



Faire une recherche en IST, ce n’est certainement pas se limiter à Google Scholar, même si cette source n’est pas nécessairement inutile.
Nous avons rassemblé dans une infographie (voir Figure 1.), les principaux types d’outils de recherche à connaître pour l’information scientifique et technique.
Il est important d’avoir en tête cette typologie pour pouvoir ensuite mobiliser les outils adaptés à sa problématique précise.
Nous allons explorer plus précisément dans la suite de cet article chaque catégorie d’outils et présenter plus en détails les outils s’y rapportant avec leurs forces, faiblesses et leur positionnement dans le processus de recherche et de veille.

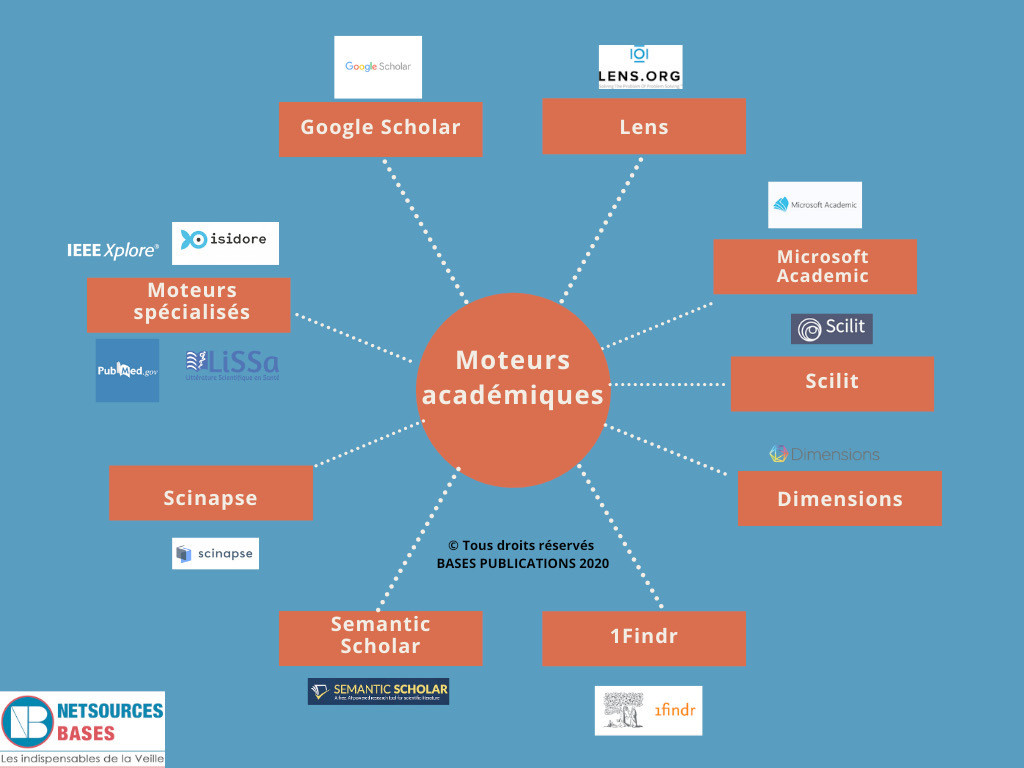
Figure 2. Panorama des moteurs académiques
Les moteurs académiques : partie émergée de l’iceberg
Partie émergée de l’iceberg, les moteurs académiques sont les outils les plus visibles et les plus connus pour rechercher l’information scientifique. Nombreux sont les internautes qui connaissent aujourd’hui Google Scholar. Malgré sa visibilité, ce n’est pas pour autant l’outil le plus approprié.
Ces moteurs généralistes, gratuits ou parfois fonctionnant sur un modèle freemium, indexent majoritairement des articles scientifiques mais pas seulement. Certains intègrent d’autres formes de publication scientifique comme les preprints (articles publiés avant révision par les pairs), des articles de blogs académiques, des images, parfois des brevets, des datasets, des essais cliniques, des thèses, des ouvrages académiques, etc.
Nous avons référencé ici dans une infographie les principaux moteurs académiques (voir figure 2.)
Google Scholar : le plus connu
On ne saurait parler de moteur académique sans mentionner Google Scholar. Lancé en 2004, le moteur académique de Google est venu bousculer le modèle établi pour la recherche scientifique et académique.
Tout d’abord parce que jusqu’alors, la recherche se faisait essentiellement sur des serveurs et bases de données scientifiques qui étaient payantes. Et Google Scholar était, quant à lui, complètement gratuit.
L’autre changement majeur, c’est que Google est arrivé avec un produit qui indexait le texte intégral de la littérature scientifique et académique (grâce à de nombreux partenariats avec les éditeurs) et permettait de rechercher sur l’intégralité du contenu alors que la majorité des outils existant se contentaient d’indexer et de ne rechercher que sur les références bibliographiques (titre, auteur, abstract, etc.).
Attention, pour autant, Google Scholar ne donne pas accès gratuitement aux articles en texte intégral à l’exception de ceux accessibles librement sur le Web.
Forces et faiblesses
Google Scholar dispose d’un des index les plus importants pour l’information scientifique et technique. Il indexerait même plus de documents que les outils professionnels payants comme Scopus ou Web of Science et un volume sensiblement similaire aux serveurs comme STN ou Dialog Solutions. Mais comme toujours avec Google, ce n’est pas parce qu’il indexe un très gros volume de documents qu’il y donne nécessairement accès.
Google Scholar n’affiche jamais plus de 1 000 résultats (même s’il en annonce des millions), ce qui reste néanmoins un peu mieux que pour son moteur web (qui affiche rarement plus de 200/300 résultats.).
Il indexe une plus grande variété de documents académiques et de langues que les grands outils de recherche payants.
Mais la recherche reste simpliste et l’algorithme de Google Scholar est une véritable boîte noire qui ne permet absolument pas de savoir s’il a bien fait émerger les documents les plus pertinents par rapport à une requête donnée.
D’ailleurs l’une de ses forces est aussi devenue l’une de ses faiblesses. En indexant les documents en texte intégral sans récupérer les métadonnées des éditeurs, Google Scholar n’est pas en mesure de proposer des filtres de recherche puissants comme la majorité de ses concurrents directs.
Parmi ses autres forces majeures, on citera sa fonctionnalité de citations. Pour chaque article, Google Scholar indique quels sont les autres articles scientifiques citant cet article, ce qui peut être un excellent moyen de repérer des articles traitant d’un thème proche. De par la taille de son index, Google Scholar arrive à proposer plus de citations pour un même article que la plupart de ses concurrents.
Outil gratuit incontournable pour la recherche en IST, il ne faut certainement pas s’y limiter au risque de manquer de nombreux articles et documents pertinents.
Microsoft Academic à l’assaut de la recherche sémantique
Comme sur le créneau des moteurs web, Microsoft est ici aussi un concurrent de Google Scholar.
En 2006, Microsoft avait lui aussi lancé son moteur académique appelé à l’époque Microsoft Academic Search. L’outil avait été abandonné en 2012 puis relancé sous une autre forme en 2016. L’outil s’appelle aujourd’hui Microsoft Academic.
Il se démarque des moteurs académiques classiques en ce sens qu’il s’agit d’un moteur sémantique. L’outil, dopé à l’IA et plutôt au machine learning ne fonctionne pas sur un modèle booléen classique.
Il est de prime abord assez déstabilisant pour des professionnels de l’information.
Il indexe aujourd’hui près de 250 millions de documents.
Forces et faiblesses
Il a l’avantage de proposer de nombreux filtres de recherche (topics, type de publication, auteurs, revues, institution, thésaurus). Il liste également les références et citations de l’article et propose des résultats qu’il juge similaires.
Si pendant de nombreuses années, il permettait d’afficher plusieurs milliers de résultats alors que Google limitait à 1000, ce n’est désormais plus le cas et on ne peut visualiser que les 500 premiers résultats (on peut néanmoins choisir un classement par pertinence mais aussi par ordre chronologique ou antéchronologique).
Il y a encore quelques années, Microsoft Academic produisait peu de résultats pour chaque requête, rendant le moteur quasi inutile pour la recherche en IST. L’outil s’est désormais amélioré et mérite d’être intégré à sa liste d’outil.
Lens.org : la nouvelle génération qui mêle littérature scientifique et brevets
Avec le développement du mouvement de l’open science (open access, open data, open citations, etc.), de nouveaux outils surfent sur cette tendance et tirent parti de cette masse d’information accessible librement.
The Lens est un moteur de recherche académique produit par l’Université australienne du Queensland. Lancé dans les années 2000 mais uniquement comme un outil de recherche brevets, l’outil a considérablement évolué au cours des dernières années en devenant un véritable moteur académique.
Il intègre aujourd’hui plus de 200 millions de références bibliographiques (articles de journaux, chapitres d’ouvrages, comptes-rendus de conférences, etc.) issues de Microsoft Academic, PubMed ou encore Crossref.
Il est complètement gratuit et permet de réaliser de véritables requêtes booléennes complexes. Il propose également de très nombreux filtres.
Il propose aussi un outil de recherche brevet et fait le lien entre la littérature scientifique et les brevets en indiquant quand un article cite un brevet et vice et versa, ce qui est unique en la matière pour un outil gratuit.
En plus des traditionnels références, citations et documents similaires, The Lens permet également de savoir si un document a été ajouté par un internaute dans une « collection » et de visualiser cette dernière. Un bon moyen de tirer parti du travail de curation réalisé par d’autres.
Il propose également des fonctionnalités d’analyse et de dataviz.
Dimensions : la force de la recherche par similarité et une offre avec différents types de contenus
Dimensions est également un moteur académique qui mérite que l’on s’y arrête.
Dimensions a été lancé en 2018 et indexe plus de 150 millions de documents (Crossref, PubMed, OpenCitations, bases des offices de brevets), d’archives ouvertes (comme Agritrop), d’entrepôts de de preprints (comme ArXiv, BioRxiv), d’entrepôts de données (comme Figshare, Dryad, Zenodo), etc.
A l’origine, il s’agissait essentiellement d’articles scientifiques mais cela a été progressivement élargi aux datasets (données de la recherche), brevets, financements (grants), essais cliniques et « policy documents ».
L’outil est disponible en version freemium et seuls les articles et datasets sont disponibles dans la version gratuite.
Forces et faiblesses
Il a réussi à étendre sa couverture au cours des dernières années même s’il a encore un index un peu limité par rapport à certains concurrents.
Parmi ses forces, on notera la possibilité de rechercher uniquement sur les références bibliographiques ou sur le texte intégral des documents. Il propose également une fonctionnalité de recherche par similarité intéressante. On entre l’abstract ou un morceau d’abstract jugé pertinent et l’outil se charge de rechercher des documents « sémantiquement » proches.
Comme la majorité de ses concurrents, il donne accès aux références et citations des articles quand ils sont disponibles.
Semantic Scholar à l’assaut des résumés automatiques
Semantic Scholar est un projet développé à l’Institut Allen pour l’intelligence artificielle. A l’origine très centré sur le biomédical et l’informatique, il est aujourd’hui généraliste et indexe plus de 170 millions de documents.
Il se positionne sur le même créneau que Microsoft Academic en mettant en avant la recherche sémantique et la place de l’IA.
Forces et faiblesses
Le moteur a récemment fait parler de lui en proposant une IA qui résume les articles scientifiques en une phrase. Pour l’instant, cela ne s’appliquerait qu’aux articles en informatique (soit 10 millions d’articles référencés dans Semantic Scholar).
C’est une première pour un moteur académique gratuit.
Il existe d’autres outils qui proposent des résumés automatiques d’articles scientifiques comme Scholarcy, Paper Digest, etc. mais ce ne sont pas des moteurs de recherche.
Voir aussi BASES n°370, mai 2019
On suivra de près les évolutions de ce moteur prometteur.
Autres challengers
Il existe d’autres moteurs académiques mais ils sont moins intéressants et présentent moins de valeur ajoutée que leurs concurrents.
On pourra citer Scilit, un moteur qui indexe tout de même près de 150 millions de documents.
Mais aussi 1findr, très prometteur à ses débuts mais qui a été racheté par Elsevier en cours de route et propose aujourd’hui peu de fonctionnalités innovantes dans sa version gratuite.
On citera enfin Scinapse (Corée) dont le slogan est « We’re better than Google Scholar. We mean it. » mais qui finalement s’avère moins innovant que ses concurrents et est très dépendant de Microsoft Academic.
La force des moteurs spécialisés sur une discipline
Au-delà de ces moteurs académiques généralistes, il ne faut pas faire l’impasse sur les moteurs académiques spécialisés sur un domaine. C’est par exemple le cas de Pubmed pour le médical au niveau international ou Lissa pour la littérature médicale en français, Isidore pour les SHS francophones, IEEE pour les sciences de l’ingénieur, etc.
Ces outils offrent l’avantage de rechercher sur des corpus très qualifiés et proposent des fonctionnalités de recherche (indexation, filtres, etc.) spécifiques au domaine en question.
Pour les identifier, on pourra :
- lancer des recherches sur Google en croisant des termes comme
search engine, academic search engine, database, etc. avec des termes liés à la discipline (biomedical, medical, health, etc.) ; - on pourra également regarder les libguides ou guides de recherche publiés par les bibliothèques universitaires qui présentent généralement brièvement les outils de recherche clés d’une discipline.
Notre avis :
Les moteurs académiques sont des ressources incontournables pour la recherche d’information scientifique et technique.
La tentation est grande de n’interroger qu’un seul moteur pour gagner du temps mais cela s’avère souvent une erreur stratégique. Chaque outil dispose d’un corpus spécifique et de fonctionnalités de recherche différentes.
Lors de la conférence Evidence Based Health Care (EBHC) 2019 qui aborde notamment la question des revues systématiques en santéUne revue systématique est le fruit d’une démarche scientifique rigoureuse constituée de plusieurs étapes bien définies, incluant une recherche de littérature systématique, une évaluation de la qualité de chaque étude considérée et une synthèse, quantifiée ou narrative, des résultats obtenus. Le résultat de ce travail permet de conclure, par exemple, à l’efficacité d’un traitement, le risque d’effets indésirables ou la performance d’un test diagnostique. (Source : Cochrane), une étude avait montré qu’il y avait jusqu’à 66% d’articles manqués pour une revue systématique si on utilisait seulement Pubmed.
Il est donc crucial d’utiliser plusieurs moteurs pour arriver à un résultat satisfaisant.
D’autre part, il ne faut pas utiliser tous ces moteurs de la même façon. A l’exception de Lens qui permet véritablement d’entrer des requêtes booléennes, et dans une moindre mesure Google Scholar, il est préférable d’utiliser des requêtes simples sur les autres moteurs et de tirer ensuite parti des filtres et de l’indexation. Et c’est encore plus vrai pour les moteurs sémantiques comme Microsoft academic ou Semantic Scholar.
Si on ne maîtrise pas le langage d’interrogation des moteurs, on pourra toujours s’aider de 2D Search (https://www.2dsearch.com/) un outil gratuit conçu pour créer ses requêtes en 2D sur les moteurs et bases de données. Google Scholar, Lens et Pubmed sont disponibles via cet outil même si nous émettons quelques doutes pour Google Scholar qui n’est pas véritablement adapté aux requêtes booléennes.
Les serveurs et bases de données scientifiques
Bien plus anciens que les moteurs académiques, les serveurs et bases de données scientifiques indexent des dizaines de millions de documents scientifiques et proposent des fonctionnalités de recherche avancées et des résultats non opaques. Mais ces outils sont payants.
Parmi les plus connus, on pourra citer les serveurs historiques comme STN ou Dialog Solutions, découpés en bases de données thématiques mais dans lesquels on peut aussi rechercher globalement. Il y a également les outils développés par les éditeurs eux-mêmes comme Scopus et Web of Science qui, de leur côté, permettent d’interroger tout le corpus au sein d’une même interface.
Par rapport aux moteurs académiques et autres outils gratuits, ces outils offrent des fonctionnalités de recherche plus avancées et expertes, des corpus de sources plus qualifiés et vérifiés (ce qui est un plus dans un contexte de désinformation où les sciences ne sont pas épargnées) ainsi que de fonctionnalités d’analyse poussées.
Pendant longtemps, les publications en open access n’étaient pas ou très peu référencées dans ces outils. Mais la majorité ont aujourd’hui une bonne couverture de l’open access. Scopus annonçait même récemment l’ajout de prépublications (preprints) La prépublication désigne les versions d’un texte produit par un (des) auteur(s) avant acceptation par un comité de rédaction d’une revue et avant révision par un comité de lecture (évaluation par les pairs) si la revue en bénéficie. (Source : CNRS) issues d’archives ouvertes comme Arxiv, Biorxivpreprint ou encore ChemRxiv.
Mais tout cela a un coût qui n’est pas nécessairement supportable quand on ne recherche l’information scientifique et technique que ponctuellement.
Les archives ouvertes et moteurs liés à l’open access
Même si les publications en open access sont référencées sur les moteurs académiques ainsi que les serveurs et bases de données payantes, il n’empêche que cela n’est jamais exhaustif.
On a également intérêt à jeter un coup d’œil aux ressources spécifiques à l’open access.
Parmi les moteurs incontournables, on citera :
- BASE (https://www.base-search.net), un moteur qui moissonne une très grande quantité de bases de données académiques en libre accès et archives ouvertes (plus de 8 500 fournisseurs d’information) et qui est géré par la Bibliothèque de l’Université de Bielefeld ;
- Core (https://core.ac.uk/) un moteur qui référence plus de 200 millions de papiers en open access ;
- OpenAire (https://explore.openaire.eu/) qui référence plus de 123 millions de documents ;
- DOAJ (Directory of Open Access Journals, https://doaj.org/) qui référencent avant tout des publications mais aussi de nombreux articles ;
- DOAB (Directory of Open Access Books, https://www.doabooks.org/), l’équivalent du DOAJ mais pour les ouvrages académiques ;
- Paperity, qui se présente comme un agrégateur de revues et articles scientifiques (https://paperity.org/) - Plus de 7 millions de documents sont actuellement référencés.
On citera également les nombreuses archives ouvertes où les chercheurs peuvent déposer leurs travaux et parfois également les étudiants comme :
- ArXiv, l’ancêtre des archives ouvertes ;
- BiorXiv ;
- HAL pour la France ;
- OSF Preprints qui fournit de nombreuses archives ouvertes thématiques comme AfricarXiv, Frenxiv, etc ;
- REPEC pour les sciences économiques, etc.
Pour identifier une archive ouverte sur la thématique ou le pays qui nous intéresse, on pourra consulter Open Doar, l’annuaire des archives ouvertes au niveau mondial https://v2.sherpa.ac.uk/opendoar/ ou http://roar.eprints.org/, un autre annuaire dans la même veine.
Les outils de recommandations scientifiques
Depuis quelques années, on voit également apparaître des outils de recommandations automatiques qui visent avant tout les chercheurs mais qui peuvent également être utilisés par les professionnels de l’information.
Le principe est simple : l’internaute décrit les thèmes qui l’intéressent soit à partir de mots-clés, tags, requêtes en langage naturel, ou encore d’une sélection de documents jugés pertinents, et l’outil se charge de lui proposer régulièrement de nouveaux documents jugés similaires.
Les recommandations concernent essentiellement les articles scientifiques et peu les autres types de documents.
On citera des outils comme :
Pour plus d’information, on pourra consulter notre article « Les nouveaux outils de recommandation pour l’IST » paru dans le n°379 de BASES de mars 2020.
Notre avis :
Le discours commercial de ces outils insiste sur le fait qu’il n’est plus nécessaire de passer du temps à rechercher de l’information puisque l’algorithme de recommandation s’en charge tout seul ! Bien évidemment, ce discours est très réducteur et non adapté mais à l’usage, on constate qu’ils permettent d’identifier quelques articles non repérés avec d’autres méthodes.
Inversement, ils passent également à côté de nombreux documents pertinents. On pourra donc les utiliser en complément à d’autres outils de recherche.
Les outils de recherche par réseau et citations
2020 a été une année riche pour la création d’outils de recherche académiques se basant sur les réseaux de citations. Et cela s’explique par une raison simple. Le mouvement de l’ « open citations » prend de l’ampleur et les éditeurs scientifiques et académiques (en dehors des publication en open access qui le font déjà depuis longtemps) commencent à rendre accessibles les références et citations des articles qu’ils publient. A partir de cette matière précieuse en libre accès, de nombreux outils ont vu le jour.
Ces outils ont tous un principe similaire : ils explorent tous le réseau de citations à partir d’un ou plusieurs articles donnés pour proposer à l’internaute d’autres articles susceptibles de l’intéresser.
Parmi ces outils, on pourra citer :
- - CoCites (https://www.cocites.com/) – il s’agit d’une extension de navigateur qui fonctionne sur Google Scholar et Pubmed ;
- - Connected Papers (https://www.connectedpapers.com/) qui à partir du titre, DOI ou url d’un article scientifique permet de visualiser graphiquement le réseau de citations et accéder aux articles repérés ;
- - Citation Gecko (https://citationgecko.azurewebsites.net/) qui fonctionne sur le même principe mais qui permet d’entrer plusieurs articles de référence et voir les différents liens de citations entre les différents articles ;
- Vosviewer (https://www.vosviewer.com/) qui est un logiciel téléchargeable mais propose également une version web ;
- Dans la même veine, on citera également Citespace (http://cluster.cis.drexel.edu/~cchen/citespace/) ;
- Papergraph (https://papergraph.dbz.dev), plus rudimentaire que ses concurrents ;
- Local citation Network (https://timwoelfle.github.io/Local-Citation-Network) qui fonctionne à partir du DOI d’un article ;
- Scite.ai (https://scite.ai) a quant à lui un positionnement un peu différent car il explore les réseaux de citations à partir du titre d’un article, DOI, nom d’auteur, mot-clé et indique pour chaque citation si elles sont positives, neutres ou négatives. Le but étant de lutter contre la désinformation qui sévit aussi dans le domaine scientifique. Certains articles sont cités non pas parce qu’ils sont pertinents mais pour être critiqués ou remis en question ;
- Inciteful (https://inciteful.xyz/), un outil que nous avons repéré très récemment.
Notre avis :
Comme pour les outils de recommandations automatiques, ces outils d’un nouveau genre s’avèrent intéressants pour compléter des recherches mais ne peuvent être utilisés seuls lors d’une recherche ou d’une veille scientifique et technique.
Les outils de recherche de datasets
Pendant très longtemps, les données de la recherche n’étaient jamais mises à disposition. Seul le résultat final, c’est à dire l’article scientifique était publié.
Toujours dans ce contexte du mouvement de l’open, les chercheurs et leurs institutions mettent de plus en plus souvent à disposition leurs jeux de données appelés datasets.
Certains moteurs académiques, comme Dimensions par exemple, en référencent mais il existe aussi des outils entièrement dédiés à ce type d’information.
On pourra citer :
- Mendeley Data (https://data.mendeley.com/) proposé par Elsevier ;
- Figshare (https://figshare.com/) ;
- Zenodo (https://zenodo.org/) ;
- Data Dryad (https://datadryad.org/search).
Google propose lui aussi un moteur de datasets appelé Dataset Search mais il mêle indistinctement les données de la recherche et les données ouvertes publiées par les collectivités et entreprises qui n’ont rien à voir avec l’information scientifique et technique.
Les outils dédiés aux thèses et mémoires
Dans le cadre d’une recherche sur l’information scientifique et technique, il ne faut pas non plus oublier les thèses et mémoires. Si là encore, certaines sont référencées dans les moteurs académiques, il faudra se tourner vers des outils de recherche spécifiques pour plus d’exhaustivité.
On pensera notamment à :
- NDLTD (Networked Digital Library of Theses and Dissertations), http://www.ndltd.org/ ;
- Open Access Theses and Dissertations (https://oatd.org/) ;
- Dart Europe (https://www.dart-europe.org/basic-search.php) ;
- EBSCO Open Dissertations (https://biblioboard.com/opendissertations/);
- ou encore Thèses.fr pour les thèses françaises.
Pour aller encore plus loin, il ne faut pas hésiter à aller explorer plus en profondeur les bases de données, archives ouvertes et moteurs développés localement ou au niveau de certaines universités.
Nous avions consacré un dossier spécial à ce sujet dans « Tour du monde des sites de thèses en accès libre - Dossier spécial » dans BASES n°372 – juillet/août 2019.
Les outils dédiés aux conférences scientifiques
Les comptes-rendus de conférence académiques sont également riches en information et pas forcément bien référencés dans les outils de recherche classique.
On peut les trouver sur le site web de la conférence dans une rubrique généralement appelée « proceedings », « actes » ou « comptes-rendus » mais il faut parfois acheter l’intégralité des actes, ce qui représente un budget conséquent d’autant que tout ne nous intéresse pas forcément.
Les serveurs et bases de données professionnels comme Scopus, Web of Science, Proquest, Dialog Solutions, STN, EBSCO, proposent une bonne couverture de ces événements.
Proquest propose par exemple une base de données intitulée Conference Papers Index. On citera également la base Proceedings First proposée par l’OCLC ou encore Internationale Jahresbibliographie der Kongressberichte (IJBK), la bibliographie annuelle des actes de congrès disponible en allemand et en anglais. Dialog Solutions vient d’intégrer de son côté Morressier poster and abstract database (voir « Dialog : une nouvelle base sur les conférences » dans le BASES n°386 de novembre 2020) en plus des traditionnels Northern Light Life Sciences Conference Abstracts Collection, la British Library conference index ou encore Conference Papers Index.
On pourra également identifier certains de ces comptes-rendus via les moteurs académiques.
Les autres sources à ne pas oublier
Les sites des éditeurs
Même si les éditeurs académiques fournissent pour la plupart leurs données bibliographiques aux moteurs académiques et serveurs et bases de données, on n’oubliera pas qu’ils proposent tous des outils de recherche pour leurs propres collections. On pensera à des sites comme Elsevier, Wiley, Open Edition, Plos, Springer, etc. qui sont gratuits à interroger (mais les articles sont ensuite payants à l’exception de ceux en open access).
Les catalogues de bibliothèques
Les catalogues de bibliothèques référencent aussi les revues scientifiques et académiques ainsi que les articles associés présents dans leurs collections. Au niveau mondial, on pourra penser à interroger Worldcat, le plus grand catalogue de bibliothèque au monde (https://www.worldcat.org/).
Le cas du blogging scientifique et de la vulgarisation scientifique
On l’oublie souvent mais la recherche scientifique et académique peut également s’exprimer à travers des blogs. Ils peuvent être référencés dans certains des outils évoqués précédemment mais ce n’est pas toujours le cas, loin de là.
On devra donc aller effectuer des recherches sur des plateformes spécialisées sur les blogs académiques comme hypothèses.org, http://sciencepresse.qc.ca, http://www.cafe-sciences.org ou encore https://scienceblogs.com/.
On pourra également identifier ces blogs en croisant sur Google des termes relatifs au blogging scientifique comme scientific blog, academic blogging, carnet de recherche, etc. avec des termes relatifs à la discipline ou au domaine qui nous intéresse.
Les chercheurs peuvent également publier des informations intéressantes sur les réseaux sociaux classiques comme Twitter notamment ou les réseaux sociaux scientifiques comme Academia, ResearchGate ou encore MySciencework.
Ils peuvent également partager certains supports présentés lors de conférences ou journées d’études sur des sites de présentations comme Slideshare ou proposer des vidéos sur YouTube.
On ne négligera donc pas non plus ces sources dans le cadre d’une recherche en IST.
Tirer parti des veilles et bibliographies créées par des organismes spécialisés
Quand on n’est pas spécialiste de l’information scientifique et académique, il peut également être intéressant de tirer parti du travail d’autres professionnels de l’information travaillant dans un organisme et une structure spécialisé.
Certains proposent des portails documentaires ou diffusent sur leurs sites voire même sur des médias sociaux leurs veilles thématiques et leurs bibliographies thématiques.
Si certaines de ces veilles et bibliographies peuvent être référencées dans les moteurs académiques, on aura plutôt intérêt à identifier en premier lieu des organismes spécialisés sur le sujet ou la discipline qui nous intéresse puis explorer le site (ou interroger le site via Google grâce à l’opérateur site:) pour détecter la présence d’un éventuel portail documentaire, de produits documentaires ou veilles thématiques.
C’est par exemple le cas de l’INRS qui vient tout juste de mettre à disposition du public son portail documentaire (https://portaildocumentaire.inrs.fr/) où l’on peut accéder à des dossiers documentaires, de la veille juridique et des bulletins de veille thématique (organisation et situations de travail, risques physiques et mécaniques, risques biologiques, fondamentaux de la prévention ou encore risques chimiques).
Avec la situation sanitaire actuelle, de nombreux organismes ont également mis à disposition leurs veilles sur la Covid 19. On pensera par exemple à :
- Bibliovid.org, une veille bibliographique réalisée par des étudiants et un ingénieur de l’INSERM (https://bibliovid.org)
- LittéCovid, une revue systématique de la littérature sur la thématique de la Covid19 proposée par la Documentation Centrale des Hospices Civils de Lyon.
Il existe d’autres exemples de veille sur le Covid-19 que nous avions évoqués dans les articles :