









L’intelligence artificielle s’intègre dans nos activités quotidiennes. À l'ère de la taylorisation rampante dans la zone «col blanc» de l’entreprise, les métiers de la donnée et de la connaissance se polarisent : exécution automatisée d›un côté, compétences de cadrage vitales de l›autre.
Netsources est une boussole dans cette mutation. Nous identifions les compétences qui résistent à l’automatisation, celles qui maintiennent l’humain aux commandes. Car la vraie question n’est pas «que peut faire l’IA ?», mais « que devons-nous savoir faire pour rester pilotes ? »
Sans questions, pas de valeur
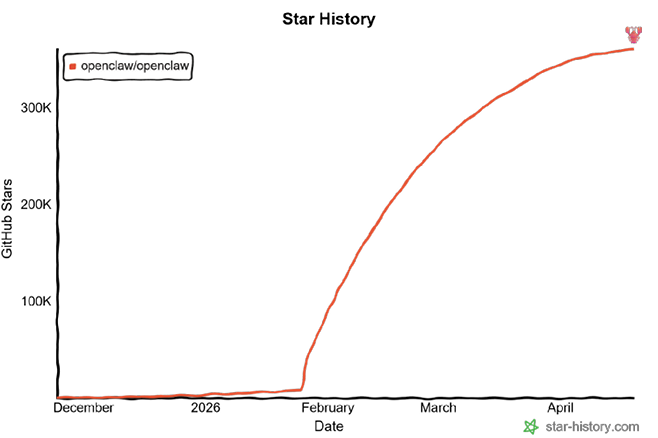
Comme Christian Vigne l’avait souligné fin 2024 dans sa chronique «Mon premier paper : Answers in abundance, questions in scarcity», que nous publions ici pour la première fois : le problème n’est pas la machine avec son offre infinie de réponses, mais la question, souvent rare et mal formulée.
Un an après, avec une adoption B2B en forte croissance et des investissements triplés, cette «crise de la demande» demeure un sujet majeur: résultats aléatoires, bulle spéculative, débats sur l'intelligence réelle des LLMs.
Monter le décor
Ulysse Rajim présente le pas suivant après le prompt engineering : le context engineering. On n’écrit plus une phrase magique, on monte un décor entier - données, outils, sécurité - pour éviter que l’agent ne s’égare, se noie dans l’info ou se contredise. Savoir structurer ce contexte : une compétence fondamentale.
Lire aussi :
Le prompt, un art pour la veille stratégique et la recherche d'information 1ère et 2eme partie (Véronique Mesguich)
Choisir devient composer
Véronique Mesguich décrypte la contre-attaque de Google qui clarifie sa stratégie en intégrant l’IA dans ses écosystèmes pros, et la riposte des concurrents par la spécialisation: du «tout-en-un» vers des domaines ciblés (codage, recherche, création). On ne choisit plus un outil unique, mais on construit un portefeuille qu’il faut sans cesse suivre et valider. Une posture clef pour bâtir des stratégies IA hybrides.
Accélérer, pas remplacer
Elodie Charrière explore comment l’IA génère scripts, légendes et visuels sur mesure pour les réseaux sociaux. Les créateurs laissent l’IA écrire, trouver des angles. Non pour être remplacés - pour aller plus vite, tester, optimiser l’engagement. La compétence vitale ? Préserver l’intention créative. L’IA exécute, l’humain dirige.
Face à l’IA, structurer un contexte, orchestrer des outils, préserver une intention : ces compétences déterminent qui garde la main. Car formuler une question pertinente échappe à la taylorisation. C’est la compétence du cadre, pas de l’exécutant.




















