Sélectionner le numéro de "Netsources" à afficher
Naviguer dans les flux d’information et les contrôler


Dans ce numéro, nous continuons à explorer les défis que représentent pour les professionnels de l’information l’entrée dans l’ère de l’intelligence artificielle, tout en examinant les nouvelles méthodologies, les retours d’expérience et les tendances actuelles qui façonnent nos métiers.
L’émergence des IA génératives, illustrée par le succès fulgurant de ChatGPT, marque un tournant dans nos pratiques. Véronique Mesguich, dans la nouvelle édition de son ouvrage « Rechercher l’information stratégique sur le web », introduit l’impact des IA génératives sur la veille stratégique et la recherche d’information, Netsources N° 170 - mai/juin 2024. Si ces outils offrent de nouvelles perspectives d’analyse et de traitement des données, ils nécessitent une approche critique pour éviter les écueils d’informations inexactes ou biaisées.
Le passage d’une «culture de stock» à une «culture de flux» reste un défi majeur, comme le souligne notre article « Adopter une logique de flux... plus facile à dire qu’à faire », Netsources N° 170 - mai/juin 2024. Cette transition n’est pas simplement une tendance, mais une nécessité pour rester pertinents et efficaces. Il s’agit de transformer notre rapport à l’information, en favorisant la capture et l’exploitation en temps réel des données plutôt que leur simple accumulation.
Dans « Bonnes pratiques pour systématiser la surveillance de vos concurrents », Netsources N° 170 - mai/juin 2024, nous découvrons des méthodes structurées pour maintenir une veille efficace sans être submergés par l’information. La clé réside dans la sélection rigoureuse des sources et l’automatisation des processus, permettant de se concentrer sur l’analyse et la prise de décision.
L’article « Le jour où j’ai voulu mettre en place une veille collaborative », Netsources N° 170 - mai/juin 2024, offre un retour d’expérience précieux sur les défis et les succès de la veille mutualisée. Cette aventure, menée au sein d’une PME, démontre que la mutualisation des efforts peut transformer les pratiques individuelles en intelligence collective, malgré des obstacles organisationnels et humains à ne pas sous-estimer.
Rester agile et professionnel, ce sont deux des nombreux mots clefs qui résument les défis actuels de nos métiers. Face aux transformations, nous sommes invités à nous adapter constamment, à nous former sans relâche et à réinventer sans cesse nos rôles et pratiques au sein des organisations.
Véronique Mesguich: «ChatGPT est un bon poète, mais un mauvais bibliographe !» - entretien avec Anne-Marie Libmann

À l’aube d’une nouvelle ère de l’information bouleversée par l’intelligence artificielle, Véronique Mesguich nous offre une troisième édition actualisée et enrichie de son ouvrage « Rechercher l’information stratégique sur le web - Sourcing, veille et analyse à l’heure de l’IA », publié chez De Boeck Supérieur.
Cette troisième édition à jour explore l’univers des IA génératives et leur impact sur la recherche d’informations et la veille. On y découvre (après une préface d’Anne Marie Libmann), comment les IA transforment les pratiques de la recherche web, ainsi que des exemples concrets d’utilisation de l’IA pour l’extraction et l’analyse d’informations stratégiques.
L’ouvrage aborde également d’autres méthodes de recherche et de veille, basées sur la maitrise des sources et l’OSINT.
Nous avons sollicité son regard expert sur plusieurs enjeux majeurs qui, selon nous, vont influencer l’avenir de l’information et de ses professionnels.
Anne-Marie Libmann : Est-ce que l’introduction des IA génératives dans cette nouvelle édition marque une véritable évolution par rapport à vos précédents ouvrages sur la veille stratégique ? Comment la décrivez-vous ?
Véronique Mesguich : Les grandes mutations arrivent souvent de façon inattendue… C’est le cas des IA génératives illustrées par le succès fulgurant de ChatGPT. Certes, les technologies mises en œuvre ne sont pas si récentes. Les premières IA basées sur les Transformers (cette technologie représentée par le T de GPT et du modèle de langage BERT de Google) sont ainsi apparues il y a plus de cinq ans. Mais le coup de génie d’OpenAI, c’est d’avoir rendu ces modèles de langage très largement accessibles via le principe des robots conversationnels.
Les IA génératives sont ainsi en train de bouleverser nos usages numériques, dans la sphère professionnelle comme dans notre vie quotidienne. Ces IA apportent une véritable disruption que j’explicite dans plusieurs chapitres du livre ; car on peut les appliquer aux différentes phases du processus de veille ou de recherche approfondie.
Les IAG peuvent interpréter (à défaut de comprendre réellement) des requêtes en langage naturel, en toutes langues, générer des réponses plausibles sous forme de texte rédigé et synthétiser en temps réel des réponses provenant de diverses sources. ChatGPT et ses concurrents n’ont pas été conçus comme des outils de recherche d’information, mais peuvent être mis en relation avec des moteurs de recherche ou des bases de connaissance, et jouer le rôle d’assistants personnalisés.
Là encore, l’idée n’est pas si nouvelle : cela fait plusieurs années que les moteurs de recherche (à commencer par Google) ont l’ambition de fournir aux utilisateurs « la » réponse à leurs questions (et non plus seulement des liens vers des réponses censées être pertinentes). Cela est rendu possible par plusieurs évolutions technologiques de ces dernières années : l’essor de l’apprentissage profond (deep learning), l’explosion du volume des données numériques, qui ont pu constituer une matière première pour l’apprentissage, et l’augmentation fulgurante de la puissance de calcul grâce aux processeurs graphiques. Sans oublier, bien sûr, le développement de modèles de langage et d’algorithmes très puissants.
Mais comme souvent, une nouvelle vague ne remplace pas ce qui existait avant : dans cette nouvelle édition, j’évoque largement l’impact des IA génératives sur la recherche et l’analyse de l’information stratégique, mais je détaille également des méthodes, des outils et des sources « classiques » qui demeurent incontournables ! Et j’ai ajouté dans cette troisième édition des nouvelles méthodes et outils d’investigation OSINT.
AML : Quel avenir pour Google, dont la situation semble inquiétante face aux IAG qui bouleversent son business model basé sur la monétisation des contenus référencés ? Comment imaginer l’avenir des moteurs de recherche et des sites en général ?
VM : Je ne me fais pas trop de souci pour la marque Google, même si on n’utilise désormais certainement plus le moteur comme on le fait depuis des années. Avec ses modèles de langage Gemini et Gemma, Google est en train de rattraper son retard par rapport à OpenAI. Des annonces ont été faites récemment concernant la généralisation d’ici la fin de l’année des « AI Overviews » (connus auparavant sous le nom de SGE), sous la forme d’une interface qui fournira des synthèses de réponses directement sur la page des résultats de recherche. Ce qui aura un impact considérable sur l’audience des sites, surtout dans certains domaines.
Pour autant, les débuts ne sont pas faciles : le lancement des AI Overviews a suscité récemment de nombreuses critiques des utilisateurs mécontents de réponses inexactes.
De façon plus générale, il est certain que les IA génératives vont avoir un impact sur l’évolution des interfaces utilisateurs. Par exemple, la navigation classique pourrait être remplacée par des assistants virtuels destinés à générer des réponses ou accomplir des tâches. Le SEO classique sera également impacté : il ne suffira plus de produire du contenu pour correspondre aux algorithmes de classement, mais de faire en sorte que ses contenus soient visibles dans les réponses générées par l’IA.
Ce qui est à craindre à mon sens, c’est la prolifération de contenus sans intérêt, très standardisés (sans parler bien sûr des contenus contrefaits et faux) générés par des IA. On le constate déjà sur le web, les réseaux sociaux… et jusqu’à la production d’articles académiques.
AML : Que penser des récents développements et partenariats entre les éditeurs de contenus et les acteurs de l’IA ?
VM : Les partenariats vont se multiplier… Le partenariat entre Le Monde et OpenAI, en mars dernier, a suscité de nombreuses questions, parmi les journalistes et aussi de la part d’autres médias. Bien sûr, il y a des enjeux financiers importants… et de nombreuses négociations sont en cours actuellement entre des éditeurs de contenus et les acteurs de l’IA, dans le domaine de la presse, mais aussi du droit et d’autres contenus spécialisés.
Il est important que les IA soient entraînées avec des contenus de qualité, et qu’il y ait davantage de transparence dans les sources utilisées, mais quel sera le bénéfice pour les utilisateurs ? Et quel modèle économique ? On risque là encore de se retrouver face à un éparpillement des accès aux contenus.
AML : Avec l’intégration rapide des IA génératives dans les pratiques professionnelles, comment les personnes que vous formez vivent-elles cette transition ? et comment analysez-vous les défis pour les professionnels de l’information ?

Déjà abonné ? Connectez-vous...
Bonnes pratiques pour systématiser la surveillance de vos concurrents

Une grande partie de la veille concurrentielle repose sur une surveillance de la presse, du web ouvert et des réseaux sociaux. Mais comment s’y prendre de façon structurée et systématique sans être noyé sous l’information ? Cet article a pour objectif de rappeler aux professionnels tous les flux à identifier pour être sûrs de ne rien laisser passer tout en maîtrisant le volume à traiter.
La première étape consiste évidemment à répertorier la liste des concurrents à surveiller. Dès ce stade, prenez le temps d’associer à chaque concurrent une ou plusieurs zones géographiques.
Il peut s’agir du pays ou de la région d’origine (généralement là où se trouve le siège), mais également et surtout des zones géographiques où la société a une activité : lieux d’implantation des usines, des centres de R&D (en allant si possible jusqu’au nom des villes) et plus globalement les pays ou les régions correspondant aux marchés sur lesquels il est présent et actif.
Pourquoi est-ce important ? Tout d’abord parce que cela va permettre de cibler des sources locales et des langues spécifiques, plutôt que de surveiller tous azimuts. De plus, les acteurs évoluant à l’international peuvent offrir des déclinaisons nationales de leurs sites web et comptes sur les réseaux sociaux, qu’il conviendra éventuellement de surveiller, comme on le verra dans la suite de cet article.
Déjà abonné ? Connectez-vous...
Le jour où j’ai voulu mettre en place une veille collaborative

Mettre en place un projet de veille collaborative dans une entreprise où il n’existe pas de service veille et où les collaborateurs ont l’habitude de pratiquer une veille individuelle est un vrai challenge ! Retour sur mon expérience dans une PME, sur les succès, mais aussi les difficultés rencontrées.
De l’intérêt de mener l’enquête
Lorsque j’étais en charge de la Documentation d’un bureau d’études technique (130 personnes environ), j’ai tenté d’initier une démarche de veille collaborative avec mes collègues ingénieurs.
J’avais l’intuition que les ingénieurs faisaient de la veille dans leur coin et de mon côté, j’avais l’ambition de développer mon offre de service. Je réalisais jusque-là des activités documentaires traditionnelles (panorama de presse, gestion d’un portail documentaire…) et je souhaitais proposer un service de veille.
Avec l’accord d’un des membres du Comex auquel j’étais directement rattachée, j’ai mené une enquête quantitative auprès de l’ensemble de la société (Direction comprise) sur leurs pratiques informationnelles.
Dans le questionnaire, je demandais notamment aux répondants s’ils pratiquaient une veille et, si oui, sur quels sujets et combien de temps, ils accordaient à cette activité.
L’analyse des résultats de l’enquête m’a conduite à deux grands constats. D’une part, 65 % des répondants pratiquaient en effet une veille individuelle. D’autre part, 76 % se sont déclarés pour la mise en place d’un service de veille centralisé, avec un intérêt marqué pour une veille technique. Les domaines d’activité de ce bureau d’études évoluent vite et les ingénieurs avaient besoin d’être informés au plus vite des expérimentations technologiques, des nouveaux produits des industriels, etc.
Grâce à cette enquête, j’ai obtenu la légitimité nécessaire auprès de ma hiérarchie pour créer un service de veille.
Veille pilote et audit de l’existant
Avec l’accord de la Direction, j’ai mis en place une veille pilote sur la « route intelligente » avec un des trois Départements de la société. Cette veille concernait une dizaine d’ingénieurs-chef de projets et directeurs de projet.
Déjà abonné ? Connectez-vous...
Adopter une logique de flux… plus facile à dire qu’à faire

Le numérique a bouleversé les modèles traditionnels de gestion de l’information. Longtemps cantonnés à une approche statique avec des informations stockées sur des supports inertes, les professionnels doivent désormais appréhender un flot continu et dynamique de données. Ce virage vers une « culture de flux » implique une profonde mutation des pratiques.
La nécessité de passer d’une culture de stock à une culture de flux pour les métiers de l’information n’est pas nouvelle, pourtant elle peine toujours à être pleinement embrassée - et pleinement organisée - dans la pratique professionnelle.
En 2013, déjà, Caroline Sauvajol-Rialland, dans son ouvrage « Infobésité, comprendre et maîtriser la déferlante d’informations » (Éditions Vuibert, p.136), précisait : « en situation de surcharge informationnelle, il ne s’agit surtout pas d’archiver pour archiver et de multiplier les copies inutiles, mais de passer d’une logique de stock à une logique de flux, de passer de l’individu, qui porte la connaissance née de l’information, au collectif, qui produit de l’efficacité au sein du collectif ».
Dans la culture de stock traditionnelle, l’information est considérée comme un bien rare à accumuler et à préserver précieusement. Les connaissances sont ainsi rassemblées dans des bibliothèques, des archives ou des bases de données structurées. L’enjeu du documentaliste est ici d’organiser ces stocks pour en maîtriser l’accès et une diffusion contrôlée.
À l’inverse, la culture de flux voit l’information comme une ressource surabondante, renouvelée en continu par un afflux de données fraîches. La valeur réside alors moins dans la rétention que dans la capacité à capter, filtrer et exploiter ces flux en temps réel.
L’attention se déporte des stocks vers les canaux de diffusion dynamiques comme les réseaux sociaux ou les fils d’actualités. Dans ce cas, la donnée se consomme de manière ponctuelle et n’a souvent qu’une pertinence éphémère.
Basculer de paradigme n’est pas aisé. Cela suppose d’abandonner des réflexes ancestraux de thésaurisation pour embrasser la philosophie du flux, l’instantanéité et l’impermanence. Pour collecter, trier, hiérarchiser les informations pertinentes au sein de ces torrents de données, il devient impératif de repenser en profondeur les processus et les outils professionnels.
En termes de méthodologie, cela nous ramène à la constitution d’un « second cerveau numérique », terme popularisé par Tiago Forte qui a créé la méthode CODE (capturer, organiser, distiller, exprimer), comme nous l’avions vu dans Netsources N° 165 N° 165 - juillet/août 2023, consacré à cette problématique. Sans supprimer le stockage, ce dernier ne constitue plus qu’une première étape, sur un chemin de la connaissance qui en comporte trois autres.
Déjà abonné ? Connectez-vous...
L’art de la présentation à l’ère de l’IA pour les pros de l’info

Pour les professionnels de l’information, documentalistes, analystes ou chargés de veille stratégique, la production de présentations de grande qualité est devenue un must en termes de (re) présentation personnelle et de communication. Qu’il s’agisse de communiquer les résultats de leur veille, de leurs recherches ou de leurs activités, ils doivent choisir l’outil le plus adapté pour capter l’attention de leur audience et transmettre leur message avec clarté et efficacité.
L’irruption de l’IA dans la création de présentations
L’IA a fait irruption sur ce segment en apportant beaucoup de créativité en termes de graphisme, mais aussi de contenu. Il faut donc désormais examiner les outils de production graphique à l’aune de ces deux critères.
Avec la multiplication des outils et applications promettant monts et merveilles en matière de présentation, on peut être tenté de se précipiter sur le plus « marketé ».
Beautiful.ai : promesses et réalités
C’est ce que nous avions fait il y a plus d’un an avec Beautiful.ai, qui permet de générer une présentation à partir d’un simple prompt sur un sujet donné, prompt auquel on peut adjoindre un fichier détaillé contenant les données propres que l’on souhaite injecter dans la présentation. L’outil rapproche alors la problématique du prompt avec un certain nombre d’éléments en stock, déjà formatés (types de données et de graphes, templates, bibliothèques de visuels modernes) et génère en quelques secondes une présentation attrayante, assez proche de celles que l’on envie aux grands cabinets d’étude.
Fig.1 exemples de présentation issus du site web de beautiful.ai
Déjà abonné ? Connectez-vous...
Agilité et esprit critique : toujours plus essentiels pour les métiers de l'info (édito)

Dans une ère caractérisée par la volatilité des données numériques et le développement de l’IA dans notre sphère informationnelle, le rôle des professionnels continue de se transformer. Ceux-ci doivent affirmer toujours plus leur rôle de médiateur entre la technologie et les utilisateurs, et développer une compréhension critique des outils proposés.
La suppression du cache par Google a mis en lumière la fragilité de notre accès aux informations historiques, et marque d’une certaine façon la fin de l’ère de l’accès instantané et illimité. Elle met également en évidence l’importance qu’il y a à élaborer des stratégies d’archivage et de recherche rigoureuses pour sauvegarder les contenus numériques.
L’intégration croissante de l’intelligence artificielle dans les pratiques médiatiques modifie profondément les méthodes de travail des journalistes, mais aussi des professionnels de la veille. L’automatisation de tâches telles que la transcription de podcasts et la synthèse d’articles vise à libérer du temps pour des analyses journalistiques plus poussées. Toutefois, cela nécessite une vigilance accrue de notre part pour garantir la véracité et de qualité des informations, dont les méthodes de production deviennent parfois opaques.
Le fact-checking, autrefois domaine réservé à l’expertise humaine, bénéficie maintenant d’un coup de pouce de l’IA. Cependant, la fiabilité de ces outils de contrôle dopés à l’IA doit être constamment évaluée et testée. Nous nous retrouvons dans une situation inédite : utiliser l’IA pour contrôler l’exactitude d’autres productions potentiellement issues de l’IA elle-même.
Enfin, les agrégateurs de flux RSS, comme Inoreader, proposent de nouvelles manières de gérer notre mémoire informationnelle. Ces outils, véritables extensions du cerveau humain, permettent un accès rapide à l’information tout en exigeant une utilisation judicieuse pour éviter la surcharge d’informations et assurer la conservation de l’essentiel.
À lire dans ce numéro :
Médias + IA : la nouvelle équation à laquelle il faut s’adapter
Second cerveau digital : jusqu’où Inoreader nous aide-t-il ?
Trois actualités à picorer : fin du cache Google, consolidation du marché des outils de veille et transcription de podcasts

Google retire le cache de ses pages, où les retrouver ?
Google a récemment annoncé qu’il avait retiré le cache des pages Web dans les résultats du moteur. C’était pourtant une option bien utile quand une page ou un site n’était pas disponible.
Le cache est cependant toujours disponible si on utilise l’opérateur dédié dans la requête : cache:bases-publications.com. Mais cette fonctionnalité a aussi vocation à disparaître dans les prochains mois.
Danny Sullivan, un des porte-parole de Google a expliqué que le cache « était destiné à aider les gens à accéder aux pages quand, à l’époque, on ne pouvait souvent pas compter sur le chargement d’une page. De nos jours, les choses se sont grandement améliorées. Il a donc été décidé de le retirer. »
Heureusement, il existe plusieurs options quand on souhaite visualiser l’historique d’un site ou quand il n’est tout simplement pas disponible. La plus connue et que l’on ne présente plus est la Wayback Machine proposée par Internet Archive, même si elle est loin d’être parfaite.
Une autre solution intéressante peut consister à utiliser le site CachedView.
Le site permet d’interroger simultanément plusieurs sites d’archives du Web en l’occurrence Google Webcache (certainement plus pour longtemps), ainsi que la Wayback Machine, Archive.today, Library of Congress, Perma.cc, etc. directement intégrés dans l’outil (voir figure 1.) Le site propose même un bookmarklet à ajouter directement à son navigateur pour gagner du temps.

Figure 1. Interface de CachedView
Du mouvement sur le marché des outils de veille
Ces derniers temps, le marché des outils de veille a connu des changements importants avec notamment une consolidation du marché opérée via des rachats successifs.
- On se rappellera qu'il y a près de deux ans, Digimind avait été racheté par Onclusive, qui avait précédemment intégré Kantar Media ;
- Geotrend et Qwam ont été rachetés en 2023 par le groupe français Chapsvision qui avait déjà acquis la plateforme AMI Software par le passé. Et sur un autre secteur, Chapsvision vient également de racheter le spécialiste de la traduction Systran et Owlint, un acteur de l’OSINT.
- Hootsuite vient quant à lui d’annoncer le rachat de la plateforme luxembourgeoise Talkwalker.
- Enfin, KB Crawl a récemment acquis Iscope, un autre acteur de la veille.
On a donc aujourd’hui sur le marché français des plateformes de veille d’une part :
- Quelques très gros acteurs tels que les Américains Onclusive, Cision (qui avait racheté l’Argus de la presse, Europresse et la plateforme de social média monitoring Brandwatch au cours des dernières années), le Français Chapsvision et le Norvégien Meltwater (qui avait racheté Linkfluence en 2021). Tous ces gros acteurs se positionnent comme des plateformes de veille multifonctions : media, web et social media monitoring, dataviz, etc.
Déjà abonné ? Connectez-vous...
Médias + IA : la nouvelle équation à laquelle il faut s’adapter

L'intelligence artificielle révolutionne le paysage médiatique en introduisant de nouvelles fonctionnalités telles que des résumés automatisés, des podcasts générés par l'IA, la traduction de contenu et des chatbots.
Si ces outils peuvent aider les professionnels de l'information à gagner du temps et à améliorer l'expérience utilisateur, ils ne remplacent pas le jugement et l'expertise humains. Il est crucial pour ces professionnels de s'adapter à ces changements en développant de nouvelles compétences et en se concentrant sur des tâches à plus forte valeur ajoutée pour rester pertinents dans l'ère de l'IA.
L’IA fait progressivement son chemin dans les produits, sites et contenus proposés par les médias en France et à l’international. Si en 2023, il s’agissait surtout de tests et de pilotes, en 2024, le nombre d’initiatives notables ne cesse de croître.
De plus en plus de médias ajoutent un court résumé au début des articles, les principaux points clés de l’article à retenir.
Et ceci est dans la plupart des cas généré grâce à de l’IA générative. Numerama le propose par exemple dans sa version payante. D’autres utilisent la génération de résumé cette fois-ci pour les commentaires des articles : c’est par exemple ce que propose l’Équipe depuis peu.
Quelles conséquences pour le pro de l’info ?
Cela peut permettre de déterminer plus rapidement si un article est pertinent ou non pour sa veille ou sa recherche sans avoir à lire tout l’article dans le détail ou en diagonale.
La recherche d'optimisation : les articles à faible valeur ajoutée.
On voit également des témoignages de médias qui utilisent l’IA pour la rédaction d’articles à faible valeur ajoutée (résultats de matchs, bâtonnage de dépêches, etc.) ou des tâches traditionnellement dédiées au secrétaire de rédaction (corrections, amélioration des titres, etc.).
D’autres vont même encore plus loin avec pour l’IA un rôle d’assistant de revue de presse ou de créateur de newsletters thématiques.
Semafor s’est ainsi associé avec Microsoft et OpenAI pour proposer un fil d’information basé sur l’agrégation de différentes sources. Les journalistes sélectionnent les sujets, l’IA propose différentes sources (différentes langues, pays, points de vue contradictoires), les journalistes évaluent les contenus retrouvés et écrivent eux-mêmes les résumés.
Autre exemple : la newsletter Artificielles proposée par Numerama. À partir du flux RSS associé au tag « IA » des articles de Numerama, l’IA extrait les 15 derniers articles et choisit les six qu’elle juge les plus importants. Elle se charge ensuite de proposer un titre, un résumé, un émoji et un lien vers l’article complet. Le contenu est ensuite vérifié et validé par des humains avant envoi.
Quelles conséquences pour le pro de l’info ?
Déjà abonné ? Connectez-vous...
Second cerveau digital : jusqu’où Inoreader nous aide-t-il ?

Inoreader est un agrégateur de flux RSS connu des professionnels de la veille qui sont particulièrement concernés par l’idée de se constituer un « second cerveau ». Ce dernier est capable de mémoriser l’information importante tout en facilitant sa disponibilité pour l’utiliser quand cela s’avère nécessaire. Jusqu’où et comment cet outil de veille peut-il contribuer à cette démarche ? Voici une méthode pas à pas.
L’idée de se construire un « second cerveau » digital, sorte d’externalisation de sa mémoire informationnelle est ancienne. Elle a été popularisée récemment avec succès par Tiago Forte (voir à ce sujet les articles de Netsources N° 165 - juillet/août 2023). Sa démarche se divise en quatre étapes, réunies sous l’acronyme CODE : Capturer, Organiser, Distiller et Exprimer.
Lire aussi :
Que valent les outils de reconnaissance faciale pour la veille image ou l’investigation ? (Bases N°414 - mai 2023)
La veille et la recherche d’information à l’ère des « fake news » et de la désinformation (Netsources N°140 - mai/juin 2019)
Tirer parti du fact-checking et du journalisme d’investigation pour la veille et la recherche d’information (Netsources N°140 - mai/juin 2019)
Entre l’utilisation de l’extension d’Inoreader pour mettre de côté ses articles (voir Figure 1) et la possibilité de surligner et d’annoter ses articles avec Inoreader, il semble ainsi possible de faire l’ensemble de la chaîne de la méthode CODE avec ce seul et même outil. Pour découvrir ce qu’il en est réellement, nous disposons de la version Pro d’Inoreader (6,67€/mois). Elle permet, contrairement aux deux autres versions, Gratuite et Supporter, de surligner les articles, de faire une recherche globale dans « tous les articles publics » (c’est-à-dire dans la base de données d’Inoreader et pas seulement au sein de ses propres feeds) mais aussi d’utiliser IFTTT et Zapier intégrés si besoin dans les options de connexion (il n’y a plus qu’à les sélectionner et à les activer).
Capturer
Capturer, dans la méthode Code, c’est collecter l’information « au feeling », la mettre de côté sans trop réfléchir. Inoreader propose depuis des années à ses utilisateurs la fonctionnalité « À lire plus tard ». Et elle peut être utilisée de deux façons différentes.
Premièrement, au sein d’Inoreader. Les articles « Lire plus tard » sont installés par défaut dans la barre latérale de gauche et intégrés aux « Dossiers système ». On les collecte en un clic, lors de la consultation de sa veille ou d’une navigation web, sur un PC ou sur un mobile. Sur son ordinateur, l’extension Inoreader permet de collecter un article en cliquant sur l’icône et en choisissant « Lire plus tard » (voir Figure 1). Sur son mobile, l’appli permet d’utiliser un clic droit ou les fonctionnalités de partage pour classer son article dans le dossier « à lire plus tard ».
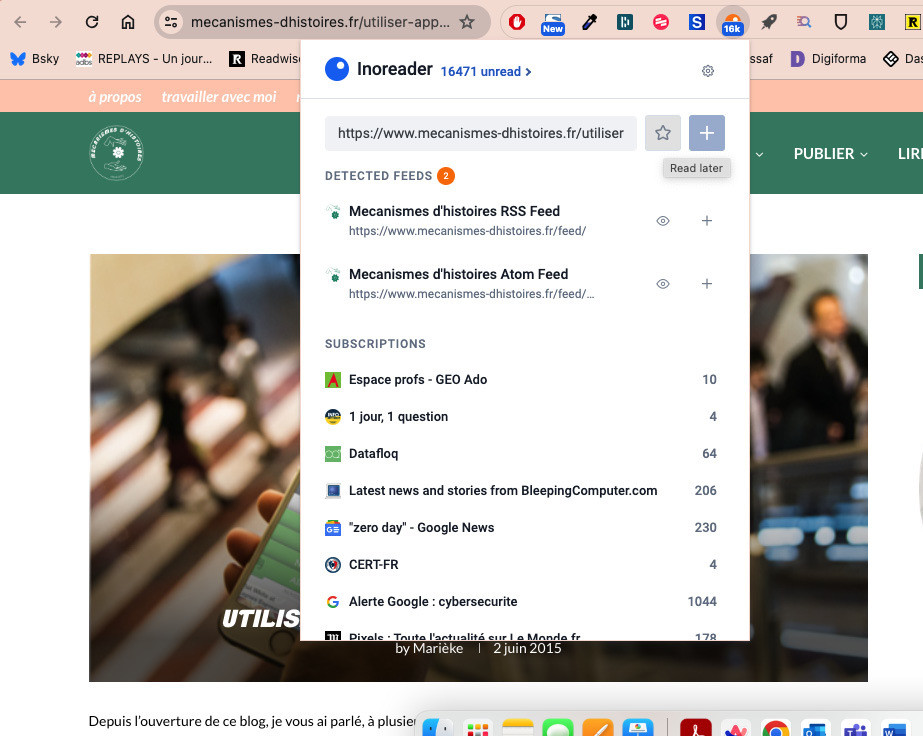
Figure 1. Avec l'extension Inoreader, on peut mettre de côté des articles consultés en ligne en un clic.
On retrouve les articles ainsi mis de côté dans son tableau de bord et dans son dossier « Lire plus tard ». Enfin, cette fonctionnalité est gratuite.
Deuxièmement, on peut aussi synchroniser les articles collectés avec Pocket, l’un des outils recommandés par Tiago Forte pour la phase de Capture. Mais si l’idée est de fluidifier et d’automatiser au maximum la gestion de l’information, exporter ses articles dès la première étape dans un autre outil n’est sans doute pas optimal. De plus, s’il est possible sur Pocket d’organiser ses informations gratuitement, les phases suivantes pour se constituer un second cerveau - telles que le surlignage, la recherche, ou la connexion à un outil de gestion de notes comme Notion (via Zapier), ne sont accessibles qu’à partir de 40 €/an. Or, ces fonctionnalités sont présentes dans la « Bibliothèque » d’Inoreader.
Organiser
Par défaut les articles sont préorganisés et accessibles dans l’ensemble des dossiers suivants (voir Figure 2) :
- « À lire plus tard » ;
- La Bibliothèque pour les articles « Commentés », « Annotés », « Aimés », ou « Pages web Enregistrées » (voire « Récemment Lus »)
- Les Étiquettes, pour les articles tagués.
La méthode d’organisation de Tiago Forte a été popularisée sous le nom de PARA. Il s’agit d’organiser ses dossiers en suivant l’ordre de ce nouvel acronyme qui signifie : Projets (à court terme), Areas (domaines à long terme), ressources (où stocker les articles en attente de tri) et Archives (pour les articles concernant des projets inactifs).
Déjà abonné ? Connectez-vous...




















