Sélectionner le numéro de "Bases" à afficher
Les Business cases, une source d’information originale


Les Business cases sont une source originale d’information sur des problématiques d’entreprises, des questions de management ou d’éthique. Si, dans quelques cas, l’accès à ces études appliquées au milieu des affaires est réservé au monde universitaire (enseignants et étudiants), très souvent, leur accès peut être ouvert à d'autres publics. On recommandera dans tous les cas de bien vérifier les droits d'auteur et les exploitations possibles.
Selon les sources, il existerait de 14 000 à 16 000 Business Schools dans le monde et toutes utiliseraient les Business cases, en français, « analyse de rentabilité » comme outil pédagogique. On parle aussi parfois de Cases studies mais ce terme est aussi employé dans d’autres disciplines, en particulier dans le monde médical.
Ces Business cases sont nés à la Harvard Business School dans les années 1920. Ils ont été créés par analogie avec les études de cas qui se pratiquaient à la Harvard Law School à partir des décisions rendues par les tribunaux. Dès l’année 1924, cet outil pédagogique a été largement utilisé à la Harvard Business School et s’est répandu dans le monde entier, même si l’on voit apparaître quelques remises en cause de cet outil.
Une démarche pédagogique spécifique
L’utilisation des Business cases est une démarche pédagogique radicalement différente de celle d’un cours ou d’une conférence traditionnelle au cours desquels un professeur/conférencier délivre une série d’informations, ce qui est en général, une communication dans un seul sens.
Les Business cases décrivent, dans la quasi-totalité des cas, des situations réelles, ce qui fait leur intérêt. Il s’agit de demander aux étudiants de réfléchir à une problématique de management à partir de situations réelles décrites.
L’utilisation d’un Business case permet une communication dans les deux sens. En général, elle comporte trois phases :
- Dans la première phase, chaque étudiant lit le cas qui comporte de 8 à 20 pages avec des annexes, en particulier financières et historiques.
- Ensuite des petits groupes d’étudiants échangent entre eux pour définir différentes actions stratégiques possibles en prenant le rôle d’un manager qui prend des décisions à partir d’informations incomplètes comme cela est fréquemment le cas dans la vie réelle.
- Enfin, l’ensemble des étudiants « chaperonnés » par leur enseignant, débattent des stratégies possibles.
D’autres approches existent aussi, par exemple à l’EM-Lyon, où c’est l’enseignant qui délivre les informations du cas. Les réactions/propositions des étudiants servent ensuite à la discussion du cas et pour leur évaluation.
Signalons aussi que l’INSEAD propose des scénarios en réalité virtuelle ce qui est, évidemment, plus immersif. Nous nous intéressons ici à ces Business cases car ils proposent une information très riche.
Une démarche à détourner pour la recherche ?
Nous en proposons, en fait, une utilisation détournée en considérant que l’énoncé et le développé de ces cas constituent une source riche et originale à intégrer dans une démarche de recherche d’information.
On y trouve, en effet, très fréquemment, au moins lorsqu’il s’agit de cas d’entreprises, un historique de cette entreprise, des données financières ainsi que de très riches références bibliographiques. De nombreux cas sont aussi proposés concernant des problématiques, par exemple liées à l’éthique ou à la discrimination. Certains éditeurs sont, d’ailleurs, spécialisés sur des problématiques particulières.
Ces informations peuvent être particulièrement intéressantes quand on s’intéresse à un nouveau sujet ou à une nouvelle entreprise.

Déjà abonné ? Connectez-vous...
FOCUS IA : écrire avec l'assistance d'un outil d'IA

Même s’ils n’écrivent pas à votre place, les outils d’editing issus des IA génératives de texte peuvent être de précieux alliés pour titrer ou réécrire ses livrables. Parmi nos préférés, Headline Hero, Quillbot, Hemingway et TextCortex. À noter qu’ils sont tous à utiliser sur sa propre prose, et non à des fins de plagiat. Entre correction guidée et réécriture, ils proposent différents niveaux d’intervention. Voici les informations clés pour aider à choisir le plus pertinent pour soi.
Headline Hero, pour trouver le juste titre
HeadlineHero est le chouchou des rédactions américaines. Et même s’il est en anglais, il fonctionne aussi très bien en langue française.
Quelle que soit la nature du texte à titrer (analyse d’un livrable, revue de presse sous forme de newsletter, etc.), il suffit de se rendre sur le site internet, de copier un extrait de son texte sur l’espace réservé à cela (à droite de l’écran), choisir la longueur de son titre (le nombre de mots souhaité) et de cliquer sur Generate Headlines pour voir plusieurs propositions de titres apparaître à la place de son texte précédemment copié, qui s’est lui-même déplacé sous les titres (voir Figure 1).
Il est possible d’ajouter des paramètres, comme ajouter ou exclure certains mots, ou encore rédiger le titre sous forme de question ou de citation. Le but affiché : générer des titres qui convertissent. À noter, l’outil est non seulement gratuit, mais il ne requiert aucune inscription. Notre avis : HeadlineHero offre un excellent ratio simplicité d’utilisation/qualité. Et même si les titres ne sont pas parfaits, ils aident au moins à trouver celui qui nous satisfera !

Figure 1 : Dans ses paramètres, HeadlineHero propose de fixer le nombre de mots de ses articles, mais aussi d’inclure ou d’exclure des mots précis.
Quillbot, pour (ré)écrire comme un journaliste
En cas de doute sur un extrait dont la rédaction n’est pas satisfaisante, ou d’un (court) texte à rendre sans avoir le temps d’une dernière relecture, Quillbot est peut-être la solution. Venu des États-Unis, cet outil gratuit vient de se doter d’un onglet « French » qui permet aux francophones d’en profiter.
Déjà abonné ? Connectez-vous...
ARC Browser réinvente la navigation en ligne

Depuis quelques mois, un nouveau navigateur baptisé Arc est souvent évoqué comme une alternative à Chrome non seulement crédible, mais salutaire. Nous avons donc testé ce nouveau navigateur, accessible jusqu’alors à tous les utilisateurs de Mac, rejoints depuis ce mois-ci par les premiers utilisateurs de Windows PC inscrits sur liste d’attente. Spoiler : on a très vite oublié Chrome.
Le navigateur Arc a été créé par The Browser Company, une société américaine créée en 2019 qui réunit d’anciens salariés d’Instagram, Amazon, ou encore… Google Chrome. Josh Miller et Hursh Agrawal, de leur côté, avaient revendu une précédente startup à Facebook en 2014.
Comme beaucoup de professionnels de la veille, on a déjà testé de nombreux navigateurs, mais le nombre d’extensions utilisées sur Chrome uniquement ne rend pas le départ aisé. Or, c’est un premier frein important levé par Arc.
Basé sur Chromium, le navigateur développé et mis en open source par Chrome, Arc permet d’y retrouver toutes ses extensions (voir Figure 1).

Figure 1 : Le transfert des extensions sur Arc. On commence par choisir quatre extensions qui seront mises en avant.
Une interface épurée et bien rangée
La première impression après avoir installé son navigateur est celle de légèreté. C’est normal : l’interface et l’ergonomie sont justement pensées pour faciliter notre détox digitale.
Les premiers pas sont plutôt faciles. Exit la navigation en haut de l’écran. Ici, la navigation se fait dans une colonne latérale à gauche et non en haut de l’écran comme tous les autres navigateurs, mais on s’y fait vite (voir Figure 2). De plus, cette barre peut être masquée, ce qui permet de garder son attention sur l’écran.
La barre latérale inclut :
● Ses éléments de navigation : la barre de navigation, les sites et les extensions épinglés, des onglets ouverts et des dossiers qui regroupent plusieurs onglets.
● Une bibliothèque :
• Les Medias, par exemple les captures d’écran prises durant la navigation ;
• Les Downloads, c’est-à-dire les derniers téléchargements ;
• Les Easels (chevalets) & Notes, une sorte de tableau blanc, où l’on peut ranger ses notes, ses Medias, ses dessins, etc. ;
• Les Spaces, visualisés sous forme de colonnes ;
• Les Boosts, qui sont des sites consultés, dont on a personnalisé l’apparence ;
• Les Onglets archivés, dotés d’un moteur de recherche avec ses propres filtres.

Figure 2. Sur Arc, la navigation se fait sur la barre latérale de gauche. Et on peut opter pour une Split View qui permet de naviguer sur plusieurs pages en même temps.
De plus, la navigation est organisée différemment, à commencer par la possibilité de scinder son navigateur en différents Espaces (Spaces en anglais, le navigateur n’étant disponible que dans cette langue). Chaque espace de navigation permet de séparer ses activités pros et perso ou même ses différents projets. Un peu comme les bureaux multiples de Microsoft 11, mais en ligne et beaucoup plus ergonomique. Concernant l’exercice de la veille, c'est non seulement pratique pour travailler sans interférence sur différentes problématiques, mais on y trouve un gain d’attention insoupçonné.
Déjà abonné ? Connectez-vous...
Les sources qu’il faut savoir « mettre en veilleuse »

L’infobésité des sources est un défi de plus en plus difficile à gérer, pour un veilleur comme pour tout un chacun. L’une des pistes possibles pour en sortir passe par une méthode de « mise en veilleuse » basée sur l’intelligence des sources que nous développons dans cet article.
Les veilleurs, même s’ils s’appuient toujours sur une sélection de sources et qu’ils s’évertuent à extraire des signaux et du sens au milieu du brouhaha ambiant, n’échappent pas à l’infobésité actuelle.
Il y a toujours plus de sources potentiellement pertinentes, toujours plus de contenus pertinents et d’outils pour repérer ces sources et ces contenus. Sans compter que nombre de ces sources et outils rajoutent sans cesse de nouvelles contraintes techniques à prendre en compte, ce qui se révèle souvent chronophage.
Ainsi, malgré nos efforts pour revoir les processus et les sources régulièrement, une veille, quelle qu’elle soit, a vite fait de demander de plus en plus de temps, mois après mois et année après année sauf si le sujet qu’elle traite tombe en désuétude.
Et il y a toujours cette angoisse de passer à côté d’une information vraiment importante qui viendrait jeter le discrédit sur la qualité de la prestation de veille dans son ensemble et les compétences du veilleur. On a alors vite tendance à tomber dans une quête d’exhaustivité que l’on sait pourtant vaine.
Pourtant, on ne le sait que trop : « trop d’info tue l’information » et on prend le risque de ne même plus voir une information clé qui est pourtant sous nos yeux.
Il faut réussir à refaire place nette et se recentrer sur l’essentiel en séparant les sources clés de celles de second plan.
Les sources clés, ce sont celles qui sont les premières ou les seules à publier les informations qui nous intéressent ou encore celles qui sont hyper-spécialisées sur les thématiques qui nous intéressent. Ce n’est pas pour rien que l’on parle tant de la réussite de certains médias professionnels ces dernières semaines (voir l’article des Échos « Les “pure players” de l’information professionnelle tirent leur épingle du jeu »). Ces médias s’adressent à un public restreint dont ils connaissent les besoins informationnels et proposent des contenus à haute valeur ajoutée que l’on ne retrouve nulle part ailleurs.
Les sources de second plan sont celles dont on ne sait pas toujours quoi faire. Ce sont les sources qui ne méritent pas qu’on les efface complètement de son dispositif de veille, mais qui, pour de multiples raisons, ne méritent pas non plus de figurer au cœur du dispositif et de bénéficier d’une surveillance constante.
C’est à ces sources, qu’il faut savoir mettre « en veilleuse », que nous avons choisi de nous intéresser aujourd’hui. Comment sélectionner ces sources de veille de second plan ? Où les met-on ? Et comment leur donner quand même une place dans son processus de veille ?
À l’heure de « l’ignorance critique » et de « l’omission stratégique »
Avant de nous intéresser à ces sources de second rang, il est important de les repositionner dans le contexte ambiant d’infobésité. En effet, si nous avions un volume raisonnable de sources et de contenus et du temps à leur consacrer (comme cela a pu être le cas par le passé), cela ne poserait que peu de problèmes de mettre sous surveillance toutes les sources que l’on a pu repérer lors de son sourcing. Mais le contexte est aujourd’hui tout autre.
Dans le monde de la Tech et plus généralement sur le Web, on lit de plus en plus que l’infobésité ambiante oblige les internautes à revoir leurs pratiques informationnelles quels que soient leur métier et leur secteur d’activité et qu’il vaut mieux sélectionner l’information en amont.
On citera par exemple cet article académique en open access « Critical Ignoring as a Core Competence for Digital Citizens » paru dans la revue Current Directions in psychological science, ou cet article de The Conversation « When critical thinking isn’t enough: to beat information overload, we need to learn “critical ignoring” » , qui nous expliquent que, pour naviguer dans le monde de l’information digitale, l’esprit critique par rapport aux contenus qui nous arrivent n’est plus une condition suffisante. Il faut apprendre à ignorer, filtrer l’information avant même qu’elle ne nous arrive.
« L’ignorance critique est la capacité à choisir ce qu’il faut ignorer et/ou investir ses capacités attentionnelles limitées. Ignorer de manière critique, c’est plus que ne pas prêter attention, c’est pratiquer des habitudes saines et attentives face à la surabondance d’informations. » The Conversation
On citera également l’excellente newsletter de Marie Dollé, In Bed with Tech, qui proposait récemment une édition « Filtrer le bruit ou l’art de l’omission stratégique » , où elle évoquait cette question :
« “La curation ne réside pas dans l’accumulation, mais dans l’art du non-choix. Ce qui compte vraiment, c’est la cohérence globale de ce qui est retenu”. Ce passage du FOMO (fear of missing out) au NOMO (necessity of missing out) est peut-être la clé d’une gestion de l’information plus saine et plus consciente à l’ère de l’infobésité. Le NOMO, dans son essence, n’est pas une privation, mais une délivrance. Choisir, c’est accumuler. Omettre, c’est se libérer. »
Quid de la veille par rapport à cette tendance ?
En tant que veilleur, on pratique, sans le nommer ainsi, l’« ignorance critique » ou l’« omission stratégique » depuis toujours. Faire du sourcing, n’est-ce pas tout simplement une forme d’« omission stratégique » ?
Mais il est possible que l’évolution des pratiques et des outils nous en éloigne avec les années, et que la peur de passer à côté d’une information importante nous pousse à accumuler plus de sources que nécessaire.
Cette évolution n’est d’ailleurs pas le propre des humains veilleurs, c’est aussi une tendance qui s’observe dans les outils utilisés.
Pendant longtemps, le plus dur pour les professionnels de l’information n’était pas de faire le tri parmi les sources et les informations. C’était tout simplement d’en trouver. L’information était rare, les sources aussi, et ces dernières n’étaient pas toujours simples à identifier.
Déjà abonné ? Connectez-vous...
FOCUS IA : trois outils IA pour maximiser vos présentations et livrables de veille

Microsoft vient de mettre à disposition du marché européen son offre IA adaptée à sa suite Office et son tarif, 30 €/mois/personne, n’est pas négligeable pour un service de veille.
Voici donc trois alternatives freemium, soit pour modifier des présentations existantes grâce à l’IA, soit pour générer des présentations entières en un prompt. Le tout sans alourdir son budget.
Bien sûr, si une présentation peut désormais être générée en un prompt, l’IA ne fait pas tout le travail à sa place, mais elle donne une base visuellement attractive, structurée et quelques idées pour enrichir son propre travail.
Ceci, afin de réaliser une présentation commerciale valorisante de son offre en interne ou à l’externe, ou bien de présenter son produit final, qu’il s’agisse de chiffres de marché, de suivi de tendances, d’analyse comparative ou tout simplement d’un résumé des résultats de sa veille.
Plus AI, le plus intelligent
Plus AI est un add-on (une extension) qui s’installe dans Google Slides. On l’installe via la Google Workspace Marketplace. Ensuite, on y accède depuis un nouveau document sur Google Slides, en cliquant sur « Extension », ce qui ouvre une nouvelle fenêtre de création de slides (ou diapositives).
Pour commencer une présentation, il existe premièrement plusieurs options : générer une présentation complète à partir d’un prompt, insérer un texte préalablement rédigé ou procéder à la création de slides individuelles. Deuxièmement, on choisit le style : commercial, webinaire, cours en ligne, etc.
Un exemple de prompt s’affiche en anglais. Toutefois l’outil comprend parfaitement les prompts en français, ce qui constitue l’une de ses valeurs ajoutées. En lui demandant par exemple de créer un atelier d’éducation aux médias, Plus AI génère treize slides, ce qui est un autre atout car souvent les outils de ce type génèrent six slides au maximum en version gratuite, ce qui est difficilement exploitable. Avant de générer les slides, il propose un plan à valider, avec les titres modifiables de chaque slide et en (bon) français. On choisit ensuite une gamme de couleurs, puis des visuels sont automatiquement proposés. Une prévisualisation à personnaliser/corriger est alors proposée, ce qui est rare dans une version gratuite ! Nec plus ultra, des conseils d’animation pour interagir avec les élèves figurent aussi sur les slides ! Quand le résultat est satisfaisant, on clique sur « Generate ».
Les seuls problèmes relevés lors de l’expérience : les accents des mots français non pris en compte et la non-intégration d’un éditeur d’image dans le logiciel.
Déjà abonné ? Connectez-vous...
Identifier des podcasts pour sa veille

Les podcasts ont une place particulière dans le monde de la veille. C’est un type de sources qui a, sur certains sujets, une valeur inestimable. Ils peuvent en effet proposer des informations que l’on ne retrouve pas ailleurs, offrir de l’analyse et de la profondeur difficile à obtenir dans des contenus plus courts comme des articles par exemple, etc. De plus, les podcasts sont souvent gratuits, ce qui ne nécessite pas une souscription à un abonnement supplémentaire.
Mais choisir d’intégrer des podcasts à sa démarche, c’est aussi beaucoup d’embûches en perspective et à tous les niveaux : ils sont difficiles à identifier et à mettre en veille de manière automatisée, ils sont longs à écouter et à analyser, mais ils sont aussi compliqués à intégrer aux livrables (voir notre article Comment intégrer les podcasts à ses livrables de veille ?, Bases N° 410 - jan 2023).
Dans cet article, nous avons choisi de nous focaliser exclusivement sur la phase d’identification de podcasts : comment identifier des podcasts pertinents à intégrer à son sourcing ? Quels outils et méthodes utiliser pour y parvenir ?
Nous nous intéressons ici aux podcasts au sens large : podcasts journalistiques et podcasts de marques ou amateurs, à l’exception des replays d’émissions qui existent déjà sous un autre format. La méthode proposée permet d’identifier des podcasts français mais elle fonctionne aussi pour des podcasts réalisés dans d’autres pays et dans d’autres langues.
Tirer parti des recensements de podcasts existants
Un bon moyen de repérer des podcasts est de tirer parti du travail de recensement déjà réalisé par des journalistes, chercheurs, etc. Il existe en effet en France, mais aussi ailleurs des cartographies du paysage et du marché des podcasts, des datasets de recensements, etc.
Les recensements évoqués ici viennent d’un article passionnant paru dans la revue Les Enjeux de la communication en septembre 2023 : « Les podcasts natifs d’information en France : méthodologie pour un recensement de l’offre ».
Les auteurs de cet article proposent « un retour descriptif et analytique sur la méthodologie employée pour réaliser une base de données des podcasts natifs ». Si la base de données de podcasts n’est malheureusement pas accessible au commun des mortels, les éléments de méthode et les sources égrenées tout au long de l’article sont quant à elles extrêmement précieuses.
Parmi les recensements de podcasts évoqués dans l’article, on citera :
- La cartographie des acteurs du podcasts en France. La version 2023 est disponible à l’adresse suivante : www.cosavostra.com. On peut visualiser l’écosystème des médias audiovisuels qui produisent des podcasts, ainsi que celui de la presse écrite et les studios de podcasts. Il ne reste plus qu’à aller explorer les sites de ces différents acteurs à la recherche de podcasts.
- Podcast city, une carte avec une sélection des principaux podcasts français. La carte date de 2021, les données ne sont donc pas toutes à jour, mais la carte reste très intéressante.
- Un dataset des podcasts français archivés à l’INA au titre du dépôt légal sur www.data.gouv. Le fichier n’a malheureusement pas été remis à jour depuis novembre 2020. Et sur le site de l’INA, il n’est pas possible d’accéder au recensement des podcasts français.
- Un dataset proposé par Spotify qui contient plus de 100 000 épisodes de podcasts hébergés sur Spotify en anglais et portugais seulement. Le dataset n’est pas librement accessible mais on peut en faire la demande auprès de Spotify.
- PodcastRE, une base de données réalisée par le département des arts de la communication et les bibliothèques de l’Université du Wisconsin-Madison qui recense des podcasts en langue anglaise.
Déjà abonné ? Connectez-vous...
Test : les bibliothèques publicitaires LinkedIn et TikTok pour la veille

Avec leurs résultats mesurables, les médias sociaux sont devenus incontournables pour les annonceurs et les professionnels du marketing qui touchent un public de masse ou ciblé. Dans ce contexte, les bibliothèques de publicités LinkedIn et TikTok, qui viennent d’être mises à jour pour rendre publiques plusieurs données publicitaires diffusées sur leurs plateformes, peuvent apporter des informations précieuses dans le cadre d’une veille stratégique.
Mais pour structurer sa recherche, encore faut-il savoir ce que l’on peut y trouver. Voici donc en détail ce que ces deux bibliothèques ont à offrir au professionnel de la veille et comment les exploiter pour renforcer sa veille stratégique et/ou commerciale.
Pour y accéder, le plus simple est encore… de cliquer sur les liens fournis par une recherche Google ou par les articles qui en parlent. Car si ces bibliothèques existent par souci de se conformer au niveau de transparence exigée dans l’Union européenne par la Digital Act (DSA), il n’en reste pas moins qu’elles ne sont pas accessibles ni en page d’accueil des réseaux sociaux, ni sur son compte, ni même sur les pages dédiées aux publicités. Qu’il s’agisse de LinkedIn ou de TikTok, il « suffit » donc de se rendre sur cette page LinkedIn (https://www.linkedin.com/ad-library), ou celle-ci pour TikTok (https://library.tiktok.com/ads). En revanche, nul besoin d’ouvrir un compte sur ces réseaux pour disposer des informations publicitaires.
Une recherche inégale
La bibliothèque de publicités de LinkedIn offre une variété de filtres pour affiner votre recherche :
- Nom de l’annonceur ;
- Mot-clé ;
- Pays ;
- Période (jusqu’à 1 an, à partir du 1er juin 2023).
On peut ainsi rechercher certaines activités seulement au sein d’un grand groupe, comme « Orange » (nom de l’entreprise) + « Cybersécurité » (mot-clé), qui nous présentera les annonces publicitaires de « Orange Cyberdéfense » (voir Figure 1).
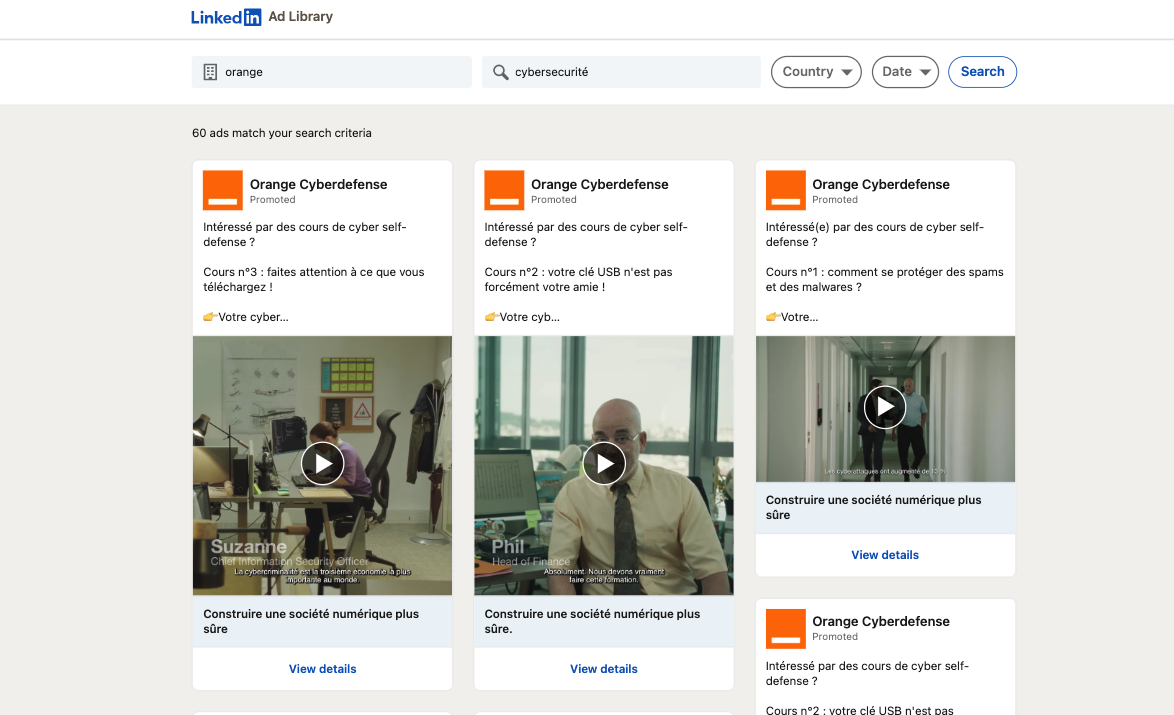
Figure 1 : Les résultats d’une recherche « Orange+Cybersécurité » sur la bibliothèque de Publicités LinkedIn.
Chaque aperçu de l’annonce, appelé « vignette » est assorti d’un lien « View details » qui permet d’accéder à une série d’informations : date, nom de l’agence publicitaire et, conformément au digital, le nombre d’impressions par pays et le ciblage.
Déjà abonné ? Connectez-vous...
Le no-code au service des veilleurs

Depuis quelques années, le mouvement no-code / low-code s’inscrit dans l’actualité des outils de veille. Ces outils permettent incontestablement d’imaginer et de réaliser des tâches qu’il était impossible de réaliser soi-même auparavant sans savoir coder (ou juste un peu, pour le low-code). Or, comme la datavisualisation , le no-code constitue un véritable moteur de transformation non seulement des usages, mais du métier dans son ensemble, tant il est vrai que le professionnel de l’information agit de concert avec les avancées informatiques comme nous l’avions déjà illustré avec l’utilisation de Github.
Les outils no-code, 100 % en ligne (hébergés dans le cloud, donc sans élément à installer), permettent de réaliser des sites web et des applications, mais aussi de créer des automatisations, notamment avec des bases de données. Les veilleurs étant habitués à s’adapter à l’environnement numérique de leur client, c’est surtout l’automatisation et la manipulation des bases de données qui les concernent.
Et ces outils interviennent aussi bien au niveau de l’interface client, que des automatisations et connexions aux APIs ou même de la structuration de la donnée.
Ils envahissent le quotidien des professionnels de la veille depuis quelques années, dans les entreprises de toute taille. Pour le veilleur, les outils no-code sont devenus essentiels à chaque étape de la veille.
Lire aussi :
« Le veilleur face au défi de la représentation des données » (Netsources N°161 - nov/déc 2022)
« Github : le self-service du veilleur fauché, mais très motivé » (Bases N°396 - oct 2021)
Cela concerne notamment :
- L’extraction automatisée d’informations à partir de différentes sources (ou scraping des données) ;
- La collecte d’informations, automatisée ou non, à partir des réseaux sociaux, des sites web, des bases de données, etc., via la création de flux RSS par exemple ;
- La classification et l’analyse des informations afin de mieux comprendre les évolutions d’un marché ;
- La création de tableaux de bord et de rapports visuels pour présenter les résultats de l’analyse des données ;
- La diffusion des informations rapide via des e-mails, des notifications push, etc.
Pour ne citer que deux exemples parmi des milliers, il est ainsi possible de faire du scraping de données d’un site web avec Simple Scraper et de les importer pour une mise à jour automatique dans Airtable sous forme de CSV pour les visualiser et les partager, avant de les enrichir avec Make. Ou même de lire ses flux RSS dans Airtable, grâce à au module « Watch RSS feed items » de l’outil d’automatisation Make (ex-Integromat), et ce en cinq minutes.
Mais ce n’est que le reflet d’une réalité bien plus large : selon une étude Gartner de novembre 2021, le no-code participera à 70 % des nouvelles applications en 2025. Après avoir connu une forte expansion pendant le confinement (télétravail oblige), des levées de fonds à plusieurs millions et des startups créées uniquement sur la base d’outils no-code, les acteurs du no-code se structurent en France et forment un écosystème, notamment autour de l’Association No Code France, du Syndicat des professionnels du No-code ou du No-code Summit. Il faut dire qu’ils ont tout pour plaire :
- La diversité des milliers de fonctionnalités à explorer ;
- La facilité d’utilisation pour des professionnels souvent autonomes et en recherche d’optimisation du circuit de l’information… ce que permet l’automatisation ;
- Les prix adaptés au niveau d’utilisation et souvent peu onéreux.
Est-ce une bonne idée de s’en saisir ?
Avec leur effet souvent « waouh », on se laisse vite impressionner par les vidéos marketing et les divers tutos qui promettent un maximum d’effet pour un minimum d’investissement. Pourtant, si les avantages sont bien souvent connus, les limites sont trop souvent ignorées. Et s’il n’est pas question de s’en priver, il est néanmoins nécessaire de garder en tête les limites afin d’encadrer leur utilisation dans un cadre professionnel.
Déjà abonné ? Connectez-vous...
Bluesky redessine la veille en feeds

Sur Twitter, le nombre de fonctionnalités essentielles à la veille se réduisant drastiquement, nombreux sont les professionnels qui se questionnent sur les alternatives. Twitter a perdu encore 10 % d’abonnés en quelques mois, et les institutions, comme l’ENSSIB par exemple, commencent également à déserter cet espace.
Parmi ces alternatives, on distingue Bluesky, qui semble plus légitime que les autres, car créée par l’ancien fondateur de Twitter lui-même, Jack Dorsey. Cette plateforme de microblogging a été lancée en février dernier. Elle est actuellement disponible sur invitation uniquement et a dépassé le million d’utilisateurs (à titre de comparaison, Twitter compte environ 200 millions et Discord 300 millions d’utilisateurs réguliers). Outre sa ressemblance avec le Twitter des débuts, sans pubs, sans algorithmes intrusifs et de vraies fonctionnalités de recherche, son atout pour les veilleurs réside dans son ambition de rendre le contrôle des algorithmes, et donc des feeds, à ses utilisateurs.
Et si Bluesky réussit son challenge, le veilleur pourrait y retrouver sa communauté - et son sourcing - qu’il perd petit à petit sur Twitter. Parmi la communauté francophone, les journalistes, suivis par les chercheurs et les experts, s’y retrouvent déjà dans une ambiance calfeutrée et intimiste. Autre avantage, Bluesky remet les fils d’actualités - appelés Feeds - à l’honneur, un peu comme si Twitter avait mis en avant la fonctionnalité des Listes, essentielle aux veilleurs, mais toujours méconnue et de ce fait sous-exploitée.
Lire aussi :
« La veille sur les réseaux sociaux s’annonce de plus en plus fragmentée » (Bases N° 417 - sept 2023)
Réussir son entrée
Obtenir une invitation
C’est LA condition, l’étape la plus difficile à franchir : obtenir le précieux sésame. Le délai de la liste d’attente s’allonge de mois en mois, mais ce n’est que temporaire. En attendant, pour l’obtenir, nous avons demandé sur Twitter - comme conseillé dans la presse - en suivant le hashtag #bluesky, mais personne ne nous a répondu. Finalement, on a fini par la demander ouvertement sur une communauté Discord, avant de l’obtenir à la suite d’un live sur LinkedIn consacré à BlueSky. Premier arrivé… premier servi. Sachez tout de même que les heureux élus peuvent à leur tour donner des invitations régulièrement. Il est aussi régulièrement proposé des invitations à la fin des articles ou des vidéos sur Bluesky.
Et pour maintenir la coutume, une invitation est réservée au premier lecteur qui en fera la demande à la rédaction !
Choisir (ou pas) son propre serveur
Un réseau décentralisé… si on le souhaite. C’est la première question posée à l’inscription : souhaite-t-on utiliser le serveur de Bluesky ou celui de son choix ? Car il s’agit, comme Mastodon, d’un réseau décentralisé. Ce n’est cependant pas obligatoire sur Bluesky, ce qui lève un frein important à son utilisation.
Le serveur se révèle toutefois fort utile dans un contexte professionnel : il sert à stocker ses données personnelles, ce qui est un gage de confidentialité. La nouveauté est qu’il s’agit aussi d’un moyen pour obtenir un identifiant numérique unique qui permettra, à l’avenir, la portabilité de ses données et de ses choix algorithmiques. Un peu comme une valise que l’on garderait avec soi de réseau social en réseau social. Enfin, définir son domaine en tant qu’identifiant fiabilise l’authentification des comptes. Plus besoin de petit badge bleu !

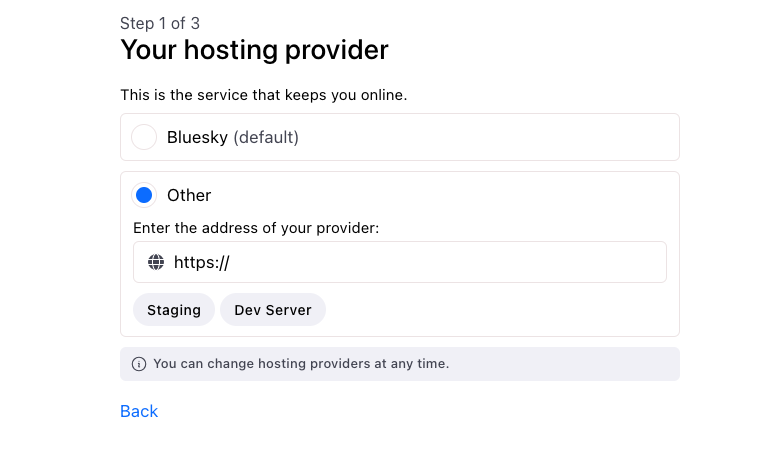
Figure 1 : Lors de sa première connexion, il est demandé si l’on veut héberger ses données sur le serveur Bluesky ou à une autre adresse spécifique.
Concrètement, le nom du serveur apparaît comme un nom de domaine dans une adresse @votrenom.nomduserveur.extension. L’adresse sur le serveur de Bluesky est donc @utilisateur.bsky.social mais il est possible de la remplacer par le nom de son entreprise, comme @prenom.bases-netsources.com.
On considérera donc cette option avec soin, d’autant que « Bsky » nous propose de le mettre en place pour une dizaine d’euros par an, ce qui est son seul service payant (adopté par 10 % environ des 100 000 premiers utilisateurs).
Après avoir choisi son serveur, configurer son profil est rapide : la bio, la photo de profil et une bannière. À noter, le format de cette dernière n’est pas simple à trouver (nous avons tâtonné) et elle n’est pas encore intégrée dans les outils marketing puisque l’usage de Bluesky est encore confidentiel.
Comprendre son environnement
Déjà abonné ? Connectez-vous...
4 générateurs de vidéos freemiums au banc d’essai

Les générateurs de vidéos, ou Text to Video, sont-ils l’occasion de tester le format vidéo, trop cher jusqu’à présent, pour certains professionnels de la veille ?
La vidéo peut servir non seulement à favoriser la transformation d’une information en connaissance pour un livrable, mais elle peut aussi contribuer à animer, voire moderniser, un support pédagogique, ou encore à vendre son service de façon plus commerciale. Voici donc - parmi la centaine existants - 4 outils faciles à utiliser pour s’autoriser à passer le pas, technique et financier, de la vidéo. Au-delà du résultat, leur prouesse réside surtout dans leur facilité d’utilisation (les outils de notre sélection n’ont pas de table de montage) et dans leur rapidité d’exécution (une quinzaine de minutes suffit).
Fliki, des vidéos à partir de vos documents en quelques minutes
Fliki, des vidéos à partir de vos documents, dix fois plus vite ? Telle est la promesse de cet outil freemium. Mais que l’on ne s’y trompe pas, il faudra tout de même plus que « quelques minutes » pour créer son premier projet. Néanmoins, comme c’est le cas de la plupart de ces outils, la procédure est simplifiée à l’extrême pour permettre de créer une analyse sous format audio ou vidéo.
Comme la plupart des générateurs de vidéo, on s’inscrit avant d’accéder à un studio de montage ultra simplifié, puis on choisit :
● si l’on veut créer une vidéo ou un audio,
● sa langue,
● si l’on veut créer une vidéo à partir d’un billet de blog, d’une présentation PPTX, d’une simple idée… ou même d’un tweet !
Nous avons testé l’outil avec une présentation d’une trentaine de slides qui s’est alors transformée en un diaporama de plus d’une minute.
Déjà abonné ? Connectez-vous...




















