Sélectionner le numéro de "Bases" à afficher
Explorer d’autres voies de pérennisation des savoirs


Corinne DUPIN, Directrice associée chez Ourouk
Cet article propose un pas de côté dans le sillage d’Olivier Hamant et de Laurent Bibard dans l’idée de revitaliser avec eux nos pratiques de professionnels de l’information.
Lors des premières rencontres de l’Observatoire de l’Apprenance de SOL France (1) les 27 et 28 novembre derniers, deux intervenants ont particulièrement attiré mon attention, essentiellement pour leurs propos contre-intuitifs : Olivier Hamant, biologiste à INRAE (2), auteur d’un « Antidote au culte de la performance » (3) et directeur de l’Institut Michel Serres (4) et Laurent Bibard, philosophe et enseignant à l’ESSEC, qui a dirigé la chaire Edgar Morin de la complexité. À les écouter, il m’est venu l’idée de transposer leur pensée dans les problématiques rencontrées par les professionnels de l’information, dans la perspective de les éclairer sous un jour nouveau.
L’« apprenance » est un néologisme un peu barbare qui désigne une attitude favorable à l’acte d’apprendre de toutes les situations (formelles ou informelles) et circonstances (accidents, erreurs…) et de toutes les façons, tandis que l’apprentissage est un processus de construction et d’appropriation des connaissances . Le lien entre l’apprenance et les professionnels de l’information m’apparaît assez évident : ces derniers, qu’ils soient veilleurs ou knowledge managers, par goût et par opportunisme, saisissent les moindres occasions d’apprendre et ont à cœur de créer les conditions pour que leurs collaborateurs en fassent autant.
La rencontre (plutôt fortuite lors de ces journées d’étude) de ces deux chercheurs et penseurs, sous le haut patronage de Michel Serres pour l’un et d’Edgar Morin pour l’autre, semble pourtant couler de source tant les deux philosophes « tutélaires » se rejoignent dans une approche transversale et interdisciplinaire qui aide, possiblement, à penser la veille autant que le knowledge management.
L’héritier de Michel Serres, Olivier Hamant, va chercher dans la biologie et le vivant des exemples de robustesse – l’arbre, la photosynthèse, les réseaux moléculaires – qui contrecarrent la course à la performance qui régit ordinairement la société, et les micro-sociétés que constituent les entreprises.
Les arbres sont un exemple criant de non-performance, eux qui, à l’automne, gâchent leurs feuilles dont ils font un don généreux à l’écosystème… Personne ne peut pour autant remettre en question la robustesse des arbres qui voient passer des générations d’hommes sous leur frondaison. Le phénomène de la photosynthèse, quant à lui, s’il affiche un rendement le plus souvent inférieur à 1 % (les plantes gâchant, autrement dit, 99 % de l’énergie solaire…), nourrit pourtant la totalité des écosystèmes terrestres depuis plus de 3 milliards d’années et ce gaspillage lui est nécessaire pour gérer les fluctuations lumineuses.
Les contradictions entre les molécules induisent, de leur côté, selon le biologiste, des comportements oscillants qui garantissent la stabilité à long terme. La contradiction par les pairs n’est-elle pas, sur le même modèle, constitutive de la publication des résultats scientifiques ? La quête obsessionnelle de l’optimisation et de la cohérence, en voulant aplanir les contradictions, éteint le débat et pourrait bien finir par créer à terme de l’ignorance selon Olivier Hamant. Le même va jusqu’à inciter les organisations à réaliser leur audit interne de robustesse en recensant toutes les non-performances et en se demandant dans quelle mesure elles ne nourriraient pas justement la robustesse. Par exemple, les pauses café et autres moments d’échanges informels n’ont-ils pas la vertu de conforter le lien social ? Les délais les plus fiables proposés à ses clients ne seraient-ils pas plus profitables à terme que les délais les plus courts ?
Si les êtres vivants sont robustes avant d’être performants, sans doute avons-nous intérêt, pour pérenniser les dispositifs, notamment informationnels, que nous cherchons à mettre en place, à rechercher la robustesse avant la performance, puisqu’un système robuste reste stable sur le court terme et viable sur le long terme malgré les fluctuations – tandis qu’une logique de performance épuise les ressources et ne peut pas durer très longtemps (se doit d’être performant un athlète de haut niveau pendant une épreuve sportive ou un pompier qui intervient en urgence sur un sinistre). Le vivant oscille, vit de ses contradictions et de ses incohérences, de désaccords féconds (qu’Olivier Hamant qualifie plaisamment de « robustesse démocratique »).
La première proposition contre-intuitive réside ainsi dans la réhabilitation, avec la robustesse, de l’incohérence, de la contradiction, de l’hétérogénéité et de la redondance, plus à même de nous aider à faire face à un monde fluctuant que la sacro-sainte performance. Ceci, transposé dans un contexte d’informations et de connaissances, nous incite à lever le pied sur les indicateurs de performance censés évaluer la solidité des démarches que nous mettons en œuvre.
Pour filer l’analogie biologique, à considérer notre corps humain comme un archipel, chaque cellule en constitue un îlot. La membrane poreuse qui lie entre eux les îlots aide notre corps à supporter les fluctuations. Dans l’entreprise archipel, tissu vivant aux cellules interconnectées, qui échangent des services et de la matière, c’est davantage la pluralité des mailles que la solidité du fil qui fait la robustesse du « pull-entreprise » : ce sont les îlots en redondance qui font la robustesse de l’organisation, c’est-à-dire les autres, là pour aider : l’arbre, pour y revenir, offre, lui aussi, beaucoup de redondances avec la multitude de ses feuilles et de ses branches. Un indicateur de robustesse sera ainsi le nombre de sollicitations des autres, sur le mode « j’ai besoin d’aide » (moyen de mesurer le niveau de coopération plutôt que d’encourager la compétition).
Ceci peut inciter un knowledge manager à chercher à créer des conditions d’entraide et des lieux de contradiction par les pairs (des communautés de pratique par exemple) pour faire collectivement disparaître les problèmes plutôt que de les faire résoudre par un expert technique providentiel à la place de ceux qui les rencontrent.
LIRE AUSSI :
Représentations et expressions du knowledge management : que disent les praticiens ?, Bases N° 437 - juin 2025
La veille collaborative à l'épreuve du réel : retours d'expériences et leçons apprises, Bases N° 436 - mai 2025
Quelles perspectives pour le veilleur à l'heure des pratiques prédatrices de son temps et de son attention ?, Bases N° 435 - avril 2025

Déjà abonné ? Connectez-vous...
Avec les artefacts de Claude, transformez vos idées en applications, outils ou contenus partageables

En 2026, chacun a désormais conscience que les outils d’intelligence artificielle générative ne sont pas de simples chatbots répondant à des questions, mais qu’ils intègrent toujours plus de fonctionnalités les transformant en véritables outils de production ou de collaboration. Dans les colonnes de NETSOURCES ou de BASES, de précédents articles ont déjà présenté et expliqué ce qu’étaient par exemple le Deep Research, le Context Engineering ou encore les espaces de travail persistants présents chez tous les grands acteurs du domaine.
Mais ces fonctionnalités ou outils supplémentaires sont plus ou moins visibles depuis la page d’accueil ; elles sont parfois tellement intégrées nativement qu’on peine à repérer leur existence. C’est le cas des artefacts de Claude, qui changent sensiblement le rapport au travail sur l’information, et auxquels nous consacrons cet article.
Qu’est-ce qu’un artefact ?
Situé dans l’environnement conversationnel de claude.ai, l’artefact va cependant bien au-delà de la simple réponse textuelle ; il produit dans une fenêtre dédiée sur la droite de l’écran (*), un livrable autonome, résultat du prompt envoyé dans la fenêtre de conversation qui s’affiche alors à gauche : il peut s’agir d’un document complexe et structuré, d’un diagramme, d’un extrait de code, d’un composant web, d’une application…
(*) Cette fenêtre est aussi désignée par canevas (canvas en anglais), que l’on peut rapprocher du canevas de ChatGPT, - panneau latéral qui affiche un rendu interactif séparé de la conversation -, même si les philosophies sont différentes, Claude penchant vers l’applicatif, ChatGPT Canvas vers l’éditorial.
Ce qui caractérise la production d’un artefact est qu’il est conçu dans un environnement pleinement interactif : l’utilisateur peut demander des modifications par itérations successives et voir l’évolution du livrable en temps réel dans la fenêtre de droite. Les artefacts constituent donc un espace de création de livrables en langage naturel.
Apparus dès l’été 2024 avec le modèle 3.5 Sonnet, les artefacts sont restés assez longtemps discrets. C’est près d’un an plus tard, en juin 2025, qu’ils ont bénéficié d’un espace dédié (claude.ai/artifacts), avec galerie de modèles préformatés et partage public possible des artefacts créés par un utilisateur.
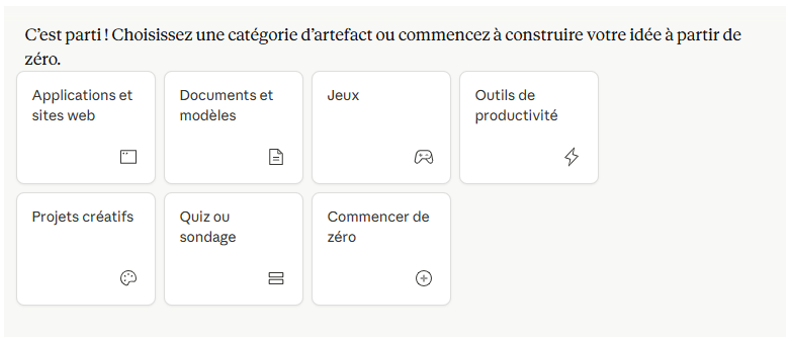
Catégories de modèles d’artefacts disponibles
LIRE AUSSI :
Le context engineering : orchestrer l'information pour les agents IA, Netsources N° 179 - novembre/décembre 2025
Deep Research : l'âge de raison des IA ?, Netsources N° 175 - mars/avril 2025
Le guide pratique du Deep Research, Netsources N° 176 - mai/juin 2025
Des espaces de travail persistants aux agents autonomes : des IA aux fonctionnalités multiples, Netsources N° 181 - mars/avril 2026
Déjà abonné ? Connectez-vous...
Montée en puissance de la lutte contre les articles scientifiques frauduleux

Clear Skies et IEEE viennent d’annoncer le renforcement de leur coopération dans la détection d’articles scientifiques frauduleux. IEEE est un éditeur de premier plan : il publie près d’un tiers de la littérature scientifique mondiale dans les domaines de l’ingénierie électrique, de l’informatique et de l’électronique. Ce nouvel accord vise à intégrer directement le produit Oversight de Clear Skies dans le processus éditorial d’IEEE. D’une durée de trois ans, cet accord porte sur l’évaluation d’un volume pouvant atteindre un million d’articles.
Un phénomène en pleine expansion : les paper mills
Cette démarche de vérification s’avère de plus en plus nécessaire face au développement des paper mills - ces organisations qui maximisent leurs profits en produisant industriellement des articles de recherche de piètre qualité. Vendus à des chercheurs en mal de publications, ces articles permettent à ces chercheurs d’augmenter artificiellement leur notoriété académique. Les avancées récentes de l’IA n’ont fait qu’amplifier ce phénomène en facilitant la production de contenu à grande échelle.
Il convient toutefois de ne pas réduire le problème aux seuls paper mills : les fraudeurs individuels constituent une catégorie non négligeable et tout aussi préoccupante.
Des outils de signalement a posteriori
La réalité des articles frauduleux est documentée depuis longtemps. Retraction Watch, blog créé en 2010 et désormais intégré à Crossref, recense à ce jour plus de 64 000 articles rétractés, en indiquant à chaque fois le motif de la rétractation (plus de 110 motifs différents sont répertoriés), ainsi que le nom de la revue et ceux des auteurs. Cette base est alimentée par le suivi des rétractations dans différentes banques de données et par des signalements de divers spécialistes. Entre 1 000 et 1 500 articles sont ajoutés chaque mois.
Il faut néanmoins souligner que tous les articles rétractés ne sont pas le fruit d’une fraude ou d’une mauvaise conduite : lorsqu’une équipe ne parvient pas à reproduire ses propres résultats, il est tout à fait légitime qu’elle procède à une rétractation.
On estime généralement que 3 % de l’ensemble des articles publiés mériteraient d’être rétractés. Adam Day, fondateur de Clear Skies, cite cependant un taux dix fois inférieur, ce qui signifie que la détection d’articles suspects revient à chercher une aiguille dans une botte de foin, même si, en valeur absolue, le nombre d’articles suspects n’est pas négligeable.
PubPeer joue également un rôle d’alerte : les commentaires qui y sont publiés, parfois anonymement et plus ou moins étayés, concernent des articles scientifiques. Ils déclenchent souvent des investigations complémentaires pouvant aboutir à la preuve d'une fraude ou d'une mauvaise conduite.
LIRE AUSSI
Fraudes et plagiats dans la recherche scientifique, Bases N° 329 - sept 2015
Le danger des articles de recherche médicale frauduleux, Bases N° 436 - mai 2025
Les articles rétractés sont très peu signalés dans les archives ouvertes - Blog en accès libre
Déjà abonné ? Connectez-vous...
Révision de la directive DAMUN : entre attentes et craintes

Philippe MASSERON, Directeur Général du gf2i et ancien directeur du Centre Français d’exploitation du droit de Copie (CFC)
La Commission européenne révise actuellement de la directive 2019/790 sur le droit d’auteur et les droits voisins dans le marché unique numérique, dite « directive DAMUN » (1). Prévu par la directive elle-même (2), ce travail intervient dans le contexte de tensions entre titulaires de droits et acteurs de l’IA.
Instaurée pour adapter le droit d’auteur à l’économie numérique, la directive avait notamment introduit des exceptions de fouille de textes et de données, aujourd’hui au cœur des enjeux liés à l’IA.
Après consultation des États membres en mars dernier, la Commission européenne a ouvert deux initiatives à dix jours d’intervalle : une enquête (3) visant à recueillir des informations sur l’application et les impacts de la directive, et un appel à contribution (4) portant sur une éventuelle modification ciblée du cadre européen du droit d’auteur. Ces travaux doivent permettre à la Commission d’évaluer l’efficacité de la directive de 2019.
Une vision utilitariste du droit d’auteur
La directive DAMUN est le second texte européen à traiter de manière globale le droit d’auteur et les droits voisins. Elle est en effet venue compléter la directive 2001/29 (5) dite « directive INFOSOC » qui traduisait elle-même en droit les orientations du Livre vert de la Commission de 1995 sur le droit d’auteur et les droits voisins dans la société de l’information (6).
Ce texte de 2001, premier à présenter cette vision globale du droit d’auteur et droits voisins, avait consacré une approche utilitariste : le droit d’auteur et les droits voisins y sont avant tout des outils économiques destinés à favoriser l’investissement autant que la création. La Commission a ainsi adopté une logique d’équilibre permanent entre titulaires de droits et utilisateurs, qui s’est traduite par une multiplication des exceptions au droit exclusif (7) et leur imposition (8) progressive aux États membres.
On se souviendra que dans son projet de directive (9) en 2016, la Commission plaçait l’adaptation aux « nouveaux comportements des consommateurs » avant l’amélioration du sort des auteurs. Les discussions avaient donné lieu à de vives tensions entre plateformes technologiques et ayants droit.
LIRE AUSSI
IA générative et contenus protégés : vers un rééquilibrage mondial du rapport de force ?, Bases N° 446 - avril 2026
IA générative et droit d'auteur : premières décisions et ligne de fracture (2ème partie), Bases N° 445 - mars 2026
IA générative et droit d'auteur : la bataille pour la qualification juridique de l'entraînement (1re partie), Bases N° 444 - fev 2026
La France s'attaque au vol de contenus par les IA génératives, Bases N° 443 - janvier 2026
Le droit d'auteur face à l'IA générative : interview de Philippe Masseron (gf2i) sur les enjeux juridiques et économiques des métiers de l'information et de la donnée, Bases N° 425 - mai 2024
Déjà abonné ? Connectez-vous...
Quand les LLM disent « limite atteinte » : comprendre et maîtriser ses quotas d’IA
Quoi de plus frustrant, et de plus improductif ! que de se retrouver bloqué par un message « limite atteinte », y compris sur un abonnement payant. Ce n’est pas un dysfonctionnement : c’est le signe que la mécanique sous-jacente reste opaque – et c’est précisément ce que cet article se propose de déchiffrer.
Tokens, GPU, énergie : ce que cache la facturation
Derrière chaque requête se cache un coût physique réel (GPU, énergie, mémoire) - c’est ce coût qui explique les plafonds. L’unité de mesure en est le token : environ les trois quarts d’un mot anglais, unité dans laquelle le modèle découpe tout ce qu’il reçoit et génère. Un résumé court en mobilise quelques centaines ; l’analyse d’un corpus, plusieurs dizaines de milliers.
Les abonnements payants n’achètent pas des messages illimités, mais une enveloppe de ressources gérée par fenêtres glissantes (*) – des périodes mobiles de quelques heures durant lesquelles la consommation est mesurée en continu, sans remise à zéro à heure fixe.
(*) De l’ordre de 3 à 5 heures selon les plateformes.
Payant ne veut pas dire illimité
Le plan gratuit est limité aux modèles légers : quota épuisé en quelques dizaines d’échanges par jour.
L’abonnement payant (~20 $/mois) donne accès aux modèles puissants, aux agents, au raisonnement avancé et aux uploads - mais il n’est pas illimité pour autant :
- ChatGPT Plus : accès illimité à GPT-5 Instant (usage courant) ; accès limité à GPT-5 Thinking (raisonnement avancé), soumis à des fenêtres glissantes.
- Claude et Gemini : même principe : accès étendu sur les modèles courants, plafonds stricts sur les modèles coûteux.
- Fonctionnalités coûteuses (agents, thinking) : limites hebdomadaires spécifiques.
LIRE AUSSI
Le context engineering : orchestrer l'information pour les agents IA, Netsources N°179 - nov - dec 2025
Le prompt, un art pour la veille stratégique et la recherche d'information (dossier en deux parties), Netsources N°177 - juil - août 2025 et N°178 - sept-oct 2025
Les hausses tarifaires des modèles : vers une intelligence artificielle à deux vitesses ?, Bases N°437 - juin 2025
Déjà abonné ? Connectez-vous...
La veille brevet comme outil de souveraineté : l’exemple taïwanais

Taïwan est bien plus qu’un point de tension géopolitique. Malgré sa petite taille, l’île figure parmi les acteurs majeurs du brevet mondial et sa pratique de la veille technologique mérite l’attention des professionnels de l’information. Un rapport récent de l’Office taïwanais de la Propriété Intellectuelle (TIPO) sur les systèmes de propulsion des drones en offre une illustration concrète : méthodologie rigoureuse, visée opérationnelle immédiate, ancrage dans les enjeux d’indépendance technologique.
À l'heure où la souveraineté technologique est devenue une priorité, ce rapport taïwanais montre ce que peut être une veille brevet vraiment au service de la stratégie.
Taïwan, un acteur à suivre dans le monde du brevet
Malgré sa petite taille (36 200 km2, 24 millions d’habitants), Taïwan occupe une place de premier plan dans le monde du brevet. Le TIPO a reçu en 2025 51 000 demandes de brevet, à mettre en perspective avec les 16 800 demandes nationales françaises reçues par l’INPI la même année (chiffre OMPI), la France étant un pays quasi 3 fois plus peuplé que Taiwan.
L’objet du rapport du TIPO : les drones, un sujet hautement stratégique
Les drones, d’abord utilisés pour la reconnaissance militaire, se sont rapidement diffusés dans de nombreux domaines : applications commerciales, industrielles, agricoles, logistiques, télécommunications ou encore loisirs. Leur diversité de formats, de capacités et de missions en fait aujourd’hui un moteur de transformation industrielle et sociétale. Toutefois, leurs performances (autonomie, capacité d’emport, adaptation à l’environnement, efficacité des missions) dépendent avant tout de leur élément central : le système de propulsion.
Une vision de la veille technologique très opérationnelle
Ce rapport ne se limite pas à cartographier le paysage des brevets, car il ne s’agit pas ici seulement de dresser un état des lieux sur un sujet donné, d’analyser le paysage des brevets, d’explorer les trajectoires technologiques, avec les principaux acteurs et leurs forces et faiblesses.
En effet, il formule des préconisations. des préconisations concrètes pour renforcer l’indépendance technologique de Taïwan sur un sujet directement lié à sa défense. La visée est donc explicitement opérationnelle. Une section couvre les politiques des principaux pays actifs (Taïwan, États-Unis, UE, Japon, Corée du Sud, Chine continentale), avec pour chaque zone les principales entreprises actives sur le secteur, indépendamment de leur politique brevet. Autre originalité : 25 pages sur 200 sont consacrées aux bases scientifiques et techniques des systèmes de propulsion, ce que l’on rencontre rarement dans les rapports produits de ce côté-ci de la planète, et qui rend le document accessible aux non-spécialistes du domaine.
La méthodologie : une rigueur documentée pas à pas
Un chapitre très détaillé est consacré au cheminement qui conduit à la stratégie de recherche, qui est traditionnelle, c’est-à-dire basée sur des mots-clés et des codes de classification. Ce cheminement commence par la définition de 7 catégories et 13 sous-catégories techniques (figure 1).
La recherche est effectuée sur la base de données interne du TIPO (GPSS pour Global Patent Search System, 以全球專利檢索系統) et sur Derwent Innovation ; elle est limitée aux demandes de brevet déposées jusqu’au 31 mai 2025.
Déjà abonné ? Connectez-vous...
Quels usages de l’IA à la bibliothèque de Sciences Po ? Témoignage de Caroline Maufroid, iconographe

Interview menée par Christel RONSIN
Caroline Maufroid, iconographe à la bibliothèque de Sciences Po, partage son expérience de l’intégration de l’intelligence artificielle générative (IAG) dans la gestion des fonds documentaires audiovisuels. Entre limites techniques et défis juridiques, son témoignage éclaire les écueils et les opportunités d’une technologie en pleine évolution.
Titulaire du diplôme d’ingénierie documentaire de l’INTD, Caroline Maufroid est spécialisée dans le domaine audiovisuel. 11 ans d’expérience dans les agences photo AKG, REA et la Collection lui ont permis d’acquérir la rigueur nécessaire à la gestion documentaire et informatique d’un important flux d’images et de vidéos. Depuis 11 ans, elle est iconographe et administratrice de la Banque d’images de Sciences Po qu’elle a mise en place.
CHRISTEL RONSIN : Caroline, depuis quand utilisez-vous l’IA à la bibliothèque, et pour quelles activités ?
CAROLINE MAUFROID : Dès 2019 nous en utilisions déjà ! À l’époque, notre système de gestion des actifs numériques (DAM), développé avec l’éditeur Einden, intégrait Google Vision. Cet outil permettait une indexation automatique des mots-clés par reconnaissance visuelle, ainsi qu’un module de reconnaissance faciale et une fonction de transcription audio (speech-to-text) pour les vidéos. Les résultats n’étaient cependant pas à la hauteur de nos attentes.
Ces modèles d’IA, non adaptés au fonds spécifique de Sciences Po - principalement des captations de conférences -, peinaient à traiter des discours complexes avec des accents marqués, un vocabulaire technique pointu et une multitude de noms propres. La qualité était comparable à celle des sous-titres automatiques de YouTube !
©Caroline Maufroid/Sciences Po
De même, la description automatique des images s’avérait peu pertinente. Notre fonds, très homogène (photos de cours, de conférences et portraits), posait problème : Google Vision réduisait par exemple un portrait à des termes génériques comme « cravate, sourire, lunettes », alors que nous avions besoin du nom du chercheur et de son laboratoire. Le décalage entre nos exigences de précision contextuelle et les résultats proposés était trop important, nous avons donc abandonné ces fonctionnalités. Aujourd’hui, nous sommes en attente des nouveautés de notre éditeur pour le printemps 2026, qui s’annoncent prometteuses.
CR : Utilisez-vous d’autres outils d’IA dans votre travail ?
CM : Oui, notamment pour la documentation audiovisuelle. J’utilise régulièrement Google Lens pour identifier des éléments dans nos fonds photo. Par exemple, pour des voyages d’étudiants dans l’Union Européenne, où les images ne sont pas légendées, cet outil me permet de reconnaître des bâtiments ou des lieux grâce à la reconnaissance visuelle. Cela nous fait gagner un temps précieux, Google Lens évite ainsi des lacunes dans l’indexation. Cela me permet aussi de retrouver des publications anciennes d’images sur le web quand il faut rechercher des crédits photo.
Par ailleurs, depuis deux ans, Sciences Po dispose d’une plateforme de valorisation de notre contenu éditorial, incluant articles, podcast et conférences vidéo. Ce portail, ouvert au grand public depuis quelques mois, existe en deux versions : Conférence (1) dédiée à l’actualité, et Sources (2) qui est à dimension pédagogique. Pour les transcriptions automatiques, Sources utilise Whisper, un outil OpenAI, tandis que Gemini génère les chapitres, les mots-clés et les résumés des conférences.
Cependant, nous ne l’appliquons pas systématiquement à l’ensemble de notre fonds, car l’utilisation de ces IAG a un coût, nous sélectionnons donc les contenus prioritaires.
Déjà abonné ? Connectez-vous...
IA générative et contenus protégés : vers un rééquilibrage mondial du rapport de force ?

Depuis mars, plusieurs pays tentent un rééquilibrage de leurs politiques en faveur des titulaires de droits vis-à-vis de l’IA générative. Trois axes communs se dessinent : transparence sur les corpus d’entraînement, mécanismes de licence, rémunération des ayants droit.
Le Royaume-Uni renonce à l’exception TDM (Text and Data Mining)
Le Gouvernement britannique réfléchissait depuis 2021 à rapprocher sa loi sur le copyright du droit européen par l’instauration d’une exception pour le TDM commercial. Cette exception aurait permis aux acteurs de l’IA d’entraîner licitement leurs modèles avec des œuvres protégées sans autorisation ni rémunération des ayants droit.
Le 6 mars, la Commission numérique et communications de la Chambre des lords avait envoyé un message ferme via : rapport sur le droit d’auteur et les industries créatives. Les lords exhortaient le Gouvernement à ne pas affaiblir le droit d’auteur, recommandant au contraire de renforcer la transparence et les mécanismes de licence.
Le 19 mars, le Gouvernement a tranché (1) par une position radicale : abandon du projet d’exception ! Un signal politique fort alors que le Royaume-Uni apparaissait jusqu’alors très favorable aux acteurs de l’IA.
Le Parlement européen veut la rémunération des titulaires de droit d’auteur par les acteurs de l’IA
Il faudra se souvenir du 10 mars 2026 et de l’adoption très nette (460 voix pour, 71 contre et 88 abstentions) du rapport porté par le député Axel VOSS(2) dans le cadre de la commission des affaires juridiques (JURI).
Le Parlement y affirme sa détermination à faire respecter le droit d’auteur et appelle la Commission à travailler dans ce sens.
Le texte insiste sur la nécessité de renforcer la transparence et de créer un marché des licences, notamment via des accords volontaires collectifs, répondant ainsi aux demandes répétées des ayants droit qui dénoncent le pillage de leurs œuvres par les acteurs de l’IA. Le rapport propose également l’adoption d’un dispositif de présomption d’utilisation d’œuvres protégées par les fournisseurs d’IA calqué sur le mécanisme étudié en France (voir plus bas), ce qui renverserait la charge de la preuve.
Nul doute que la Commission européenne, en phase d’évaluation et d’éventuelle révision de la directive 2019/790 sur le droit d’auteur(3), devra prendre en compte cette mobilisation des députés.
Déjà abonné ? Connectez-vous...
Publicité, vecteurs émotionnels, transmission silencieuse : trois risques invisibles dans votre évaluation des LLMs

Les professionnels de l’information ont largement dépassé le stade des benchmarks. Ils évaluent aujourd’hui les LLMs de manière plus intuitive : cohérence sur la durée, sensation de neutralité, fiabilité perçue, absence de bizarreries récurrentes. Pourtant, trois phénomènes structurels influencent fortement la qualité réelle des réponses, sans être visibles à l’œil nu.
Ces angles morts prolongent la réflexion engagée dans notre précédent article sur l’alignement éthique : aux règles explicites imposées aux modèles s’ajoutent des forces plus profondes, économiques, internes et héritées.
Lire aussi : LLM : l’alignement éthique, le critère qu’on oublie d’évaluer – BASES nᵒ 444 (en accès libre)
Le business model : une influence économique qui émerge
OpenAI a lancé sa régie publicitaire en février 2026, d’abord aux États-Unis, et a rapidement généré plus de 100 millions de dollars de revenus annualisés, avec des projections de plusieurs milliards par an, malgré des pertes attendues de 14 milliards cette année.
Impact concret : dans une réponse conversationnelle, il n’existe aucune séparation claire entre contenu neutre et contenu influencé : la recommandation publicitaire est fondue dans le texte, sans label détachable.
Le précédent Google Search est parlant : perçu à l’origine comme un outil de classement neutre, il a progressivement intégré la publicité jusqu’à rendre difficile la distinction entre résultats sponsorisés et organiques. Avec les LLMs, le risque est identique, mais plus insidieux.
À l’opposé, Anthropic a affirmé publiquement que Claude resterait sans publicité, en en faisant le thème de sa première campagne Super Bowl. Perplexity confirme la viabilité économique de ce choix : 500 millions de dollars d’ARR (chiffre d’affaires annuel récurrent) avec un abonnement professionnel à 200 $/mois, sans publicité. Il semblerait qu'il n'y ait pas non plus de publicité dans l'abonnement Pro à 20 $/mois.
Les vecteurs émotionnels internes : le modèle peut « être » dans une disposition qui modifie son comportement sans que vous le remarquiez
En avril 2026, l’équipe d’interprétabilité d’Anthropic a identifié 171 vecteurs émotionnels internes dans Claude Sonnet 4.5.
Un vecteur émotionnel est un schéma d’activation mesurable dans les couches du réseau de neurones, associé à un concept précis : «calme», «désespoir», «défiance». Ces vecteurs sont mesurables par les équipes de recherche via l’analyse interne des activations du modèle, mais pas par l’utilisateur ordinaire. En revanche, c’est bien le contexte de la conversation qui les active : chaque mot, chaque ton du prompt guide involontairement le modèle vers un état interne particulier, comme l’humeur d’une personne influencée par l’ambiance.
Déjà abonné ? Connectez-vous...
Presse d’investigation en France : une offre foisonnante, un accès de plus en plus fragmenté

Le journalisme d’investigation n’a jamais été aussi productif. Pourtant, pour les professionnels de la veille et de l’information, accéder à cette production de façon aisée et à un coût abordable est de plus en plus difficile. Multiplication des titres indépendants, abandon de la vente à l’article, modèles d’abonnement complexes : cet article dresse un état des lieux de ces obstacles et des initiatives qui tentent d’y répondre.
1. Un paysage éditorial en pleine expansion
Plusieurs facteurs convergent pour expliquer le dynamisme du journalisme d’investigation en France. La multiplication des affaires politiques et économiques portées sur la place publique, favorisée par la levée progressive de certains modes de protection bien établis, crée une demande forte d’informations/révélations. Cette intolérance croissante de l’opinion publique face aux dérives pousse un nombre grandissant de journalistes, professionnels comme amateurs, à mener des enquêtes et à en diffuser les résultats le plus largement possible.
Le développement des outils de publication en ligne comme en format papier a considérablement abaissé les barrières à l’entrée : il est désormais possible de lancer un média, certes avec des moyens limités, totalement indépendant des grands groupes de presse.
Cependant, sa distribution, payante ou gratuite, demeure un problème majeur en raison des coûts de promotion rapidement élévés.
Les coûts de fabrication au sens large n’étant pas nuls, certains titres en ligne ont décidé d’offrir le libre accès à leur publication sans obligation d’abonnement. A la place, ils sollicitent des dons, bien sûr sur une base volontaire, et il semblerait que ce système fonctionne.
LIRE AUSSI :
1.1 La presse libre et indépendante : un panorama fragmenté
On recense aujourd’hui plus d’une centaine de publications françaises indépendantes, avec une grande diversité thématique et éditoriale. Les principales catégories sont les suivantes avec quelques exemples :
- Investigation généraliste : Mediapart, Disclose
- Écologie : Reporterre, Vert
- Information généraliste à gauche : Politis, Le Média
- Information locale et régionale : Médiacités (Lille, Lyon, Nantes, Toulouse), Rue89 Strasbourg, Rue89 Lyon, Rue89 Bordeaux
- Information militante : Dijoncter, Rebellyon
Déjà abonné ? Connectez-vous...




















