
Traduction des posts d’A. Karparthy et de Tobi Lütke
Andrej Karpathy @karpathy
+1 pour « ingénierie de contexte » (context engineering) plutôt qu’« ingénierie de prompt » (prompt engineering).
Les gens associent les prompts à de courtes descriptions de tâches que l’on donnerait à un LLM dans un usage quotidien. Alors que dans toute application LLM de niveau industriel, l’ingénierie de contexte est l’art délicat et la science consistant à remplir la fenêtre de contexte avec exactement les bonnes informations pour l’étape suivante.
Une science, parce que bien faire les choses implique des descriptions de tâches et des explications, des exemples (few-shot), du RAG, des données liées (éventuellement multimodales), des outils, l’état et l’historique, de la compression... Trop peu d’informations ou une forme inadaptée, et le LLM n’a pas le bon contexte pour une performance optimale. Trop d’informations ou des données non pertinentes, et les coûts du LLM pourraient augmenter tandis que la performance pourrait baisser. Réussir cela est hautement complexe.
Et un art, en raison de l’intuition nécessaire autour de la « psychologie » des LLM.
En plus de l’ingénierie de contexte elle-même, une application LLM doit :
- découper les problèmes de la juste manière en flux de contrôle
- remplir les fenêtres de contexte de façon optimale
- répartir les appels vers des LLM du bon type et de la bonne capacité
- gérer les flux UI/UX de génération-vérification
- et bien plus encore - garde-fous, sécurité, évaluations, parallélisme, préchargement (prefetching)...
L’ingénierie de contexte n’est donc qu’une petite pièce d’une couche logicielle complexe et émergente qui coordonne les appels individuels aux LLM (et bien plus) pour en faire des applications complètes. Le terme « wrapper ChatGPT » (enveloppe ChatGPT) est épuisé et vraiment, vraiment faux.
[Citation du post de Tobi Lütke] tobi lutke @tobi · 19 juin J’aime beaucoup le terme « ingénierie de contexte » plutôt qu’ingénierie de prompt. Il décrit mieux la compétence de base : l’art de fournir tout le contexte nécessaire pour que la tâche puisse être résolue de manière plausible par le LLM.
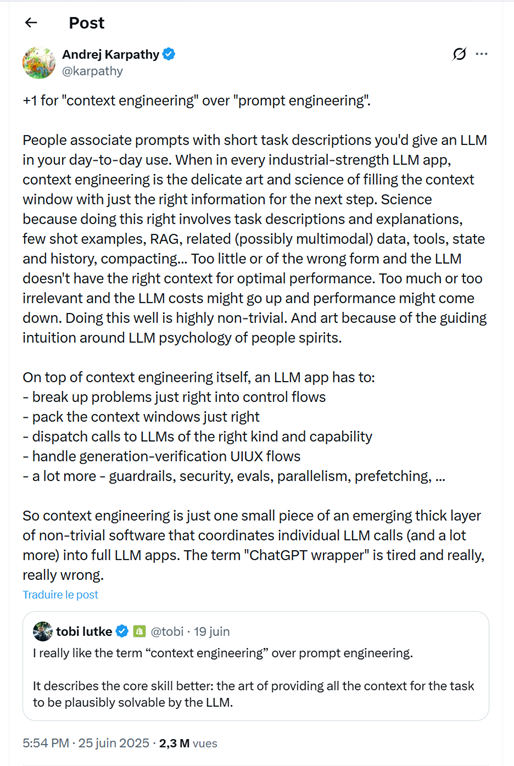
Fig.1 - Tweet d’Andrej Karpathy définissant le context engineering, en réponse à Tobi Lütke, CEO de Shopify (25 juin 2025) - posts directement traduits en français
Pour rappel, la fenêtre de contexte désigne la quantité d’information qu’un modèle de langage peut traiter simultanément. Elle se mesure en tokens , des unités de texte correspondant grossièrement à des fragments de mots. Tout ce que le modèle « voit » pour produire sa réponse doit tenir dans cette fenêtre.
Le context engineering consiste précisément à gérer cette fenêtre : décider quelles informations y inclure, dans quel ordre, sous quelle forme. On parle parfois de « budget d’attention » . Trop peu d’informations, et le modèle manque d’éléments pour répondre correctement. Trop d’informations, ou des informations mal organisées, et le modèle risque de se disperser. L’objectif est de minimiser le nombre de tokens tout en maximisant le signal utile à la tâche .
Plusieurs éléments peuvent constituer ce contexte ( cf. tableau ci-dessous et Fig.2 ). On distingue généralement :
|
Composante |
Description |
| Instructions système | Consignes de comportement définies par la plateforme (prompt système) ou l’utilisateur (instructions personnalisées) |
| Prompt utilisateur | La requête formulée par l’utilisateur |
| Historique | Les échanges précédents dans la conversation en cours (mémoire court-terme) |
| Mémoire | Informations retenues d’une conversation à l’autre (mémoire long-terme) |
| Documents | Fichiers ajoutés à la conversation ou injectés dynamiquement (système de RAG) |
| Outils | Fonctionnalités que le modèle peut utiliser (recherche web, code, etc.) |
| Format de sortie | Contraintes sur la structure de la réponse attendue |

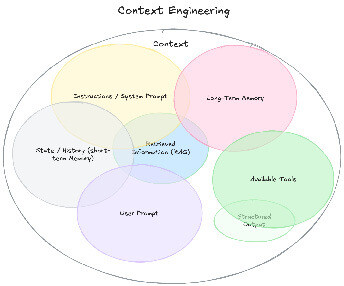
Fig.2 - Les différentes composantes du contexte alimentant un modèle de langage. Source : Philipp Schmid
Avec des tâches de plus en plus complexes, le volume d’informations potentiellement utiles dépasse souvent la capacité de la fenêtre. Il faut alors arbitrer : sélectionner ce qui est pertinent, écarter ce qui ne l’est pas. C’est le travail de « curation » qui est au cœur du context engineering .
Ces éléments sont assemblés dynamiquement à chaque requête au modèle. Certains sont gérés automatiquement par la plateforme, d’autres configurés par l’utilisateur. Les réponses de l’agent ainsi que les interactions avec les outils (recherche web, exécution de code), alimentent ensuite le contexte ( cf. Fig 3 ).

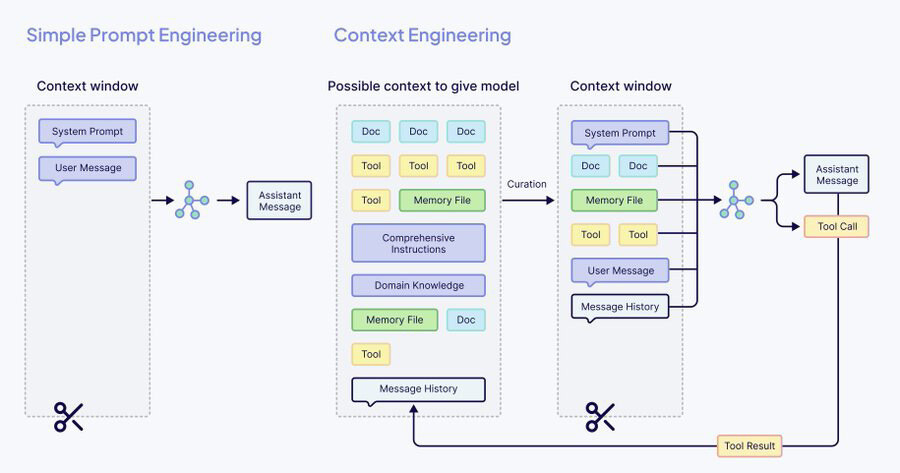
Fig.3 - Comparaison entre le prompt engineering et le context engineering. Source : Weaviate
Le context engineering dans les outils du quotidien
Bien que cela ne soit pas apparent au premier abord, les assistants IA (ChatGPT, Claude, Gemini…) que nous utilisons quotidiennement intègrent déjà des mécanismes de context engineering . Certains fonctionnent en arrière-plan, de manière automatique. D’autres sont accessibles et configurables par l’utilisateur.
Ce qui est géré automatiquement
Comme expliqué dans le dossier consacré au prompt engineering , l’historique de la conversation est inclus dans la fenêtre de contexte. C’est ce qui permet au modèle de fournir des réponses cohérentes tout au long d’un échange.
Dans le cas de conversations longues, cette accumulation pose un problème : le contexte risque de saturer la fenêtre disponible . D’autant que les nouvelles capacités des modèles (raisonnement, recherche web, utilisation d’outils) consomment elles-mêmes des tokens. Les plateformes appliquent alors des stratégies de compression : les échanges anciens sont résumés ou élagués automatiquement pour alléger l’historique fourni au modèle.
Par exemple, depuis peu dans Claude ( cf. Fig. 4 ), lorsqu’une conversation atteint sa limite, le modèle génère une synthèse des échanges précédents pour éviter à l’utilisateur de démarrer une nouvelle conversation. ChatGPT applique des mécanismes similaires, permettant de maintenir des conversations de plusieurs centaines de messages.


Fig.4 - Fonctionnalité de compression automatique du contexte dans Claude lorsqu’une conversation atteint la limite de la fenêtre de contexte
Un autre élément invisible pour l’utilisateur : le prompt système . Il s’agit des instructions intégrées par la plateforme qui définissent le comportement de base du chatbot. L’utilisateur n’y a généralement pas accès, mais elles font partie intégrante du contexte.
Ce que l’utilisateur peut configurer
Plusieurs éléments du contexte sont directement paramétrables.
- Instructions personnalisées : Chaque plateforme permet de définir des instructions qui s’appliquent à toutes les nouvelles conversations. Dans ChatGPT, ce sont des « Instructions personnalisées » ( cf. Fig.5 ). Claude propose des paramètres de « Style » ainsi que des instructions par projet. Ces instructions constituent un « pré-prompt » injecté automatiquement avant chaque message. Elles permettent d’adapter le comportement de l’assistant : préciser un domaine d’expertise, des préférences de format, des exigences sur les stratégies de recherche sur le web.
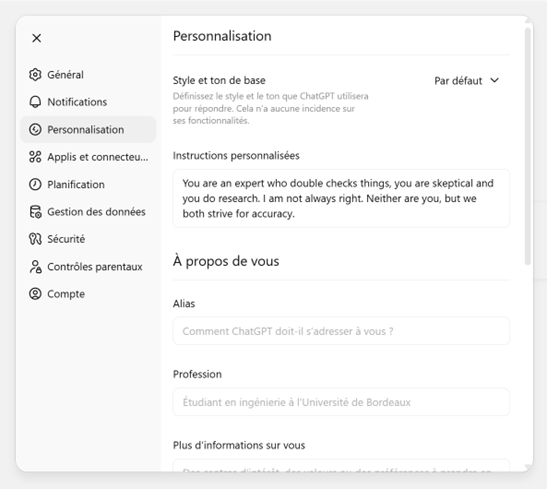
 Fig.5 -menu de ChatGPT permettant de définir des instructions personnalisées
Fig.5 -menu de ChatGPT permettant de définir des instructions personnalisées
- Ajout de documents : les assistants IA peuvent désormais exploiter une grande variété de fichiers : documents Word, présentations PowerPoint, tableurs Excel, PDF, images, captures d’écran, code. GPT-5.2 , annoncé en décembre 20254, illustre les progrès dans ce domaine. Sur le benchmark GDPVal , qui mesure la performance sur des tâches professionnelles réelles couvrant 44 métiers5, ce modèle atteint un score de 70,9 % (contre 38,8 % pour GPT-5), égalant ou dépassant des experts humains dans la majorité des cas .
- Mémoire : Aux débuts de ChatGPT, chaque nouvelle conversation repartait de zéro, l’assistant oubliant les échanges précédents. Aujourd’hui, plusieurs chatbots IA intègrent une mémoire persistante entre conversations.
Le fonctionnement diffère selon les plateformes. ChatGPT enregistre automatiquement des « souvenirs » et peut s’appuyer sur l’historique des conversations passées. Claude propose une mémoire visible et éditable, avec une mémoire générale et une mémoire séparée par projet. L’utilisateur peut consulter ce qui est mémorisé, corriger des erreurs, ou désactiver la fonctionnalité. Dans ChatGPT, ces paramètres se trouvent dans le menu Personnalisation - Mémoire ( cf. Fig.6 ).
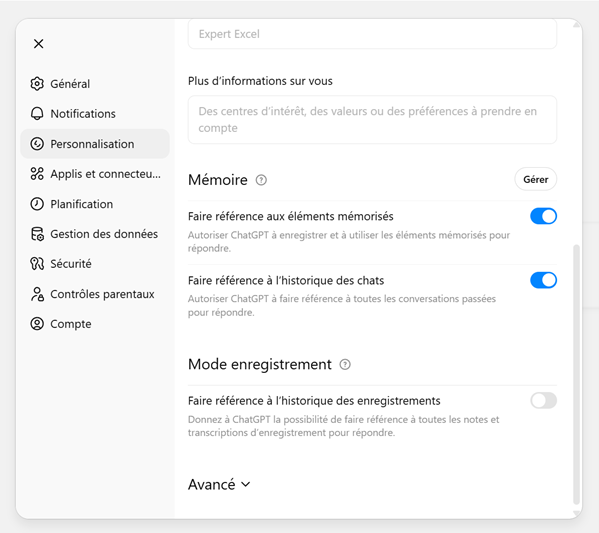
 Fig.6 - Paramètres de mémoire dans ChatGPT
Fig.6 - Paramètres de mémoire dans ChatGPT
- Connexion à des outils externes : les assistants peuvent se connecter à des applications tierces : Google Drive, emails, calendriers, contacts. Ces connexions étendent le contexte disponible au-delà des fichiers explicitement partagés ( cf. Fig.7 ). L’assistant peut aller chercher des informations dans ces sources pour enrichir ses réponses, à la manière du RAG ( Retrieval-Augmented Generation ).
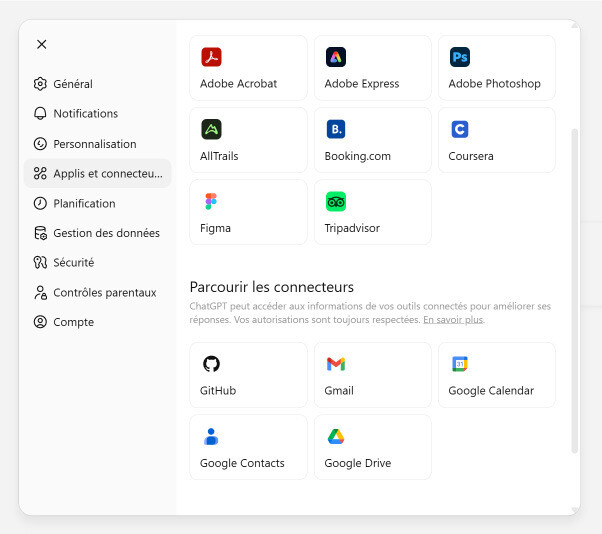
Fig.7 - Applications et connecteurs disponibles dans ChatGPT
Ce que l’on peut construire
- Assistants personnalisés : les GPTs personnalisés (ChatGPT), Gems (Gemini) et Projects (Claude) permettent de créer des assistants dédiés à un usage spécifique. Ces assistants combinent plusieurs des leviers décrits précédemment : instructions dédiées, documents de référence, outils disponibles, et parfois une mémoire isolée.
L’utilisateur définit un contexte complet, adapté à ses besoins. Cet assistant peut ensuite être réutilisé, partagé au sein d’une équipe, ou publié.
Les Capacités ( cf. Fig.8 ) : destinées initialement aux développeurs, Anthropic introduit en 20256 les « Skills » ( Capacités ) pour son assistant Claude. Les Capacités facilitent la création d’applications agentiques en assemblant un contexte structuré.
Une Capacité (à distinguer des artefacts ) contient : des instructions détaillées décrivant comment réaliser une tâche spécifique, des bonnes pratiques méthodologiques, des formats de sortie attendus, et éventuellement des fichiers de référence. Avant d’exécuter une tâche, l’agent consulte la Capacité correspondante pour charger le contexte approprié.
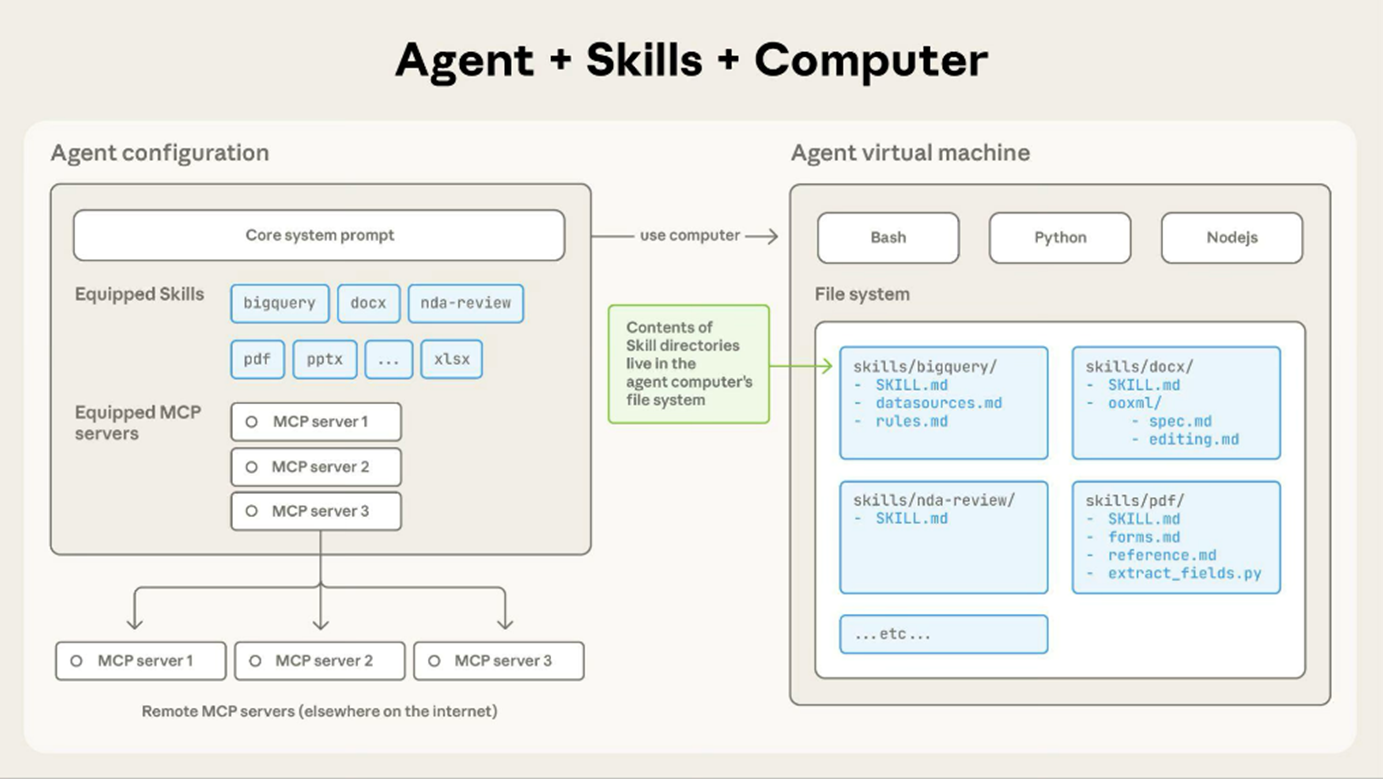
Fig.8 - Architecture des Skills (Capacités) dans Claude. Source : Anthropic
Cette approche permet de capitaliser un savoir-faire une fois, puis de le réutiliser systématiquement. Une Capacité « création d’une présentation PowerPoint » encode les conventions de mise en forme, la structure attendue, les règles typographiques. L’assistant les charge automatiquement lorsqu’il détecte ce type de tâche. À terme, les organisations pourraient constituer des bibliothèques de compétences formalisées, adaptées à leurs métiers, pour structurer le contexte fourni aux agents IA.
Les écueils d’un contexte mal maîtrisé
La qualité du contexte conditionne directement la qualité des réponses. Un contexte bien construit améliore la pertinence de l’assistant. Un contexte mal géré peut au contraire dégrader significativement ses performances.
Quatre types de problèmes sont couramment identifiés.
L’empoisonnement (Context Poisoning) : des informations incorrectes ou obsolètes entrent dans le contexte. Parce que les agents réutilisent ce contexte, ces erreurs persistent et se propagent d’une réponse à l’autre.
La distraction (Context Distraction) : trop d’informations passées encombrent le contexte. L’agent reproduit des schémas antérieurs plutôt que de raisonner sur la situation présente.
La confusion (Context Confusion) : des outils ou documents non pertinents encombrent le contexte, détournent l’attention du modèle et le conduisent à utiliser le mauvais outil ou les mauvaises instructions.
La collision (Context Clash) : le contexte contient des informations contradictoires. L’agent ne sait plus quelle directive suivre et produit des résultats incohérents ou erronés.
Au-delà de la qualité des réponses, ces mécanismes soulèvent des questions de confidentialité. Connecter une application externe (Google Drive, messagerie) rend potentiellement accessible son contenu au modèle. Un document malveillant pourrait contenir des instructions cachées (injection de prompt). Comprendre ce qui compose le contexte permet d’identifier ces risques : quelles données sont exposées, quelles connexions sont actives, quelles informations persistent d’une session à l’autre.
Notre avis
« La plupart des échecs des agents ne sont plus des échecs du modèle, mais des échecs de contexte. » Cette observation de Philipp Schmid7, de Google DeepMind, résume bien l’enjeu. Avec des modèles de plus en plus performants, c’est souvent la qualité du contexte qui fait la différence entre un résultat médiocre et un résultat réellement utile . C’est d’autant plus vrai pour les tâches longues, qui nécessitent de nombreuses itérations et où les erreurs liées au contexte se cumulent.
Le context engineering est une discipline jeune. Il semble néanmoins essentiel d’en comprendre les tenants et aboutissants. Quelles informations sont mémorisées ? Quelles sources sont connectées ? Quelles instructions s’appliquent par défaut ?
Le contexte n’est plus un détail technique réservé aux développeurs. Pendant longtemps, ces réglages étaient invisibles, cachés dans l’architecture des systèmes. Tout utilisateur qui prend le temps de l’explorer peut désormais voir ce qui alimente le modèle et agir dessus. Cela nous donne de nouveaux leviers de contrôle, et nous prépare aux usages de demain : des agents IA plus autonomes, dont la performance dépendra étroitement de la qualité du contexte que l’on aura construit.
Sources
- https://time.com/6272103/ai-prompt-engineer-job/
- https://www.bases-netsources.com/articles-de-netsources/le-prompt-un-art-pour-la-veille-strategique-et-la-recherche-d-information-dossier-netsources-en-deux-parties
- https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
- https://openai.com/fr-FR/index/introducing-gpt-5-2/
- https://openai.com/fr-FR/index/gdpval/
- https://claude.com/blog/skills
- https://www.philschmid.de/context-engineering