


Cette capacité d’adaptation est visible lors de la création des livrables également : après avoir généré une première version de la présentation avec une mise en forme médiocre, l’agent analyse le résultat, puis modifie son propre code pour produire un document présentable.
Cependant, l’analyse des livrables montre un bilan en demi-teinte. Le tableur Excel, bien que rempli, est inexploitable : il contient des paragraphes de texte brut insérés dans les cellules et est rédigé en anglais, alors que le prompt était en français. La présentation PowerPoint est visuellement sobre et efficace, mais l’analyse reste superficielle, avec un graphique aux données partielles. Nous identifions également au moins une erreur factuelle sur un prix.
Paradoxalement, la synthèse textuelle fournie par l’agent dans la fenêtre de chat est bien plus détaillée et qualitative que les livrables finaux.
Pour maximiser la qualité du livrable final, il aurait été judicieux de ne demander que la création d’un seul document pour permettre à l’agent de concentrer ses capacités de calcul sur cette tâche.
Prompt n° 2 : Audit SEO
Nous testons ensuite l’agent sur une tâche de collecte de données SEO : « Effectue un audit SEO complet du site franceculture.fr ; pour cela, tu peux t’appuyer sur des outils tels que Semrush, SpyFu, PageSpeed Insights, ou tout autre outil pertinent. Assemble ensuite un diaporama avec des graphiques et des recommandations concrètes. »
L’agent rencontre des difficultés pour accéder aux sites SEO mentionnés dans le prompt (Semrush, SpyFu, etc.). Il fait cependant preuve d’initiative et contourne le problème en trouvant les informations SEO recherchées via le site mustat.com, respectant ainsi la consigne avec une approche créative. Notons d’ailleurs que l’agent consulte le fichier robots.txt de France Culture pour vérifier les règles d’indexation du site avant de tenter d’en extraire le contenu. Ceci explique probablement pourquoi l’agent n’insiste pas sur certaines sources qui en interdisent l’accès.
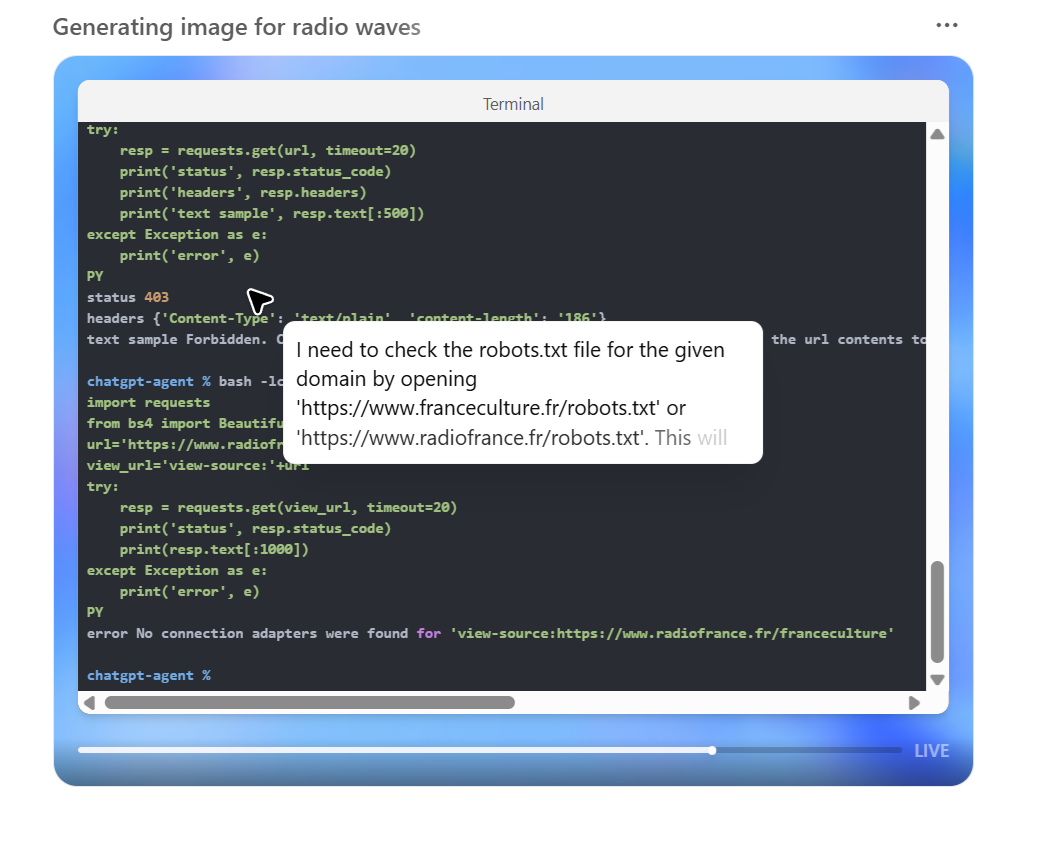
Après 15 minutes, l’agent a effectué 20 recherches, couvrant 144 sources. Il démontre, ici aussi, sa capacité à changer de stratégie en cours de route. Néanmoins, cette flexibilité peut s’avérer problématique. En effet, après avoir constaté ses échecs d’accès aux outils, l’agent déclare : « Je vais ajuster l’approche… en utilisant mes connaissances générales ». Cette initiative, bien que souhaitable dans certains cas, l’expose à un risque accru d’erreurs factuelles ou d’hallucinations. On retient de ce test l’importance de vérifier en amont l’accessibilité des sources fournies à l’agent, au risque d’obtenir des informations issues de sources alternatives ou, pire, inventées.
Prompt n° 3 : Social listening
Enfin, nous avons testé la capacité de ChatGPT Agent à accéder aux plateformes de réseaux sociaux avec ce prompt : « Mène une étude d’écoute sociale (“social listening”) exclusivement sur les réseaux sociaux (X, Facebook, Instagram, LinkedIn, Reddit, Bluesky, etc.), afin d’analyser les conversations, d’en extraire des citations et d’évaluer le sentiment suscité par l’annonce du dernier modèle d’OpenAI, GPT-5. Présente tes résultats sous forme de graphiques et d’un tableau récapitulatif, en ajoutant explicitement les sources sous forme de liens hypertexte. »
En parcourant le détail des actions de l’agent, il apparaît qu’il ne parvient pas à se connecter à la majorité des plateformes de réseaux sociaux, qui se trouvent derrière des pages de connexion. Bien qu’il ait consulté 124 sources, il n’a réussi à accéder qu’à Reddit. L’agent adapte alors sa stratégie en analysant des articles de presse et des billets de blog qui rapportent les réactions sur les réseaux sociaux. Il l’admet d’ailleurs dans sa réponse : « peu de contenus étaient accessibles sans connexion, mais plusieurs articles rapportent des posts viraux où les utilisateurs déplorent la froideur de GPT5 ».
Les résultats fournis par l’agent semblent corrects, mais on regrette l’absence des sources directes, ce qui rend leur vérification difficile. Bien que principalement basé sur des articles de presse, le résultat fait bien ressortir les principales réactions à l’annonce de GPT-5, et tente même de réaliser une analyse du sentiment par plateforme.

III. Capacités, limites et positionnement
Les résultats de ces trois tests donnent un aperçu des capacités actuelles du mode Agent de ChatGPT. L’outil est efficace pour le traitement d’informations librement accessibles sur le web. Sa capacité à scanner des centaines de sources, à établir un plan d’action et à générer des ébauches de livrables en une quinzaine de minutes peut représenter un gain de temps significatif pour certaines tâches. On observe aussi les prémices d’une capacité à orienter les recherches de manière dynamique. L’interface est intuitive, mais la rapidité de l’agent empêche une réelle collaboration pendant la tâche. Elle sert donc principalement de journal d’audit, essentiel pour vérifier a posteriori les actions effectuées et les sources consultées par l’agent.
Le mode Canvas n’étant pas compatible avec ChatGPT Agent, il n’est pas possible de collaborer en temps réel sur un même document avec l’agent. Il est toutefois possible d’interrompre l’agent en cours de travail pour lui fournir des précisions ou informations complémentaires, mais cela décompte un crédit à chaque nouvelle instruction.
Le mode Agent ne se limite pas aux seules tâches ponctuelles. Il est possible de planifier n’importe quelle tâche récurrente (une veille automatisée, par exemple). Pour cela, après l’exécution d’une tâche par l’Agent, sélectionnez « Plus d’actions » (points de suspension), puis cliquez sur « Planification ». Cela vous permet de programmer la fréquence à laquelle l’agent effectuera cette tâche (quotidienne, hebdomadaire, mensuelle).
Toutefois, son autonomie reste limitée par les frictions du web moderne : paywalls, CAPTCHA, et protections anti-bots empêchent souvent l’agent d’accéder à l’information. On observe, par ailleurs, une levée de boucliers de nombreux sites web pour limiter au maximum l’accès à ces agents IA, avec des moyens sophistiqués comme la protection proposée par Cloudflare1.
Pour permettre l’accès à des sites nécessitant une connexion, l’agent a la capacité de demander à l’utilisateur de prendre la main et de saisir ses identifiants. Cela appelle toutefois à une grande vigilance, car une connexion à un compte professionnel ou personnel dans un environnement virtuel hébergé par OpenAI pourrait poser d’évidentes questions de sécurité. Notons également qu’OpenAI propose déjà des connecteurs à des services comme Gmail ou Google Drive, à manipuler avec précaution.
Pour mieux situer la performance du mode Agent, nous l’avons confronté à la solution Manus. Les résultats révèlent deux approches distinctes. Manus présente un plan d’action clair et communique comme un chef de projet, mais sans révéler le détail de ses recherches. Le résultat est un PowerPoint au design très professionnel et au contenu dense. La présentation est générée au format HTML/CSS et peut être convertie en Google Slides ou PowerPoint, mais cette conversion entraîne souvent une modification de mise en forme qui doit être retravaillée manuellement.
Cependant, à l’analyse, le fond se révèle très pauvre : la liste de concurrents est en partie hors sujet et le contenu, bien que qualitatif à première vue, reste très générique et ne cite aucune source. Manus semble privilégier la production d’un livrable esthétique, au détriment de la pertinence de la recherche et de la transparence de ses actions.

Notre avis
Nos tests montrent que ChatGPT Agent n’est pas, en l’état, suffisamment fiable pour effectuer des tâches complexes de bout en bout. Son utilisation, ne serait-ce que pour un « premier jet » de livrable (rapport, présentation, tableur) semble prématurée. Le risque d’erreurs factuelles et le manque de contrôle des sources, observés lors de nos tests, rendent ses productions trop peu fiables pour un usage professionnel direct.
Son utilité réside plutôt dans sa capacité à accélérer la phase de collecte d’information sur un périmètre bien défini. Pour un professionnel familier avec le sujet, il peut défricher un grand nombre de sources en quelques minutes, en complément d’un travail de recherche personnel. ChatGPT Agent, à l’heure actuelle, peut être vu comme une alternative à l’utilisation de la fonctionnalité Deep Research ou comme un outil complémentaire à un travail de recherche personnel, utile pour recouper des informations ou enrichir une veille classique.
ChatGPT Agent offre néanmoins un aperçu du futur de l’IA. Ses capacités à planifier, à itérer sur son propre code pour améliorer un résultat, ou à opérer un pivot stratégique face à un obstacle sont des signes prometteurs. On peut raisonnablement penser que ses performances s’amélioreront à mesure de l’intégration des nouveaux modèles, tel que GPT-5 Thinking. Pour l’heure, c’est un outil puissant, mais perfectible, dont l’efficacité réside dans la capacité de l’expert à le manier avec habileté.