Sélectionner le numéro de "Bases" à afficher
Comment faire sa veille tarifaire ? les outils spécialisés et investigations manuelles


Dans le monde professionnel, nous sommes tous confrontés un jour ou l’autre, à la recherche de tarifs.
Pour certains acteurs qui opèrent notamment une activité en BtoC et vendent des produits de grande consommation, c’est même une activité cruciale et un élément clé de leur veille concurrentielle. Il s’agit alors notamment de surveiller en continu les tarifs et surtout les variations de prix opérés par les concurrents. La veille dite « tarifaire » répond alors à une démarche très structurée et fait appel à des outils capables de mener cette veille à grande échelle.
Pour de nombreux autres acteurs, la recherche de tarifs relève plus de l’investigation ponctuelle que d’une véritable démarche de veille itérative : il s’agit par exemple d’analyser son environnement concurrentiel en essayant d’avoir une vision des tarifs pratiqués par ses concurrents, d’analyser un marché sur lequel on souhaite s’implanter, de faire une première évaluation de fournisseurs ou prestataires éventuels, etc.
Mais les tarifs ne sont pas toujours affichés sur le Web et surtout, ils ne sont pas fixes et exacts. Les tarifs de produits BtoB ou de prestations de services que l’on peut trouver sur le Web permettent certes d’avoir une première idée des tarifs pratiqués, mais les tarifs réels dépendent de multiples critères qui ne peuvent être pris en compte sur une simple page web (taille de l’entreprise, type de mission, nombres de personnes impliquées, etc.). La recherche de tarifs s’avère alors plus aléatoire et compliquée pour les produits vendus en BtoB et l’est encore davantage pour les prestations de service.
Lire aussi :
Sourcing, de la théorie à l’épreuve de la pratique (Netsources N° 146 - mai/juin 2020)
La veille sur les appels d’offres de A à Z (Netsources N° 152 - mai/juin 2021)
Comment intégrer les données d’importation et d’exportation à sa veille concurrentielle ? (Netsources N° 151 - mars/avril 2021)
Le paradoxe des outils de veille gratuits ou freemium (Netsources N° 129N° 129 - juil/août 2017)
- Dans cet article nous étudierons dans un premier temps la partie émergée de l’iceberg de la surveillance de tarifs, à savoir la « veille tarifaire » au sens strict du terme. Nous dresserons un panorama des outils et solutions disponibles aujourd’hui sur le marché.
- Dans un second temps, nous nous intéresserons aux cas où ces outils de veille ne sont pas adaptés et où il faut se tourner vers des investigations ponctuelles et manuelles. À partir d’un cas pratique, nous montrerons quelle méthode adopter et vers quelles sources se tourner quand on est confronté à cette problématique.

Déjà abonné ? Connectez-vous...
SAE lance un serveur de preprints

SAE International est une association existant depuis plus d’un siècle qui regroupe plus de 200 000 experts dans le monde de la mobilité et des transports.
- Elle propose depuis fort longtemps deux banques de données disponibles sur le serveur STN : MOBILITY (Global Mobility Bibliographic database) est une banque de données de références d’articles, conférences, livres etc., publiés depuis 1906.
- MOBILITY (Global Mobility Standards database) est une banque de données de références de normes publiées depuis 1936.
SAE International vient de lancer un serveur de préprints en accès libre baptisé SAE MobilityRxiv qui se présente comme le premier serveur de cette nature dans le domaine des transports et des mobilités (Cf. Figure 1. Interface de SAE MobilityRxiv).
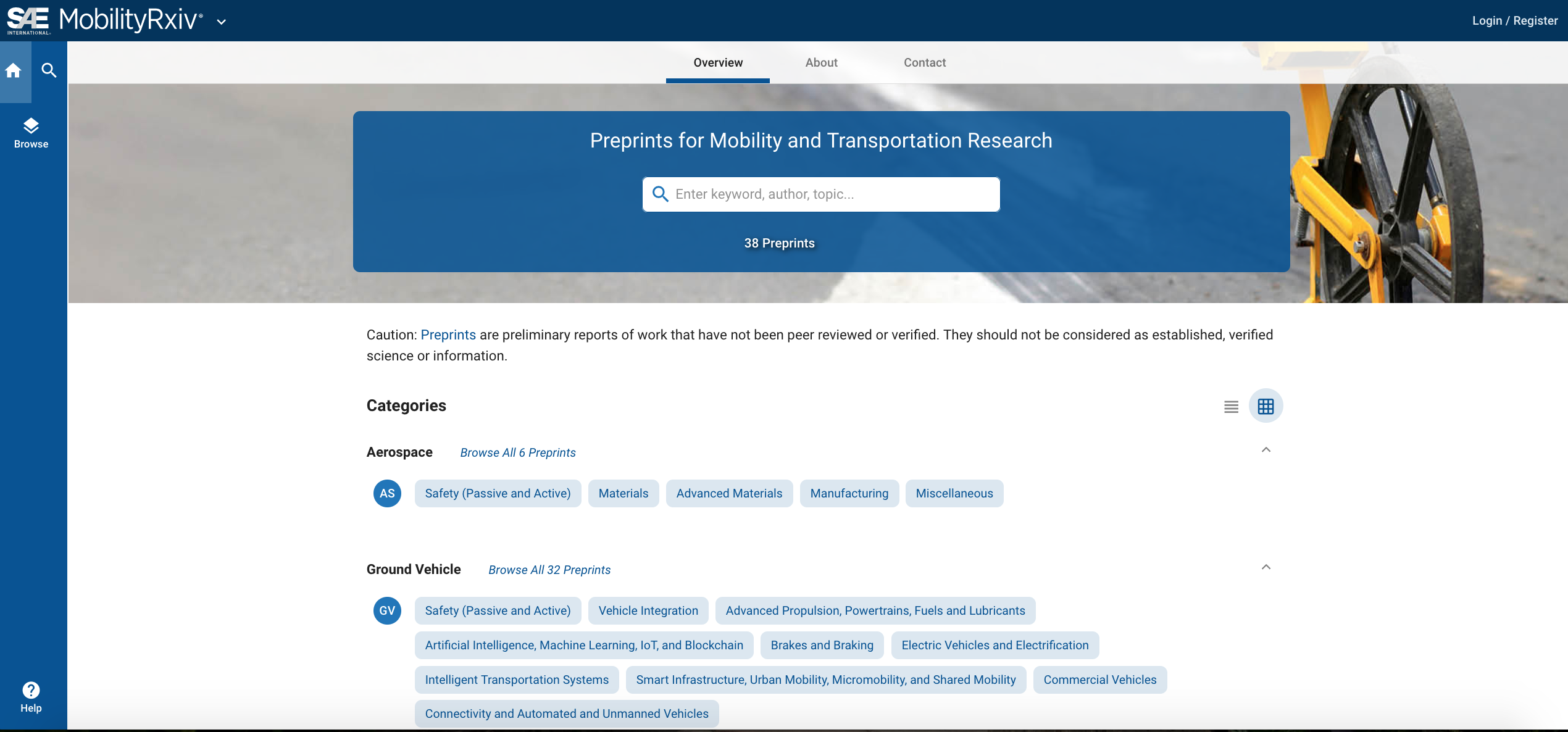
Figure 1. Interface de SAE MobilityRxiv
Ce serveur, qui donne accès à des articles, livres blancs et thèses en langue anglaise n’ayant pas encore fait l’objet d’une revue par les pairs, est destiné à faciliter le dialogue entre experts pour faciliter l’avancement du savoir dans les domaines des transports et de la mobilité.
Lancé récemment, ce site ne propose que quelques dizaines de documents, ce nombre devant vraisemblablement croître rapidement.
En tout cas, c’est une nouvelle source dans le domaine.
Lire aussi :
Les portails documentaires en libre accès : de l’or brut pour le veilleur
Zoom sur Cerema Doc, la plateforme documentaire du climat et territoires de demain
Comment bien rechercher l’information scientifique et technique ?
La veille au défi de l’information scientifique et technique
Rechercher dans les tweets et retweets d’un compte Twitter : pas si simple!

Twitter est une source d’information incontournable pour le professionnel de l’information : qu’il s’agisse de réaliser une veille métier, un sourcing thématique, un premier tour d’horizon sur un sujet, une veille concurrentielle, Twitter apporte quasi systématiquement une valeur ajoutée à la recherche d’information et à la veille.
Contrairement à la plupart des autres réseaux sociaux, Twitter a l’immense avantage de proposer des fonctionnalités de recherche dignes de ce nom, qui permettent d’explorer efficacement les contenus qu’il renferme.
Pourtant, il arrive que les fonctionnalités proposées ne soient pas suffisantes pour arriver au résultat souhaité. Il faut alors tester différentes méthodes, ruser ou trouver des outils externes qui comblent ces lacunes.
Lire aussi :
Twitter diversifie ses contenus : un casse-tête pour la veille (mars 2021)
Comment rendre Twitter plus puissant pour la veille et la recherche ? (Bases N° 383 - juil/août 2020)
RSS, Twitter, Facebook, LinkedIn et les autres: surveille-t-on vraiment la même chose ? (mai 2018)
La recherche par mot-clé sur les tweets et retweets d’un compte Twitter s’avère plus compliquée que prévu. C’est pourtant une situation que l’on peut rencontrer régulièrement. Il peut s’agir de vérifier si un compte que l’on suit a abordé tel ou tel sujet par le passé ou, lors d’un sourcing, vérifier si la personne a déjà traité spécifiquement le sujet qui nous intéresse.
Dans cet article, nous explorons les différentes méthodes disponibles pour rechercher sur un compte Twitter.
Déjà abonné ? Connectez-vous...
Zoom sur les ressources de l’AURG pour l’urbanisme et l’aménagement
L’exploration de portails documentaires dans le dernier numéro de BASES (Décembre 2021) a mis en lumière une véritable couche informationnelle du Web, constituée d’ensembles très riches de ressources et sources de valeur sur des secteurs très souvent difficiles à appréhender avec exhaustivité.
Comme nous le faisions remarquer, ces portails sont produits par des personnes qualifiées, documentalistes spécialistes des secteurs traités, qui mettent ici à profit leurs compétences d’expert(e)s de l’information. Des compétences qui garantissent la fiabilité des opérations requises pour la mise à disposition des ressources, de leur recherche à la structuration des données, en passant par leur sélection et leur mise en valeur.
À ce titre, ces produits documentaires constituent des savoirs sectoriels bien aussi précieux, plus cohérents et complets, que certaines fiches sectorielles de l’incontournable Wikipédia. Mais, comme on s’en doute, moins bien publicisés…
C’est pour cette raison que nous avons décidé de les valoriser et de vous les faire découvrir au fur et à mesure de nos découvertes dans une nouvelle rubrique de BASES. Nous n’avons pas hésité à appeler cette rubrique « les trésors du web ». De véritables trésors en effet, dans un Web où le pire côtoie le meilleur et où les ressources les plus visibles sont souvent les plus commerciales…
Lire aussi :
Les portails documentaires en libre accès : de l’or brut pour le veilleur
Zoom sur le portail de l’INRS sur la santé et sécurité au travail
Zoom sur le portail documentaire Eau & Biodiversité
Zoom sur Hortidoc, le portail dédié à l’horticulture
Zoom sur Raildoc, un portail spécialisé sur le ferroviaire
Zoom sur Cerema Doc, la plateforme documentaire du climat et territoires de demain
L’AURG, l’Agence d’urbanisme de la région grenobloise propose en libre accès de nombreux contenus en lien avec l’urbanisme et l’aménagement, et qui ne se cantonnent pas à la région grenobloise. Ces contenus sont susceptibles d’intéresser les veilleurs et professionnels de l’information.
En 2020, l’agence a lancé un nouveau blog de veille appelé « L’Agence veille pour vous » qui regroupe la veille réalisée par la documentaliste en poste. L’occasion pour nous de faire le tour des ressources et produits documentaires dont regorge le site de l’AURG, mais aussi le blog de veille.
Déjà abonné ? Connectez-vous...
Les portails documentaires en libre accès : de l’or brut pour le veilleur

Les portails documentaires ont depuis de nombreuses années de multiples atouts qui en font des candidats de choix pour le sourcing des veilleurs. Mais encore faut-il réussir à les identifier.
Les portails sont créés et alimentés par des professionnels de l’information spécialistes des thématiques qu’ils abordent, au contact direct des experts du domaine et avec une connaissance pointue de la recherche d’information et de la veille, de la mise en place des portails et de la structuration de l’information (ontologie, thésaurus, indexation, etc.).
Au-delà du catalogue classique d’une bibliothèque ou d’un centre de documentation, ou encore de certaines bases de données spécialisées, ces portails proposent de plus en plus des veilles thématiques prêtes à l’emploi, des newsletters ou encore des notes de synthèses, études et analyses.
Bref, une véritable mine d’or !
Lire aussi :
Sourcing, de la théorie à l’épreuve de la pratique (Netsources N° 146 - mai/juin 2020)
Et si on tirait parti des fonctionnalités originales des moteurs ?
Le veilleur peut-il tirer parti des veilles gratuites qui fleurissent sur LinkedIn ? (Bases N° 395 - sept 2021)
Et pourtant, quand on commence une veille, ce n’est pas nécessairement à ces ressources que l’on pense en priorité et ce ne sont pas ces sources qui ressortiront en majorité à l’étape de sourcing.
Car les portails ont un défaut majeur : ils sont généralement peu visibles sur les outils utilisés par la plupart des internautes, c’est-à-dire les moteurs de recherche et les réseaux sociaux.
Comment donc les identifier et les intégrer à son processus de veille ?
Comment mettre toutes les chances de son côté pour repérer les bons portails et les bons produits documentaires par rapport à sa thématique de veille ?
Dans cet article, nous proposerons une méthodologie avec les clés d’accès pour identifier des portails thématiques en libre accès en lien avec ses thématiques de veille.
Nous présenterons ensuite dans les prochains articles une sélection de portails thématiques intéressants.
Déjà abonné ? Connectez-vous...
Zoom sur le portail de l’INRS sur la santé et sécurité au travail

Il y a quelques mois, l’INRS (Institut National de Recherche et de Sécurité) a mis en ligne son nouveau portail documentaire à l’adresse portaildocumentaire.inrs.fr. On y trouve de multiples ressources en santé et sécurité au travail.
Quelles ressources ?
On y trouve tout d’abord INRS Biblio, une base de données bibliographique consacrée à la santé et sécurité au travail avec un focus plus spécifique sur la prévention.
À cela s’ajoutent les produits documentaires réalisés par les veilleurs et documentalistes de l’INRS :
- Des veilles thématiques ;
- Des produits de veille juridique ;
- Des dossiers documentaires.
Lire aussi :
Comment bien rechercher l’information scientifique et technique ? (Netsources N° 149 - nov/dec 2020)
Zoom sur INRS Biblio, une base de référence
INRS Biblio se positionne comme une base de référence en santé et sécurité au travail. Elle propose plus de 83 000 références bibliographiques d’articles (plus de 63 500), de brochures (plus de 6 600), de livres (plus de 4 300), d’études et rapports (près de 4 000), d’actes de congrès (plus de 2 700) et de normes (plus de 1 700), et quelques autres documents, sachant que la presse grand public n’est pas prise en compte.
On dispose d’une recherche simple et d’une recherche avancée. Cette dernière propose de combiner plusieurs champs y compris deux niveaux de descripteurs disponibles. On dispose des opérateurs booléens, de la troncature et de la possibilité de rechercher une expression entre guillemets.
Déjà abonné ? Connectez-vous...
Zoom sur Cerema Doc, la plateforme documentaire du climat et territoires de demain

Le Cerema (Centre d’études et d’expertises sur les risques, l’environnement, la mobilité et l’aménagement) a été créé en 2013 par la fusion de 11 organismes. C’est un centre de ressources et d’expertise interdisciplinaire qui travaille essentiellement pour l’État et les collectivités.
Le Cerema met à disposition des rapports d’études, des produits éditoriaux, des avis techniques, des articles qu’il réalise dans ses domaines de compétence.
En novembre 2021, le Cerema s’est doté d’une plateforme documentaire pour recenser et capitaliser l’ensemble de ses productions et livrables disponible à l’adresse : https://doc.cerema.fr/
C’est à cette plateforme riche en contenus et très ergonomique que nous allons nous intéresser dans cet article (Cf. Figure 1. Portail documentaire du Cerema).
Lire aussi :
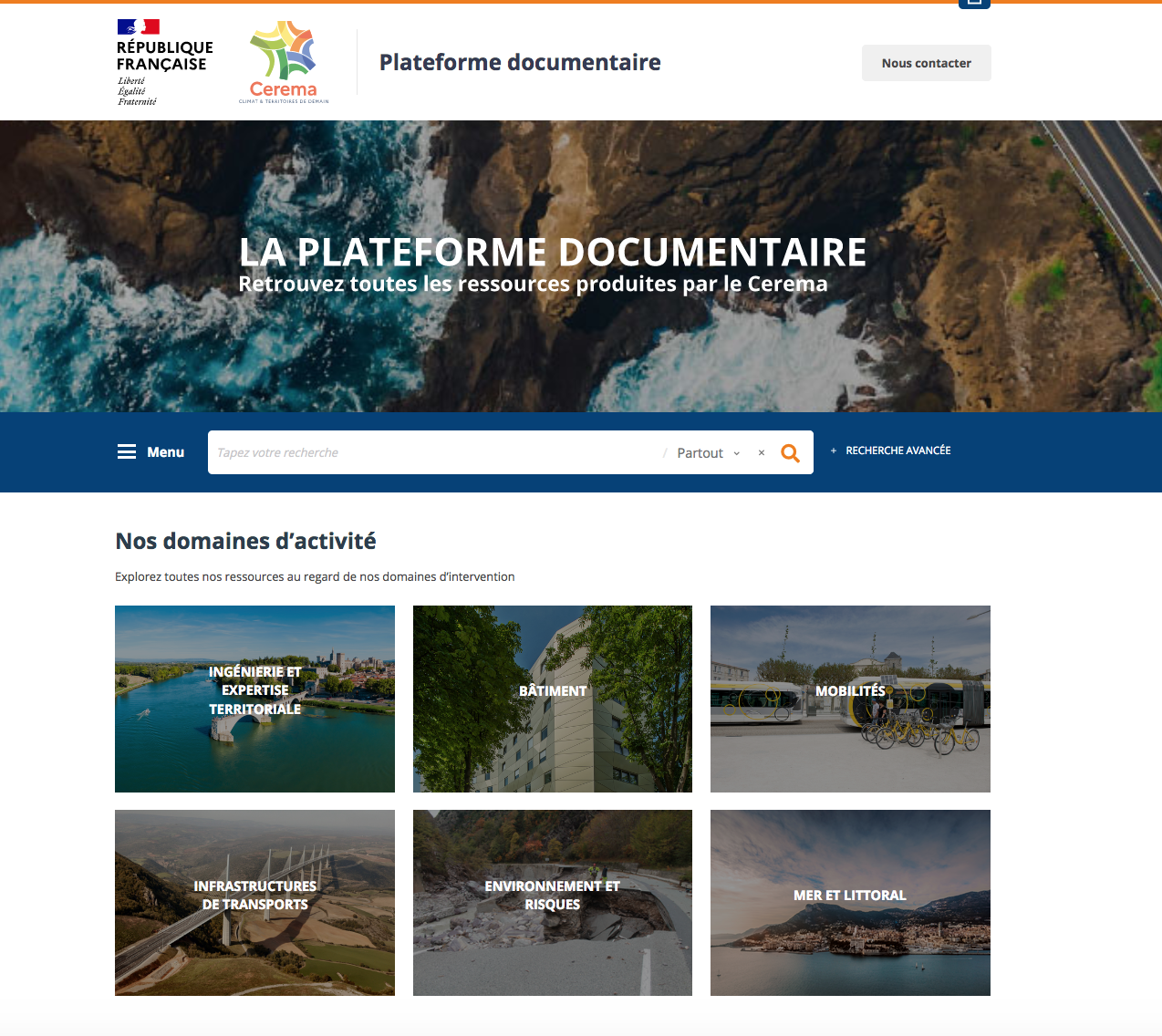
Figure 1. Portail documentaire du Cerema
Quelles ressources sur Cerema Doc ?
Lancé avec 5 000 références en 2021, l’objectif est d’y retrouver l’intégralité des connaissances produites par le Cerema d’ici la fin 2022.
Lors de nos tests, un peu plus de 7 000 documents étaient référencés sur les thématiques suivantes :
- Ingénierie et expertise territoriale ;
- Bâtiment ;
- Mobilités ;
- Infrastructures de transports ;
- Environnement et risques ;
- Mer et littoral.
Déjà abonné ? Connectez-vous...
Zoom sur le portail documentaire Eau & Biodiversité

Le portail documentaire partenarial Eau & Biodiversité a été mis en place depuis une douzaine d’années en co-animation entre l’OFB (Office français de la biodiversité) et OiEau (Office international de l’eau) et avec le soutien financier de l’OFB.
Quelle équipe derrière le portail ?
Il compte aujourd’hui 29 contributeurs mettant à disposition leur documentation technique et scientifique sur les thématiques de l’eau et de la biodiversité. Cette littérature grise libre de droits, souvent difficile d’accès, est ainsi partagée et rendue accessible à tout visiteur du portail (Cf. Figure 1. Portail Eau & Biodiversité).
Lire aussi :
Comment bien rechercher l’information scientifique et technique ? (Netsources N° 149 - nov/dec 2020)
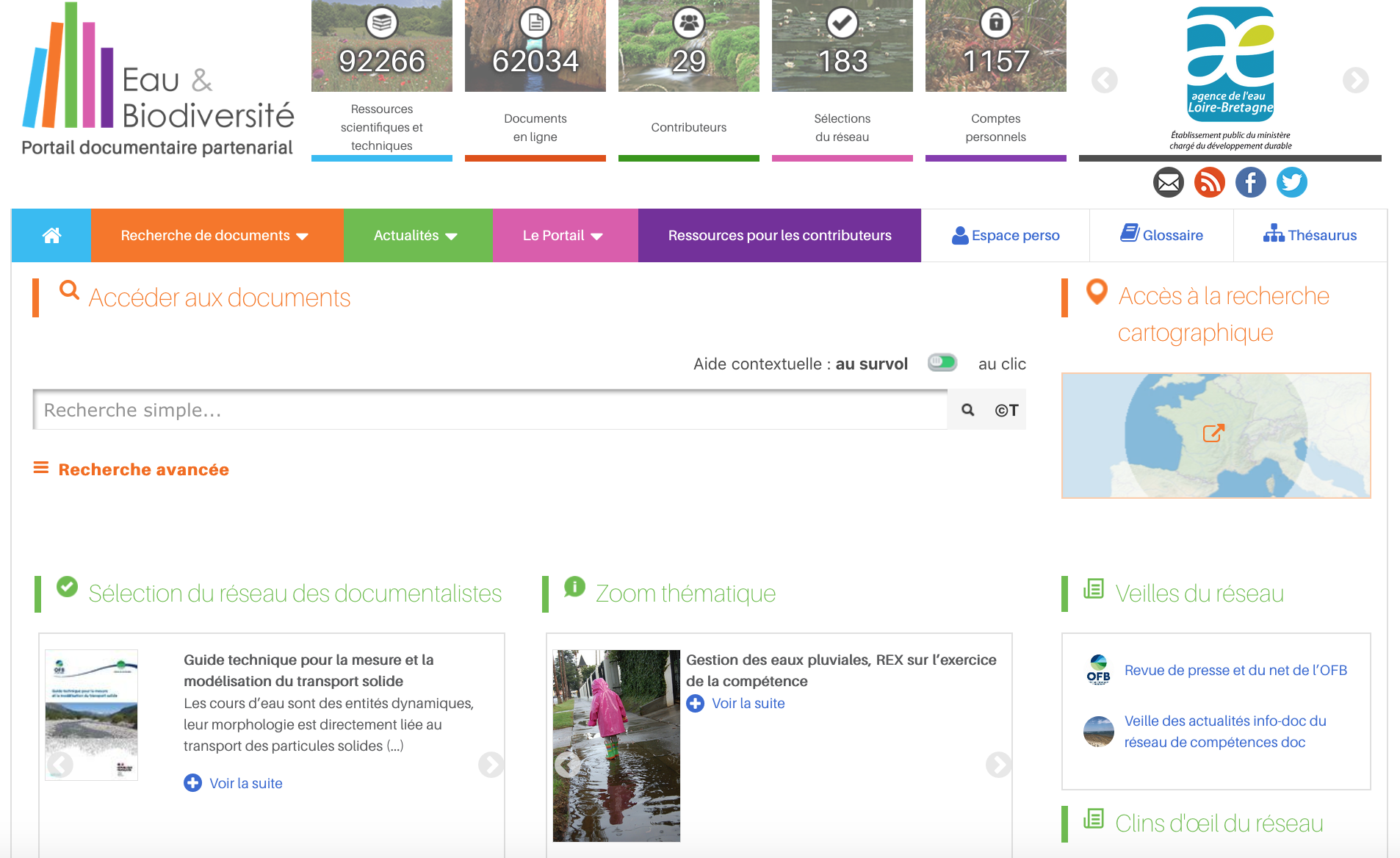
Figure 1. Portail Eau & Biodiversité
Ces 29 contributeurs sont des structures bénéficiant de financements publics en lien avec l’eau et la biodiversité. Parmi eux figurent les agences de l’eau, le BRGM (Bureau de recherches géologiques et minières), l’INRAE (Institut national de recherche pour l’agriculture, l’alimentation et l’environnement), des conservatoires botaniques, le Parc national des Écrins, etc.
L’objectif général est de valoriser les publications de ces organismes publics.
Déjà abonné ? Connectez-vous...
Zoom sur Hortidoc, le portail dédié à l’horticulture

Horti’doc est un site particulièrement riche pour qui s’intéresse à l’horticulture.
Il propose ainsi un grand nombre de liens vers différentes ressources : formations, centres de documentations, contacts européens, fonds patrimoniaux, etc.
Le réseau documentaire, créé en 2003, à l’origine de ce portail associe ASTREDHOR (Institut Technique de l’Horticulture), Agrocampus Ouest (Centre d’Angers), le site d’Angers de l’INRAE et Plante & Cité.
Lire aussi :
Les ressources cachées des collectivités territoriales
Comment bien rechercher l’information scientifique et technique ?
Quelles ressources ?
La grande force d’Hortidoc repose dans sa capacité à signaler les principales sources, ressources et produits documentaires du secteur, ce qui est extrêmement précieux notamment pour le sourcing du veilleur (Cf. Figure 1. Hortidoc)
Sont ainsi référencés :
- Les centres de documentation de la filière horticole ;
- Les formations en horticultures et paysage ;
- Les organismes en horticulture ornementale et paysage ;
- Les principaux organismes de recherche, d’expérimentation et d’enseignement supérieur horticoles en Europe ;
- La presse spécialisée du domaine ;
- Des newsletters et veilles thématiques produites par des organismes extérieurs et certains membres du portail ;
- Des bases de données et ressources bibliographiques ;
- Des sources économiques et statistiques ;
- Des thèses en horticulture et paysage ;
- Et des fonds patrimoniaux.

Figure 1. Hortidoc
Déjà abonné ? Connectez-vous...
Zoom sur Raildoc, un portail spécialisé sur le ferroviaire

Créé en 1992 par le centre de documentation de l’UIC (Union Internationale des Chemins de fer), le portail Raildoc (raildoc.uic.org) fournit de nombreuses ressources dans le domaine du transport ferroviaire international et dans les domaines connexes (politique des transports, environnement, énergie, télécommunications, etc.).
Quelles ressources ?
Le portail donne ainsi accès à :
Lire aussi :
Les ressources cachées des collectivités territoriales
Comment bien rechercher l’information scientifique et technique ?
La Twittliste de l’industrie automobile
- Une banque de données qui compte plus de 26 000 références dans le domaine du transport ferroviaire international et dans les domaines connexes (politique des transports, environnement, énergie, télécommunications, etc.) Le producteur n’assure pas la fourniture des documents primaires qu’il faut commander auprès des Éditions Techniques Ferroviaires ;
- Des bibliographies spécialisées ;
- Des documents juridiques ;
- Une veille documentaire ;
- La liste des périodiques auquel le centre de documentation est abonné ;
- Les dernières publications de l’UIC ;
- Les documents d’archives de l’UIC.
Déjà abonné ? Connectez-vous...




















