Sélectionner le numéro de "Bases" à afficher
Presearch permet de chercher depuis la localisation de son choix

Le moteur de recherche décentralisé Presearch a lancé récemment une option de géolocalisation au choix, une pratique essentielle pour identifier des sources et rechercher des informations au niveau international.
Depuis l’arrêt de l’option de localisation des recherches chez Google il y a quelques années, le plus simple pour localiser sa recherche où on le souhaite consistait souvent à utiliser des VPNs ou petites extensions spécialisées comme Geolocalized Search, USearch from… (« Sortir de la recherche géolocalisée sur Google », BASES n° 395, septembre 2021).
D’autres moteurs, récemment lancés, intègrent également directement cette fonctionnalité comme Kagi Search ou encore Neeva.
Comment ça marche sur Presearch ?
En un clic, il est possible de spécifier explicitement un pays pour recevoir les résultats de recherche locaux au lieu de se limiter aux résultats en fonction de sa connexion réseau.
La localisation au niveau des villes sur Presearch est également possible, mais semble plus aléatoire : la capitale malaisienne « Kuala Lumpur » a ainsi été reconnue comme une ville… en Indonésie. Mais les médias des résultats de recherche étaient bien malaisiens.

Facebook : que reste-t-il à surveiller ?

Au cours des derniers mois, Facebook a retiré une multitude de fonctionnalités intéressantes pour le pro de l’info, souvent après à peine un an d’utilisation : les newsletters « Bulletin » qui devaient concurrencer Substack, le moteur d’offres d’emploi, les podcasts, et même l’onglet Facebook News semble sur la sellette après l’annonce en novembre dernier du remplacement des journalistes en charge de la curation par des algorithmes.
En France, le contrat de Facebook avec une filiale de l’AFP pour la vérification des informations s’est aussi arrêté. Les médias, dont le contenu n’est vu que par 3 % des utilisateurs, ne seraient pas rentables pour la plateforme. D’autant qu’en France Facebook rémunère la diffusion des contenus en provenance des médias au titre des droits voisins.
On peut donc craindre que la recherche ou la surveillance de l’information sur Facebook perde en fiabilité pour le veilleur.
En conséquence, l’intérêt d’inclure Facebook dans sa veille et la recherche d’information diminue.
Ne résiste finalement que le cœur du réseau social avec des contenus et fonctionnalités très grand public : les pages des professionnels qui s’adressent au grand public (BtoC), comme les commerçants locaux, à surveiller dans le cadre d’une veille concurrentielle, ou d’e-réputation.
Légifrance améliore ses fonctionnalités de recherche

Depuis la mise à jour du moteur en juillet dernier (et le remplacement de son interface), nombreux sont les professionnels qui regrettent l’ancienne interface.
Qu’à cela ne tienne, Légifrance a procédé à quelques améliorations récemment au niveau de la recherche. Outre une dizaine de corrections de bugs, on notera les nouveautés suivantes :
- Interprétation du tiret comme un espace dans la recherche (par exemple, les recherches Mont-Saint-Michel et Mont-Saint-Michel sont interprétées de la même façon et donnent la même liste de résultats) ;
- Amélioration du surlignement dans les résultats de recherche ;
- Ajout des plans de classement de la jurisprudence administrative et de la jurisprudence judiciaire ;
- Ajout de la numérotation des textes dans les résultats de recherche de toutes les jurisprudences ;
- Refonte des pages de recherche avancée de la jurisprudence administrative et judiciaire ;
- Ajout de l’onglet « versions » sur les articles des textes du fonds Journal officiel ;
- Amélioration de l’affichage des textes des Bulletins Officiels des Conventions Collectives ;
- Ajout des textes de réserves sur les conventions collectives ;
- Ajout du filtrage sur les accords collectifs de la fonction publique ;
Pour une analyse complète et détaillée du nouveau Légifrance, nous vous conseillons la lecture de l’excellent billet d’Emmanuel Barthe « Le nouveau Légifrance : analyse raisonnée de la nouvelle version ».
Un des gros manques pour le veilleur sur Légifrance, c’est l’absence de flux RSS. Même si ce n’est pas parfait, on notera tout de même l’initiative d’un internaute qui a créé un petit outil permettant de créer des flux RSS sur Légifrance (https://legifrss.github.io/) ainsi qu’un bot Twitter (qui publie les mises à jour Légifrance).

Quels outils utiliser pour bénéficier de ChatGPT ?


Nul n’a pu y échapper. Dans les médias, au bureau… on ne parle que de cela : ChatGPT est-il en train de ringardiser Google ?
Au regard de la recherche d’informations, ChatGPT n’est pourtant pas assez fiable pour être utilisé de façon professionnelle. D’ailleurs, ce bot conversationnel n’a pas vocation à devenir un moteur de recherche. En revanche, son impact sur la recherche d’information est réel et il est intéressant d’explorer dès maintenant les usages en la matière, en ce qu’ils préfigurent ceux des années à venir.
Difficile de résumer ChatGPT, un bot gonflé à l’intelligence artificielle, à une seule fonctionnalité : créateur de contenu (et de code), moteur de réponse, traducteur, générateur de résumé… ChatGPT fait tout cela à la fois. Il peut donc être utilisé à chaque étape de la veille, qu’il s’agisse de l’identification des besoins, du sourcing, ou de l’analyse.
Pourquoi est-il populaire ? Du fait de son interface de dialogue simplifiée, à laquelle on accède après inscription. Une fois cette formalité établie, une barre de dialogue s’ouvre en bas de page. C’est là que l’on pose ses questions. L’outil y répond en haut et la conversation défile, comme une conversation avec n’importe quel chatbot.
Les capacités de synthèse et de rédaction de ChatGPT, basées sur un puissant réseau de neurones artificiels, sont deux autres atouts pour le professionnel de la veille. Ses algorithmes ont été entraînés à partir de textes collectés sur Internet, notamment en provenance de CommonCrawl et de Wikipédia.
De nombreux articles ont été écrits pour voir ce que ChatGPT avait à offrir aux professionnels de l’information, et à ceux de la veille en particulier : analyse sémantique pour la recherche de mots clés, génération de requêtes booléennes, identification d’acteurs majeurs, collecte de flux, synthèses d’études et même rédaction d’analyses SWOT, Pestel ou autre. À tel point que ChatGPT ne semble avoir pour limite que notre propre imagination !

Déjà abonné ? Connectez-vous...
Comment intégrer les podcasts à ses livrables de veille ?

Contenu d’un nouveau type, parfois éphémère, mais qui s’affirme comme un media d’information « puissant », le podcast d’information est issu à 65 % de la presse écrite. Il est alors conçu soit comme un canal complémentaire, soit comme un véritable produit d’information avec un contenu original (dit natif), que l’on ne retrouve nulle part ailleurs.
En tant que professionnel de l’information, le veilleur est à l’affut de toute information, quel que soit son format. Avec le podcast, il se heurte à une variété de contenus et d’accès dont dépendra la collecte.
Il faut non seulement le collecter, mais aussi le traiter et l’intégrer à sa production documentaire ou à son livrable de veille.
Voir « Les nouveaux formats des médias appellent de nouvelles méthodes et outils de recherche », NETSOURCES n°150, janvier-février 2021
L’intégration des podcasts dans le produit final de la veille constitue un défi spécifique, face à une double difficulté, à la fois technique (pour trouver et utiliser les outils d’export et d’intégration adaptés) et intellectuelle (pour intégrer ce format de façon à la fois homogène et rapidement appréhendable par le destinataire).
Nous avons donc relevé le défi et exploré quatre façons d’intégrer le podcast à ses livrables.
Déjà abonné ? Connectez-vous...
Consensus, un moteur académique dopé à l’IA

L’intégration de l’IA dans les outils de recherche est le grand sujet de ce début d’année 2023. Et cela s’applique également au monde des moteurs de recherche académique.
Il y a quelques mois, nous présentions Elicit, un moteur innovant qui se présente comme un assistant dopé à l’IA
Voir notre article « Elicit, un nouveau moteur scientifique au banc d’essais », Bases N°404 - juin 2022
Dans la même veine, nous nous intéressons maintenant à un nouvel outil : Consensus dont nous allons analyser les capacités, les forces, les faiblesses et la valeur ajoutée pour le professionnel de l’information.
Consensus : l’extraction des réponses dans la littérature académique
Consensus est un moteur académique qui a été lancé courant 2022 par une startup américaine du même nom.
Comme beaucoup de moteurs/assistants à base d’IA, l’internaute entre une question en langage naturel et l’outil extrait des réponses dans les documents qui composent son corpus.
Déjà abonné ? Connectez-vous...
Déconstruction de l’article scientifique : une nouvelle façon de rechercher l’information ?

Depuis leur apparition il y a un peu moins de 400 ans, les revues scientifiques ont été confrontées à de nombreuses évolutions : le passage du papier au numérique, l’apparition des preprints, le développement de l’open access et plus largement de l’open science, etc.
Mais s’il y a bien quelque chose qui n’a que très peu changé, c'est la structure même de l’article scientifique. Malgré une transformation digitale, la version numérique de l’article, souvent en PDF, est presque toujours semblable à ce qui existait déjà au format papier.
Certains acteurs commencent à modifier la structure même de l’article scientifique ou tout du moins à proposer un modèle de diffusion qui ne soit plus limité à ce format très codifié et où les différentes parties d’un article peuvent vivre indépendamment les unes des autres.
Et cela ouvre de nouvelles possibilités pour la recherche d’information dans la littérature scientifique et académique. C’est ce que nous allons explorer dans cet article.
L’approche classique des outils de recherche IST face à l’article scientifique
- Encore aujourd’hui, on a d’un côté des articles scientifiques qui suivent pratiquement toujours la même structure très codifiée appelée IMRED (Introduction, Méthodes, Résultats et Discussion). A cela s’ajoutent le titre, l’abstract, les noms d’auteurs et affiliations et les éventuels mots-clés en début d’article et la bibliographie en fin d’article. Le contenu même de l’article peut être agrémenté de tableaux, figures et graphiques en tout genre et des références vers la bibliographie sont insérées tout le long de l’article.
- De l’autre côté, on a des outils de recherche (moteurs académiques, serveurs et bases de données) qui rassemblent les articles scientifiques dans leur globalité, chaque article correspondant à une pièce d’information non divisible.
Déjà abonné ? Connectez-vous...
Kagi Search intègre le résumé automatique aux résultats de recherche

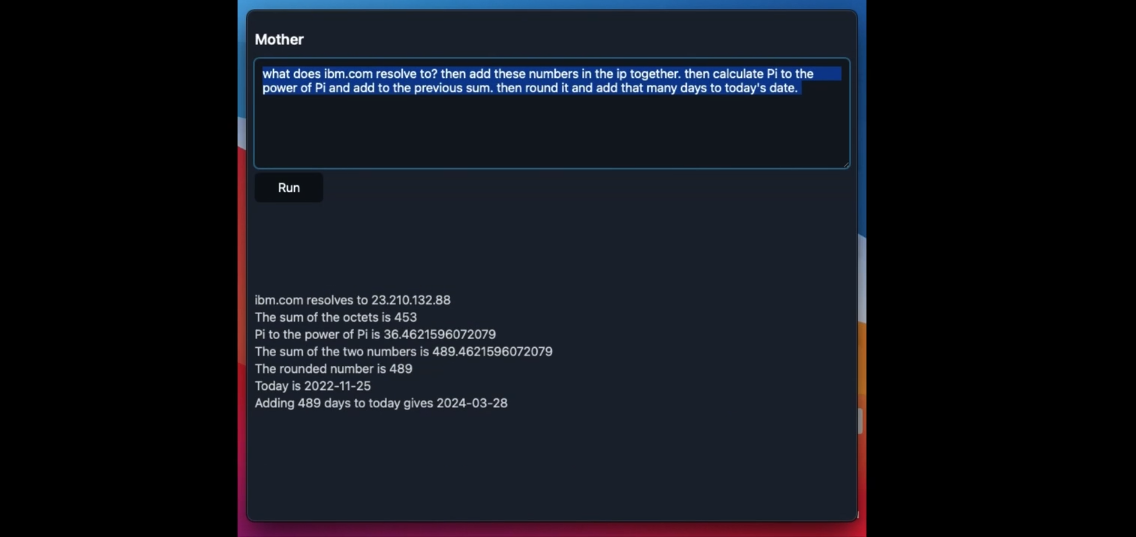
Le nouveau moteur de recherche Kagi Search travaille actuellement sur un nouveau projet de recherche baptisé « Mother ».
Le principe ?
Lorsqu’on pose une question à Mother, une IA de recherche sur le web « user-centric », « maman » ne se contente pas de fournir une liste de sources, mais en fait le résumé automatique.
Si on lui demande par exemple de comparer le nombre d’habitants entre deux villes, elle fournira directement une réponse synthétique issue de plusieurs sources, et non une liste de sources où aller chercher. Elle répond aussi à des questions comme « Pourquoi la terre est ronde ? ».
Dans ce cas, plus complexe, elle cite les sources de sa synthèse. Elle peut actuellement résumer 10 à 50 sources par résultat de recherche. On a hâte de l’essayer !
Lire aussi, BASES n° 407 en octobre 2022 « Nous avons testé Kagi Search, un nouveau challenger de Google ».
Une nouvelle fonctionnalité pour Pappers

Pappers, le moteur de recherche gratuit d’information légale et financière des entreprises françaises, vient d’ajouter les décisions de justice à sa base de données.
Le site utilise les données issues de l’open data des décisions de justice pour mettre en ligne l’ensemble des décisions de jurisprudence sur ses fiches entreprises. Pour effectuer une recherche au-delà de la consultation d’une fiche, il vaut toutefois mieux privilégier la version bêta du moteur dédié aux décisions de justice (https://justice.pappers.fr/), plus efficace que le moteur du site.
Outre des résultats plus complets, ce moteur dédié propose des filtres « Juridiction », « date de la décision », « Publication », « Dispositif », « Textes de loi cités » et « Textes de loi non cités ».
En cliquant sur une décision de justice, on accède à une page avec le menu suivant : « Synthèse », « En-tête », « Faits et procédures », « Motifs et Dispositif », et « Chronologie de l’affaire ».
Le site se vante d’avoir 1,5 million de décisions disponibles, issues des décisions du Conseil d’État et de la Cour de Cassation, des cours administratives d’appel, des cours d’appel en matière civile, sociale et commerciale, ainsi que des tribunaux administratifs. Il en promet des dizaines de millions à venir entre juin 2023 et décembre 2025, issues d’autres juridictions judiciaires et administratives (prud’hommes, tribunaux de commerce, etc.)
Voir aussi : NETSOURCES n° 501 (mars 2021), « L’information financière et légale sur les entreprises françaises : entre ouverture et fermeture des données ».
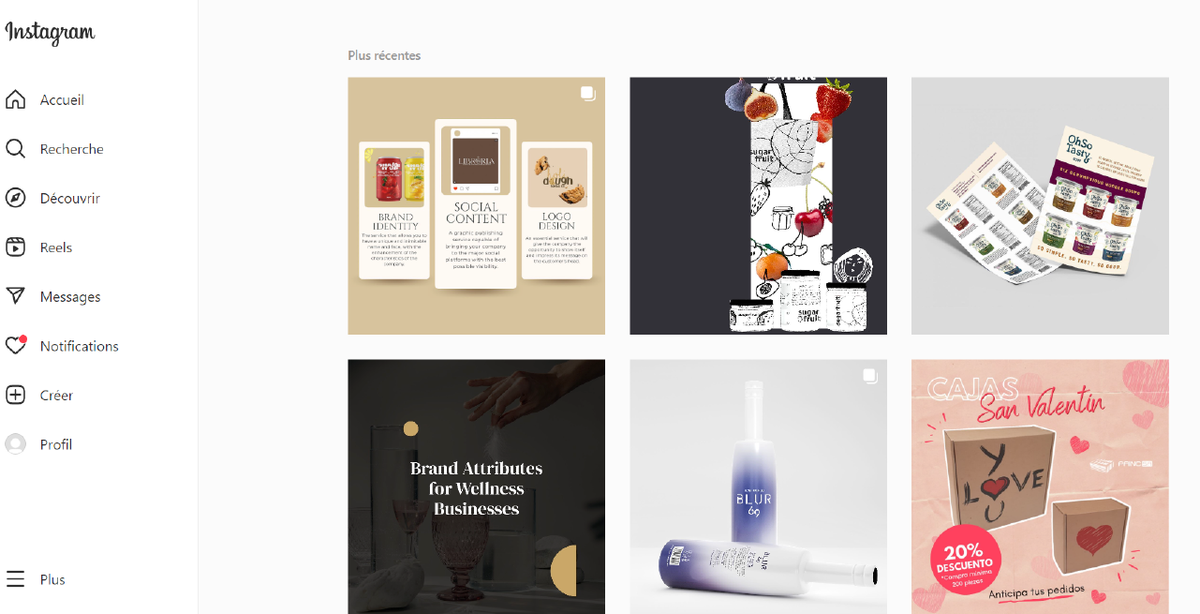
Instagram lance une nouvelle interface desktop avec une recherche améliorée

Il n’est pas toujours simple de réaliser des recherches satisfaisantes sur les réseaux sociaux tant les fonctionnalités sont limitées. C’était notamment le cas pour Instagram qui proposait jusqu’à très récemment une version desktop très limitée comparée à son application mobile.
Au début du mois de novembre, Instagram a annoncé le lancement d’une nouvelle version de son site instagram.com sur le web. Au-delà des améliorations cosmétiques, il y a une nouveauté importante qui va améliorer la recherche pour les professionnels de l’information.
Jusqu’à présent, quand on lançait une recherche sur un hashtag dans Instagram (sur la version desktop), on ne visualisait dans les résultats qu’une petite sélection de contenus appelée « meilleures publications ». Il fallait passer par l’application mobile d’Instagram pour voir tous les résultats associés à un hashtag classés par ordre antéchronologique.
Depuis le lancement de la nouvelle interface, on peut également accéder à tous les résultats depuis l’interface desktop.
C’est donc une excellente nouvelle pour les professionnels de l’info qui effectuent la majorité de leur travail sur ordinateur et non sur mobile !