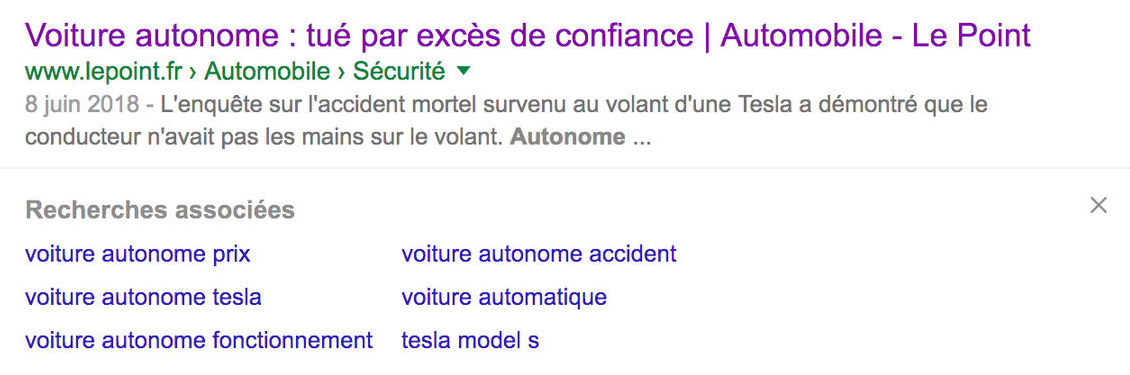
Figure 3. Recherches associées appliquées à chaque résultat
On constate que cette liste varie selon la page consultée, ce qui laisse supposer que l’algorithme tient compte du contenu de la page pour proposer ces suggestions.
Autres méthodes sur Google
On pourra également analyser la ou les premières pages de résultats afin d’identifier des concepts-clés, événements et acteurs majeurs.
On consultera enfin certains résultats jugés pertinents (on privilégiera les sites spécialisés et les articles de fonds) afin d’en extraire des éléments de vocabulaire et de langage.
On pourra ensuite relancer des requêtes sur certains angles identifiés ou en combinant les mots-clés généraux avec d’autres plus distinctifs (nom d’un projet, d’un véhicule, d’une personnalité), etc.
On pensera enfin à interroger les autres services de Google comme Google Actualités qui indexe des sites d’actualités et blogs, son moteur académique Google Scholar, le moteur de livres Google Books.
Google Actualités permet ainsi de repérer thèmes et angles les plus importants du moment comme l’utilisation de la 5G pour les véhicules autonomes, Robocar le nom du premier véhicule autonome à effectuer et finir une course automobile, les investissements de Samsung, Ford ou encore Rolls-Royce sur le sujet, etc.
Alors que Google Scholar ou Google Books vont plutôt permettre de découvrir des concepts et termes plus techniques.
Les méthodes et outils documentaires classiques
Si Google représente une aide indéniable, il ne faut pas oublier les outils et méthodes classiques de la recherche documentaire.
Les dictionnaires de synonymes
On pensera bien sûr aux dictionnaires de synonymes comme CRISCO (crisco.unicaen.fr/des/), Synonymes.com pour le français ou Wordnet (http://wordnetweb.princeton.edu), thesaurus.com ou encore synonym.com pour l’anglais.
Mais dans notre exemple, l’intérêt sera plutôt limité puisqu’on parle d’un concept récent qui n’est pas référencé dans les dictionnaires. On trouvera des synonymes du terme voiture et des synonymes de l’adjectif autonome mais pas de l’expression en tant que telle.
Les générateurs de champs lexicaux
On pourra également interroger les générateurs de champs lexicaux comme https://www.rimessolides.com. Pour l’anglais, l’outil Twinw.rd Ideas (https://www.twinword.com/ideas/graph) est intéressant car il génère un nuage de termes à partir d’un mot et distingue également les termes plus larges ou plus précis que celui initialement recherché.
Les thesauri
Dans la plus pure tradition documentaire, les thesauri, peuvent apporter une aide précieuse notamment pour identifier des termes plus techniques. On essayera donc d’identifier des thesauri spécialisés sur le secteur d’activité ou la discipline liée au sujet.
Dans notre cas, nous recherchons donc un thesaurus lié à l’automobile ou l’électronique. De ce point de vue, le thésaurus développé par IEEE (Institute of Electrical and Electronics Engineers est intéressant et très riche et permet de repérer de nombreux termes notamment liés aux technologies utilisées pour les véhicules autonomes.
On pourra également citer la classification internationale des brevets disponible sur le site de l’OMPI (Organisation Mondiale de la Propriété Intellectuelle). L’OMPI a d’ailleurs développé de nombreux outils linguistiques comme Pearl permettant d’enrichir son vocabulaire (voir BASES n°342 - Novembre 2016).
Les bases de données gratuites et bibliothèques numériques
On pourra également essayer d’identifier des bases de données gratuites ou bibliothèques numériques gravitant autour de ces sujets et secteurs d’activité afin de tirer parti de leur indexation et systèmes de filtres/facettes ou encore de leurs modules de visualisation (par mots-clés par exemple) qui peuvent fournir des éléments pour l’élaboration du champ lexical.
Les bases de données payantes et agrégateurs de presse
Enfin, si on dispose d’accès à des bases de données payantes ou agrégateurs de presse, on procédera de la même manière car ces outils proposent généralement des systèmes d’indexation et de filtres très élaborés ainsi que des fonctionnalités d’analyse et de visualisation qui peuvent suggérer de nombreux mots-clés intéressants.
Au-delà des outils, l’identification puis la lecture et analyse de quelques documents très pertinents lors de la phase de tests est indispensable pour enrichir sa liste.
Les outils liés au Web social
En dehors des méthodologies documentaires classiques, toute la panoplie d’outils liés au Web social peuvent également revêtir un intérêt pour élaborer un champ lexical : wiki, blogs, réseaux sociaux, etc.
Wikipédia
Qui n’a pas déjà utilisé Wikipédia pour obtenir quelques explications et définitions autour d’un nouveau concept. La page dédiée permet bien souvent non seulement de repérer un certain nombre de termes et concepts intéressants mais aussi d’obtenir d’un simple clic cette même page dans les différentes langues disponibles et ainsi acquérir le champ lexical dans les autres langues.
Les systèmes de tags et hashtags
Sur les blogs et sites d’actualités, on pourra tirer parti des tags accolés aux articles.
Sur l’Usine Nouvelle par exemple, les articles relatifs aux voitures autonomes disposent d’un tag « véhicule autonome ». Et en cliquant sur ce tag, on peut alors visualiser tous les articles disposant de ce même tag et repérer les autres tags revenant souvent en lien avec ce thème. Un bon moyen de repérer des noms d’acteurs, de produits, tendances, etc que l’on pourra ajouter à sa liste.
Sur les réseaux sociaux comme Twitter, Instagram, Pinterest et dans une moindre mesure LinkedIn, les internautes font un usage important du système de hashtags. Il se définit comme un mot-clé précédé du signe # qui permet de retrouver tous les messages/posts qui le contiennent. Cela sert à classer l’information d’une part mais aussi et surtout à la (et se) rendre plus visible. Les internautes y ayant recours se limitent rarement à un seul hashtag et ont tendance à en combiner au minimum 3 ou 4.
Dans notre exemple, une recherche sur le hashtag #driverlesscars fait ressortir de très nombreux tweets sur le sujet et on pourra donc s’inspirer des autres hashtags utilisés par les internautes (voir figure 4.)

Figure 4. Tweet comportant une série de hashtags
Les outils de clustering
On pourra également avoir recours aux outils de « clustering » comme
- Exalead (https://www.exalead.com/search),
- Carrot2 (http://search.carrot2.org/stable/search) (voir figure 5.)
- Yippy (http://www.yippy.com)
- ou Cluuz (http://www.cluuz.com)
Dans son nouvel ouvrage « Rechercher l’information stratégique sur le Web » et dont nous parlerons dans le prochain numéro de NETSOURCES, Véronique Mesguich définit ces outils comme des « vitrines de technologies de clustering ou classement automatisé qui regroupent automatiquement les résultats selon des catégories générées à la volée en fonction des occurrences de mots et d’expressions dans les pages correspondants aux résultats ». Ces catégories pourront donc venir enrichir le champ lexical.
On citera également les générateurs de mots-clés comme Infomous par exemple.
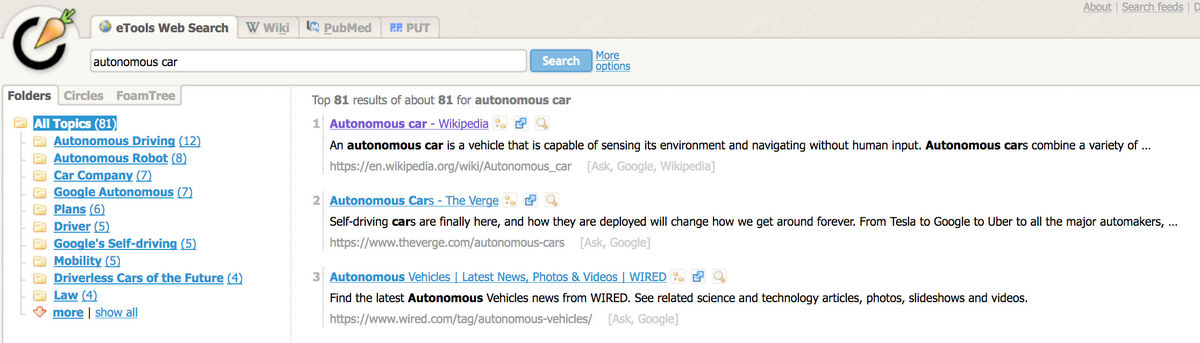
Figure 5. Interface de l’outil de clustering Carrot2
Les moteurs développés par les plateformes de social media monitoring
Enfin, du côté du payant, toute la nouvelle génération de moteurs de recherche développés par les plateformes de social media monitoring comme Quick search (Talkwalker), Sysomos Search, Linkfluence search (Radarly) ou encore Historical Search (Digimind) ont un rôle à jouer lors de la phase d’élaboration du champ lexical. Comme nous avions déjà eu l’occasion de le montrer dans les précédents numéros de NETSOURCES, « De la veille à la recherche rétrospective, il n’y qu’un pas ! » (NETSOURCES n°134 - Mai/Juin 2018) et « Quick Search : quand la veille vient au secours de la recherche » (NETSOURCES n°133 - Mars/Avril 2018), ces outils offrent des fonctionnalités d’analyse et de visualisation intéressantes avec de nombreux graphiques, nuages de mots-clés, etc., permettant de repérer les concepts gravitant autour de son sujet initial, les termes les plus utilisés et repris, etc.
Les outils issus de disciplines connexes : SEO et référencement
Même si on s’éloigne a priori de la recherche d’information et de la veille, le secteur du référencement / SEO (search engine optimization) s’intéresse de très prêt à la question des mots-clés puisque le but est ici d’optimiser la visibilité d’une page web dans les résultats de recherche des moteurs.
Et sur ce créneau, il existe une multitude de petites bases de données et générateurs de mots-clés gratuits ou payants destinés à aider les professionnels du référencement à trouver les bons mots-clés. On pourra les détourner de leur usage initial et les utiliser dans un contexte de veille et de recherche d’information pour élargir le champ lexical de sa recherche.
On citera entre autres
- Google Trends, https://trends.google.fr
- Google Keywor Planner, l’outil de planification de mots-clés proposés par Google Ads, https://ads.google.com
- Wordtracker, https://www.wordtracker.com (freemium)
- Ahrefs, https://ahrefs.com (payant)
- MOZ Keyword Explorer (freemium) - https://moz.com/explorer
- Wordstream, https://www.wordstream.com (freemium)
- Ubersuggest, https://neilpatel.com/ubersuggest
- l’outil de recherche de mots-clés Bing, https://www.bing.com/webmaster/toolbox/keywords
- KW Finder, https://app.kwfinder.com
- Keyword Tool, https://keywordtool.io/fr
- Semrush, https://www.semrush.com
On citera enfin answerthepublic.com, un générateur d’idées original.
Identifier des mots dans d’autres langues
Si la majorité des outils présentés précédemment permettent d’identifier des termes en français et/ou en anglais, on a souvent besoin de s’aventurer vers d’autres langues.
Il faudra alors se tourner vers les très nombreux dictionnaires en ligne, les traducteurs commeGoogle Translate et Deepl, ce dernier étant maintenant considéré comme le meilleur outil de traduction gratuit sur le marché.
On appréciera également Linguee, un dictionnaire qui a le mérite de contextualiser les termes traduits. Il affiche en effet des traductions déjà disponibles sur le Web et notamment issues de sources professionnelles, ce qui permet de traduire plus facilement les termes et expressions techniques.
Comme nous l’avions déjà mentionné tout à l’heure, Wikipédia peut être également utilisé comme un outil de traduction. Depuis la page Wikipédia en français dédiée au véhicule autonome, on peut ainsi découvrir d’un simple clic que cela se dit « Selbstfahrendes Kraftfahrzeug » en Allemand, « Zelfsturende auto » en néerlandais et même « Автономен автомобил » en bulgare...
Enfin, dans les bases de données et agrégateurs de presse payants, il est possible de retrouver des contenus dans des langues que l’on ne maîtrise pas soi-même grâce aux systèmes d’indexation.
Sur la plateforme Newsdesk de LexisNexis par exemple, il existe une indexation sujet « véhicule autonome ». En faisant porter la recherche sur ce terme d’indexation sans entrer le moindre terme en langage naturel, cela fait ressortir des milliers d’articles dans des langues que l’on ne maîtrise pas nécessairement comme l’allemand, l’espagnol, le hollandais, le portugais, le russe, l’italien, le russe, le chinois, le grec et même le népali et le croate ! A l’aide d’un outil de traduction, on pourra ensuite facilement repérer les concepts et termes qui nous intéressent dans ces autres langues.
Pour établir le champ lexical autour d’un sujet de veille ou de recherche, il existe donc une multitude d’outils et de méthodologies à disposition. En fonction des secteurs et sujets, certains fonctionneront cependant mieux que d’autres.
Conclusion
Ce n’est pas parce qu’on dispose d’une liste de mots-clés très complète que la recherche ou la veille qui vont en découler sera automatiquement satisfaisante et réussie.
Car en fonction des outils de recherche et des sources utilisées, il va falloir habilement doser l’utilisation des termes du plus large au plus précis, adapter le niveau de vocabulaire, tirer au mieux parti des fonctionnalités offertes par chaque source et outil pour tomber au plus « juste » en les combinant au mieux.
Seule une connaissance fine de chaque source et outils de recherche et de leur fonctionnement pourra permettre d’y parvenir.
Parmi les questions qu’il faudra alors se poser, on trouvera les suivantes :
- Cet outil recherche-t-il automatiquement les variantes et différentes formes des mots ?
- La longueur de la requête a-t-elle son importance ? Et l’ordre des mots ?
- Quels sont les opérateurs de recherche proposés ? Lesquels pourraient avoir un intérêt pour ma question ?
- Cet outil/source propose-t-il un thesaurus/langage contrôlé
- Existe-t-il des champs de recherche sur lesquels faire porter la recherche ?
- Les documents sont-ils tagués ou indexés avec des mots-clés ?
- Quel est le niveau de langage des documents présents dans cette source ou cet outil (grand public, professionnel, technique, etc. ?)
Toutes ces questions sont cruciales pour réaliser la meilleure veille ou la meilleure recherche possible.
Sur Google par exemple, l’élaboration d’une longue requête combinant l’ensemble des mots identifiés sera par exemple complètement contre-productive comme par exemple :
« voiture autonome » OR « véhicule autonome » OR « autonomous car » OR « autonomous vehicle » OR « driverless car » OR « Google Car »....
En effet, les experts s’accordent désormais à dire que les requêtes courtes avec 3 ou 4 mots sont les plus efficaces sur Google. Les longues requêtes utilisant l’opérateur OR brident au contraire le moteur en fournissant peu de résultats et empêchent de tirer parti des fonctionnalités sémantiques du moteur qui représentent pourtant une de ses forces actuelles. C’est l’inverse de ce qu’il est possible et intéressant de faire sur les agrégateurs de presse et les serveurs et bases de données scientifiques et techniques.
Et tous ces outils de recherche et de veille qu’ils soient gratuits ou payants évoluent vite et continuellement. Seule une veille constante sur le secteur de la veille et de ses outils permet de rester à jour et de réaliser les meilleures veilles et recherches possibles !