Sélectionner le numéro de "Bases" à afficher
Bases de données brevet en accès libre : Espacenet versus Patentscope, peut-on choisir ?


La documentation brevet constitue une source inestimable d’information pour établir une veille technologique et concurrentielle, ou même évaluer la valeur d’une entreprise. Au moins une vingtaine de bases de données brevet totalement ou partiellement gratuit sont désormais disponibles sur le WEB. S’il est difficile d’établir une hiérarchie entre elles, deux produits se détachent du lot : Espacenet, produit par l’Office Européen des Brevets, et Patentscope de l’OMPI (Organisation Mondiale de la Propriété Intellectuelle). Quel produit choisir, et faut-il choisir ?
Espacenet, Patentscope : le contenu
Le contenu d’une base de données brevet se décline en plusieurs éléments : offices couverts, sur quelle période, pour quelles données (données bibliographiques, texte intégral, etc.), et avec quel délai de disponibilité.
La couverture des deux services fait l’objet de pages Web dédiées régulièrement mises à jour.
Patentscope annonce couvrir 79 offices, et Espacenet 104 concernant les informations bibliographiques et 68 concernant le texte intégral. Toutefois, pour certains offices la couverture est très partielle, ou les mises à jour plus ou moins tardives, allant jusqu’à plus d’un an de délai à compter de la date de publication. Hors de ce cas de figure, on tombe côté Espacenet à 70 offices couverts pour les données bibliographiques et 33 pour les données de texte intégral ; côté Patentscope on arrive à 55 offices dont la couverture est régulière concernant les informations bibliographiques. ; par rapport au texte intégral, les plages couvertes n’étant pas précisées, seul le nombre de documents OCRisés l’étant, il est difficile de conclure.
Au vu des chiffres disponibles, et nonobstant quelques lacunes informationnelles, certaines différences non spectaculaires peuvent être notées concernant les six offices essentiels (Européen, Américain, Chinois, Japonais, Coréens et l’OMPI). Patentscope ne couvre pas les documents japonais antérieurs à 1964, là où Espacenet couvre à partir de 1961 pour les documents A (correspondant à la demande de brevet), et 1926 pour les B (correspondant au brevet délivré). On a aussi 2,5 ans supplémentaires de documents coréens de type Y sur Espacenet. Concernant les US, la période 1790 - 1835 est affichée comme disponible sur Patentscope. Mais cette période ne correspond à l’interrogation qu’à 1659 documents, et les données disponibles sont souvent très parcellaires.
Sur la partie données en texte intégral, Espacenet a un léger avantage, un doute subsistant toutefois quant à l’OCRisation des textes en question.
Pour ce qui concerne les autres offices, rien de très marquant mis à part un +Patentscope sur les documents néo-zélandais.
Les délais de mise à jour
En termes de délais de mise à jour, et si l’on reste sur les offices essentiels, on constatait début janvier 2024, pour les données bibliographiques, un délai oscillant entre 0 - demandes européennes - et 2,7 semaines - documents coréens - sur Espacenet, et entre 0 - demandes PCT (Patent Cooperation Treaty, gérées par l’OMPI) - et trois semaines - documents japonais, coréens, chinois - sur Patentscope. Pas de différence spectaculaire donc.
Pour les autres offices importants, les délais sont variables : près de cinq semaines pour les documents autrichiens, trois semaines pour les Suisses, mais seulement une pour les Australiens sur Espacenet, avec des pointes à seize semaines pour les documents bulgares, et dans l’autre sens, moins d’une semaine pour les Allemands, les Danois, les Espagnols, les Français, entre autres. La situation n’est pas très différente sur Patentscope.
Les données de texte intégral sont mises à jour sur Espacenet à peu près dans les mêmes délais que ceux cités ci-dessus pour les offices EP, WO, US, CN, JP et KR. Pour les autres offices, la situation est très diversifiée : il faut deux ans et demi pour voir apparaître le texte intégral des documents autrichiens, mais moins d’une semaine pour les documents australiens. On prendra donc garde à ce point lorsque l’on effectue par exemple des recherches dans le texte intégral (description et/ou revendications)
L’information sur le délai de mise à jour du texte intégral n’est pas disponible pour Patentscope.

Déjà abonné ? Connectez-vous...
Dark et Shadow Social : nouvelles frontières de la veille

En septembre dernier, nous évoquions la question de la veille sur les réseaux sociaux, qui depuis le déclin de X (Twitter) devient de plus en plus fragmentée (cf. La veille sur les réseaux sociaux s’annonce de plus en plus fragmentée, Bases N° 417 - sept 2023). Si cette question subsiste et continue à rendre la veille sur les réseaux sociaux toujours plus complexe et chronophage, ce n’est pas la seule difficulté à laquelle est aujourd’hui confronté le veilleur.
L’autre dimension à prendre en compte, c’est l’essor du dark social depuis quelques années et du shadow social, nouvelle tendance théorisée par Marie Dollé en ce début d’année.
C’est un fait aujourd’hui bien documenté, les internautes partagent de moins en moins de contenus de manière publique sur les réseaux sociaux et ont plutôt tendance à se reporter sur des espaces plus restreints composés de leurs proches, cercles d’amis ou communautés qui se rassemblent autour d’intérêts communs.
Sur les réseaux sociaux, il existe donc des espaces privés et fermés que l’on appelle le dark social et des espaces à mi-chemin entre le public et le privé que Marie Dollé appele le shadow social et qui ne cessent de prendre de l’ampleur.
On aurait tort de se priver de cette face cachée des réseaux sociaux pour sa veille et ses recherches d’information. Mais comment identifier ces espaces et les intégrer à sa veille ?
Lire aussi :
La veille sur les réseaux sociaux s’annonce de plus en plus fragmentée (Bases N° 417 - sept 2023)
Comment utiliser Discord pour ses veilles et ses recherches ? (Bases N° 417 - sept 2023)
Veille Instagram : quoi, comment, pour quoi faire ? (Netsources N° 158 - mai/juin 2022)
Réussir à utiliser LinkedIn pour la veille et la recherche d’information (Netsources N° 158 - mai/juin 2022)
Que sont le dark social et le shadow social ?
Le dark social
Qu’on se rassure, le dark social n’a rien à voir avec le dark web et d’éventuels contenus et pratiques illicites. La comparaison est plutôt à chercher du côté du Web visible et invisible et sa fameuse image d’iceberg, car le dark social représente la partie immergée et donc invisible des réseaux sociaux.
Le dark social, ce sont donc ces espaces privés sur les réseaux sociaux où les internautes communiquent, partagent des contenus, mais qui ne sont pas référencés par les moteurs de recherche Web ou internes aux réseaux sociaux et sont donc invisibles aux non-membres.
Cette tendance peut s’expliquer par plusieurs facteurs : une quête d’authenticité, un plus grand besoin d’intimité, une fatigue des attaques et clashs incessants sur les réseaux sociaux, une réaction face à l’infobésité et au burn-out informationnel. Les Anglo-saxons parlent ainsi du passage d’un concept de One-to-many où une personne s’adresse à une très large audience publique à celui de One-to-one ou One-to-few avec des contenus et du partage d’information destinés à une personne ou un petit groupe d’individus.
Dans un récent article de Business Insider intitulé « Great news - social media is falling apart », le journaliste illustre parfaitement cela en expliquant que « nous sommes passés d’un Internet qui ressemblait à une sortie au centre commercial à un Internet plus semblable à une soirée entre amis. »
Déjà en 2017, une étude réalisée par la plateforme de publicité programmatique RadiumOne annonçait que 84 % des partages que font les consommateurs « se font maintenant sur des canaux sociaux privés comme les e-mails et les messageries instantanées ». Si le chiffre peut paraître très élevé (la même année, Talkwalker avait mené un test similaire et estimait que 20 % du trafic vers leur site venait du dark social), il n’en reste pas moins qu’il existe bien une face cachée des réseaux sociaux et qu’elle ne cesse de prendre de l’ampleur.
À l’été 2023, Adam Mosseri, qui est à la tête d’Instagram, expliquait dans une interview que le flux public des internautes était devenu secondaire et que c’était la messagerie (surtout) et les stories (dans une moindre mesure) qui étaient le moteur de croissance d’Instagram depuis au moins cinq ans.
Le dark social est donc aujourd’hui le fonds de commerce des réseaux sociaux et il y a toutes les chances d’y trouver des pépites informationnelles. Mais il ne faut pas négliger non plus le shadow social.
Le shadow social
Le concept de shadow social est quant à lui plus récent et s’annonce comme une des tendances de 2024. La première fois que nous l’avons vu apparaître c’était dans la newsletter Futur(s) sous la plume de Marie Dollé. Elle décrit le shadow social comme « un espace hybride situé entre le public et le “dark social”. Le shadow social représente une évolution significative dans notre manière de percevoir l’identité et les relations en ligne, équilibrant le privé et le public, l’individuel et le collectif. Il se positionne comme une réponse stratégique au content shock croissant, exacerbé par l’augmentation des contenus générés par l’IA. Plus encore, il représente pour les plateformes sociales une opportunité de stimuler l’engagement au sein de leurs écosystèmes. »
Elle cite en exemple les Broadcast Channels sur Instagram qui permettent des échanges directs entre les créateurs de contenus et leurs abonnés ou encore les articles collaboratifs sur LinkedIn et leurs commentaires. On est alors plus proche du « one to few » évoqué plus haut dans cet article.
Dans la même veine, on pourra également penser au lancement récent des chaînes WhatsApp qui prennent beaucoup d’ampleur notamment au niveau des médias ou encore aux nouveaux canaux de diffusion récemment lancés sur Facebook et Messenger.
Et même si c’est moins évident, on pourrait inclure dans le monde du shadow social les newsletters, qui sont de plus en plus prisées : Il s’agit en effet d’espaces semi-privés (qu’il faut réussir à identifier et auxquels il faut s’abonner pour visualiser le contenu), avec une personne qui s’adresse à une communauté restreinte. De plus, les newsletters ont des frontières poreuses avec les réseaux sociaux qui avaient développé pour la plupart des systèmes de newsletters intégrés (GetRevue sur Twitter par exemple), mais ces fonctionnalités ont plutôt tendance à disparaître. Parallèlement, les plateformes de newsletters se transforment peu à peu en réseaux sociaux dédiés aux newsletters : Substack a par exemple développé son propre réseau social appelé Substack Notes.
Attention : Si le développement du shadow social semble être une des tendances de 2024, ce n’est pas pour autant complètement nouveau. Les groupes privés/sur invitation des réseaux sociaux existent depuis des années, mais ont pour la plupart périclité pour devenir des espaces publicitaires et d’autopromotion : Telegram propose des chaînes depuis déjà plusieurs années, les serveurs Discord existent aussi depuis un moment mais gagnent en popularité, etc.
Les nouveaux produits et fonctionnalités que l’on voit apparaître ces derniers mois, révèlent un glissement d’un schéma d’espace communautaire composé d’un petit groupe de personnes où chacun peut s’exprimer, vers une communication à sens unique où une personne communique vers une audience restreinte. Les membres sont limités à des rôles de lecteurs et peuvent au mieux réagir avec des emojis comme c’est le cas sur les chaînes WhatsApp par exemple.
Les espaces de shadow social donnent finalement l’impression de faire partie d’un club un peu sélect. Certains restreignent même volontairement le nombre de membres, c’est par exemple le cas de la newsletter Pygmalion qui est limité à 200 abonnés (au-delà, les gens sont sur liste d’attente et patientent jusqu’à ce que quelqu’un se désabonne).
Quelle répercussion pour la veille ?
Faire de la veille sur le Web, c’est réussir à identifier les meilleures sources et les informations en lien avec ses thématiques. On sait depuis toujours que ces sources et informations sont en partie sur le Web invisible, mais on réalise désormais qu’elles peuvent se trouver dans des espaces de dark social ou de shadow social qui prennent une place de plus en plus importante dans le paysage.
On a tout intérêt à investiguer dans cette direction pour ses veilles et ses recherches, mais comment réussir à identifier ces espaces qui n’ont pas pignon sur rue, s’y faire inviter quand l’espace nécessite une validation et comment les mettre sous surveillance ? Tout en sachant qu’ils ne sont généralement pas inclus dans les outils de recherche et de veille classiques et pas nécessairement indexés par les moteurs de recherche ou en tout cas peu valorisés.
Déjà abonné ? Connectez-vous...
FOCUS IA : générer un quiz en moins d’une minute

Pour rendre un livrable et une formation efficaces en vérifiant le niveau de compréhension de son public ou tout simplement pour rajouter une touche de divertissement, le quiz est un outil pédagogique qui peut s’avérer un précieux allié. Et aujourd’hui avec les modèles d’IA générative, un quiz peut être créé en une minute, ou presque. Florilège de nos 4 outils préférés.
Opexams, un quiz gratuit par jour
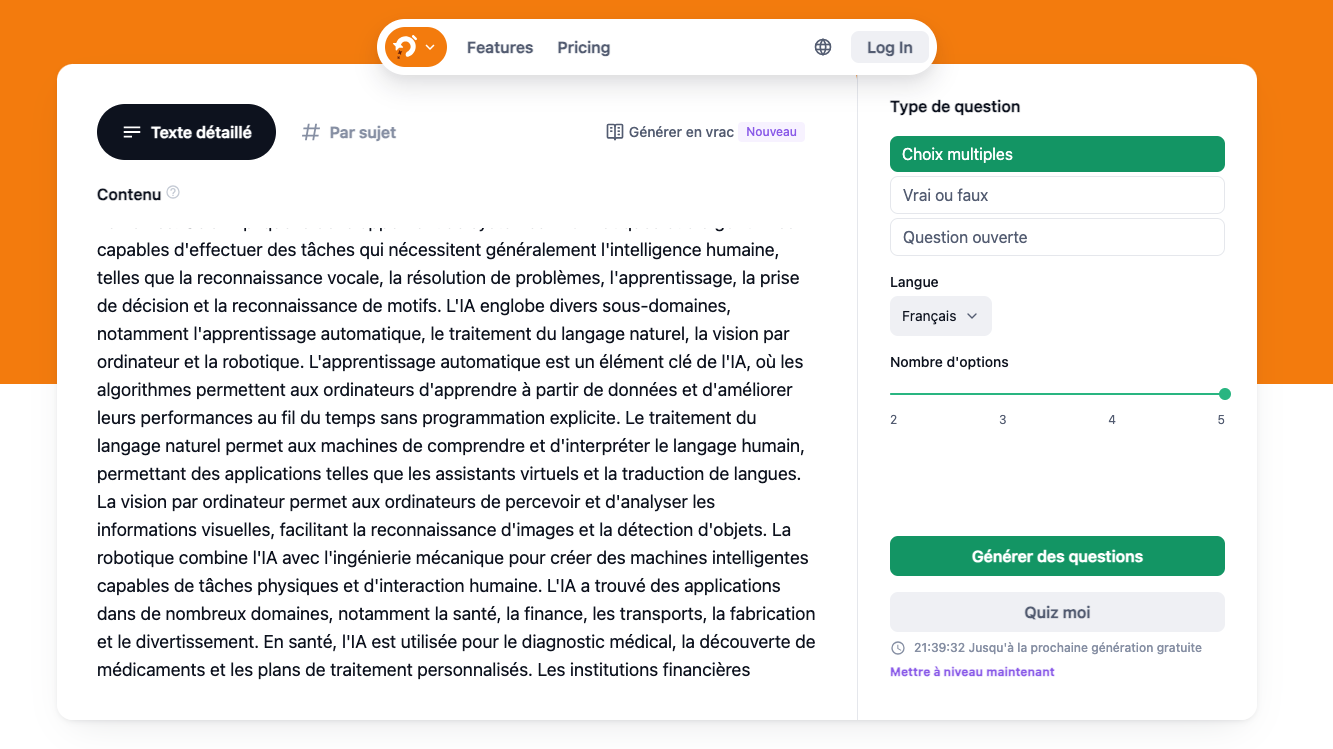
Opexams est une plateforme pédagogique qui propose la génération de quiz parmi d’autres fonctionnalités.
Son « Quiz Generator » est accessible sans inscription. Le quiz est généré à partir d’un texte à fournir (jusqu’à 3000 signes environ) et, comme toujours avec ces outils IA, le procédé est simplifié au maximum : on copie son texte, puis on sélectionne les options suivantes : le type de quiz (choix multiples, vrai/faux ou questions ouvertes), la langue, le nombre d’options par question (cinq maximum), puis on clique sur « Générer un quiz ».
L’option « par sujet » permet d’entrer uniquement un thème de son choix, qu’il soit dans le domaine scolaire ou professionnel. Aux options précédentes, s’ajoute le niveau de difficulté souhaité (facile/moyen/difficile).
Le résultat est composé de dix questions avec les réponses apparentes. Il est possible de les copier, soit une par une avec le bouton sous chaque question, soit la totalité avec le bouton à droite de la première question.
Dans tous les cas, vérifier les réponses et ne pas hésiter à modifier la proposition de quiz. Dans notre test, 1 réponse sur 10 était fausse, avec ou sans texte comme matériau de départ.
La version gratuite permet de générer un quiz de dix questions par jour. La version payante, elle, offre un nombre de quiz illimité, l’export des questions en Word et en Excel, l’import de document-source y compris en PDF et le stockage des quiz dans une « collection ». Elle permet aussi de générer un quiz à partir de plusieurs documents et formats (par exemple, deux liens et un PDF). Le premier prix est à 6,99 € TTC.
Déjà abonné ? Connectez-vous...
STN : Des stratégies astucieuses pour la recherche brevet

Après la période de vide laissé par le départ en retraite de Martine Michel, CAS (Chemical Abstracts Services qui gère STN en collaboration avec FIZ Karlsruhe) vient de recréer son équipe en charge de la France.
Cette nouvelle équipe a organisé une réunion en présentiel, ce qui n’était pas arrivé depuis fort longtemps.
Cette réunion était centrée sur la chimie et les brevets. Les autres banques de données présentes sur STN seront, quant à elles, évoquées lors d’une prochaine rencontre.
Cette réunion a été marquée par la présentation de nombreux exemples détaillés très intéressants concernant diverses problématiques. Ce fut l’occasion d’illustrer la puissance du langage de requête Messenger utilisé par STN dont la contrepartie est une certaine complexité qui n’a, cependant, rien d’insurmontable.
L’exemple d’une recherche liée au brevet unitaire
Les recherches autour du brevet unitaire ont fait l’objet d’une présentation particulièrement dynamique.
Le brevet unitaire est entré en vigueur le 1er juin 2023. Il permet, en un seul dépôt, de couvrir les 17 pays qui ont ratifié l’accord relatif à la JUB (Juridiction Unifiée du Brevet) ce qui permet une économie de temps et d’argent.
Les bases de données de STN référençant ces brevets unitaires sont CAPlus (Chemical Abstracts qui propose des références de brevets et d’articles scientifiques), DWPI (Derwent), INPADOC (International Patent DOCumentation DataBase) et EPFULL (les brevets européens en texte intégral depuis l’origine).
Par exemple, pour identifier les brevets européens à effet unitaire déposés par une entreprise on utilisera la banque de données INPADOCDB connue pour son indexation très détaillée des évènements juridiques relatifs à la vie d’un brevet. Cette dernière fait apparaître les documents un à un tandis que INPAFAMB les regroupe par familles, sachant que les mêmes informations sont disponibles dans les deux bases.
Déjà abonné ? Connectez-vous...
Les nouvelles promesses de la recherche multilingue en action

Cela fait des années que l’on entend parler de Cross-Language Information Retrieval (CLIR) pour la recherche d’information. Il s’agit de la capacité à rechercher dans une langue et à recueillir des résultats dans d’autres langues. Jusqu’à maintenant, les produits ou fonctionnalités de ce type étaient rares et n’ont jamais véritablement décollé, à l’instar de la fonctionnalité proposée par Google de 2007 à 2013.
Et pourtant, il y a là un vrai besoin notamment pour les professionnels de l’information : dans un monde globalisé, il est en effet souvent nécessaire d’élargir à des sources en anglais (ce qui est souvent gérable), mais aussi à des sources dans des langues dont on ne maîtrise pas toujours les rudiments.
Si on peut malgré tout à mettre en place un système qui fonctionne en s’aidant de dictionnaires et d’outils de traduction, le processus reste long et fastidieux (voir Netsources N°163 - avril 2023 consacré à la veille multilingue).
Lire aussi :
Sourcing, de la théorie à l’épreuve de la pratique (Netsources N° 146 - mai/juin 2020)
Les nouvelles dimensions du multilinguisme pour la veille (Netsources N° 163 - mars/avril 2023)
Veille multilingue : comment trouver ses mots ? (Netsources N° 163 - mars/avril 2023)
Veille internationale : comment trouver des sources en langue étrangère ? (Netsources N° 163 - mars/avril 2023)
Comprendre les résultats de sa veille multilingue en un clin d’œil (Netsources N° 163 - mars/avril 2023)
Comment l’IA enrichit les livrables de veille multilingue ? (Netsources N° 163 - mars/avril 2023)
L’idéal dans cette situation serait de rechercher dans sa langue ou en anglais et de récupérer les contenus publiés dans d’autres langues, mais traduits en anglais ou français pour les analyser.
Bonne nouvelle : cela existe déjà, et c’est même en train de prendre de l’ampleur.
La recherche multilingue dans la théorie
Tirer parti de l’indexation
La première façon de rechercher des contenus dans des langues qu’on ne maîtrise pas forcément est de tirer parti de l’indexation (thésaurus, vocabulaire contrôlé, ontologies, etc.), ce qui existe depuis longtemps. Dans certains outils de recherche, notamment professionnels (agrégateurs de presse, bases de données, etc.), les articles et documents peuvent être indexés avec des mots-clés : nom de société, nom de personne, noms de lieu, thème de l’article, etc. L’utilisateur peut ensuite repérer dans sa langue les termes d’indexation adaptés à sa recherche puis les utiliser dans sa requête et voir apparaître des résultats pertinents dans des langues autres que l’anglais ou le français.
C’est par exemple le cas sur Factiva avec l’indexation sujet où il est possible, par exemple, de lancer une recherche sur le thème des insurtechs sur des contenus en langue chinoise, sans entrer un seul mot en chinois. Cependant, les résultats s’affichent bien sûr en chinois et il faut passer la liste des résultats dans un outil de traduction pour en déterminer la pertinence.
Il existe également d’autres limites à la recherche multilingue par l’indexation : tous les outils de recherche professionnels ne proposent pas de système d’indexation et quand ils le font, leurs termes ne répondent pas toujours parfaitement au besoin informationnel.
Le Cross-Language Information Retrieval (CLIR)
La deuxième façon de chercher des contenus dans une langue autre que celle de la requête relève du Cross-language information retrieval (CLIR). Si cette discipline est étudiée depuis des dizaines d’années, il n’y a pas eu beaucoup d’applications commerciales jusqu’à présent.
Plusieurs approches ont été étudiées au cours des années :
- Traduire la requête initiale dans différentes langues pour que cela matche avec des contenus dans d’autres langues ;
- Traduire tous les contenus du corpus dans une langue commune (souvent l’anglais) pour que l’utilisateur puisse ensuite lancer toutes ses recherches dans la même langue.
On notera que la traduction utilisée dans ces systèmes peut être humaine, complètement automatique ou bien hybride.
La recherche multilingue dans la pratique
En 2007, Google avait lancé une fonctionnalité de ce type. Le service reposait sur la traduction automatique des contenus mais a été retiré en 2013 car pas assez utilisé. Il faut aussi admettre qu’à cette époque la qualité de la traduction automatique laissait franchement à désirer.
Déjà abonné ? Connectez-vous...
L’arrivée de l’IA dans la panoplie d’outils des veilleurs et documentalistes

Si 2023 a été l’année de ChatGPT et de la déferlante de nouveaux outils dopés à l’IA générative, 2024 sera celle de l’intégration de l’IA générative dans les outils traditionnels du pro de l’info. Explorez avec nous les diverses innovations des acteurs traditionnels en matière d’IA et interrogeons-nous sur la pertinence de délaisser les outils IA de la cuvée 2023 au profit des outils classiques.
En 2023, l’arrivée de ChatGPT et de l’IA générative a conduit les professionnels de l’information à adapter leur arsenal d’outils pour marier habilement les outils traditionnels (qu’ils soient grand public, tels que les moteurs de recherche Web, ou spécialisés, tels que les outils de veille et bases de données) avec les nouveaux outils boostés par l’IA générative (résumés automatiques, assistants IA, dialogues avec des PDFs ou vidéos, etc.).
Aujourd’hui, c’est cette même panoplie traditionnelle qui intègre progressivement des fonctionnalités d’IA générative, avec des annonces nombreuses et difficiles à suivre.
Lire aussi :
La vague d’outils IA pour l’Information Scientifique et Technique (IST), Bases N° 420 - déc 2023
Les clés pour s’approprier l’IA dans son métier de veilleur, Netsources N° 164 - mai/juin 2023
Revue des moteurs de recherche à l’heure de ChatGPT, Bases N° 413 - avril 2023
Cette nouvelle étape dans le déploiement de l’IA n’a finalement rien de très surprenant ; c’est même un schéma classique dans le cycle de l’innovation :
- L’innovation fait son apparition, incarnée par un acteur principal qui « dégaine » en premier et qui éclipse tous les autres acteurs sur le même créneau selon la fameuse théorie du « Winner takes it all » (ici OpenAI avec ChatGPT).
- Certains acteurs classiques et directement concurrents lancent rapidement un produit pour ne pas se laisser distancer (à l’image des assistants IA de Google, mais aussi des moteurs de recherche Web qui ont tous vu en ChatGPT une menace directe pour le marché du Search). À noter que ces acteurs ne partaient généralement pas de 0 et travaillaient sur l’IA générative depuis longtemps, comme Google.
- Un nombre incalculable de nouveaux acteurs lancent de nouveaux produits utilisant cette innovation soit sur le même créneau que le précurseur (des assistants IA multifonctions) soit sur des angles particuliers pour se démarquer (les outils IA spécialisés images, spécialisés résumés automatiques et dialogue avec des PDFs, uniquement cartes mentales, etc.).
- Les acteurs classiques restent en position d’observateur avant de décider de leur prochain mouvement puis finissent pas se lancer dans la bataille et intégrer l’innovation en question à leurs produits.
Et c’est exactement à ce moment charnière que nous nous trouvons actuellement.
La vague de nouveaux outils IA est en train de retomber. C’est quelque chose que nous pouvons aujourd’hui mesurer lors de la veille que nous menons sur les lancements de nouveaux outils IA avec toujours quelques nouvelles annonces de lancement, mais nettement moins chaque semaine. Et c’est tant mieux, car il était devenu compliqué de suivre toutes les nouveautés…
À l’inverse, les outils traditionnels du professionnel de l’information (outils de veille, moteurs académiques, réseaux sociaux, bases de données, etc.) enchaînent les déclarations et annonces de nouvelles fonctionnalités d’IA en ce début d’année.
Nous avons donc décidé dans cet article de faire un tour d’horizon des différentes annonces afin d’avoir une vision globale de ce que les outils traditionnels du pro de l’info ont aujourd’hui à offrir comme fonctionnalités dopées à l’IA. Nous nous interrogerons ensuite sur les avantages et inconvénients à recourir à ces fonctionnalités d’IA intégrées par rapport à des outils comme ChatGPT ou des outils IA spécialisés.
Tour d’horizon des innovations IA dans les outils traditionnels
La panoplie d’outils des professionnels de l’information est généralement vaste et inclut à la fois des outils grand public utilisés dans une perspective professionnelle (comme les moteurs de recherche Web, les navigateurs, les réseaux sociaux, les outils de bureautique, les banques d’images, les outils de création graphiques, etc.) mais aussi des outils professionnels spécialisés (comme les outils de veille, les outils de recherche IST, les serveurs, bases de données, agrégateurs de presse, etc.).
Ce sont les outils grand public qui ont ouvert en premier leurs portes à l’IA générative. Regardons donc plus en détail ces nouveautés.
Une première vague d’intégration IA dans les outils grand public
Les moteurs de recherche ont, les premiers, intégré des fonctionnalités d’IA sous la forme d’assistant venant se greffer sur le moteur.
Voir notre article « Revue des moteurs de recherche à l’heure de ChatGPT », Bases N° 413 - avril 2023.
La plupart de ces assistants existent toujours et on notera l’apparition récente d’un petit nouveau cette fois-ci adossé au moteur Ecosia. L’acteur a en effet récemment annoncé le lancement d’un chatbot IA « vert » basé sur l’API d’OpenAI. Il est pour l’instant en version bêta et n’est pas encore disponible en France.
De nombreux autres outils grand public ont ensuite fait de même comme les navigateurs, outils de bureautique, création de visuels, etc.
Commençons par les navigateurs.
Chrome a lancé sa propre fonctionnalité d’IA (en plus des nombreux plug-ins et extensions d’IA proposées par des développeurs). Brave a quant à lui présenté Leo, une IA conversationnelle qui permet notamment de résumer la page sur laquelle on se trouve, de poser des questions sur le contenu de la page ou de faire de la traduction. Le navigateur Arc propose également une fonctionnalité de ce genre (voir notre article « ARC Browser réinvente la navigation en ligne », Bases N°420 - déc 2023).
Les outils de productivité et de bureautique ne sont pas en reste.
C’est le cas de Microsoft avec son IA Copilot intégrée à Microsoft 365 ou encore Duet AI intégrée à Google Workspaces. Dans les 2 cas, ces fonctionnalités ont un coût important, car facturées 30 $/mois et par utilisateur, ce qui peut vite représenter un budget conséquent dès que l’entreprise est d’une taille importante. Du côté des tableurs, Airtable a lancé Airtable AI, permettant aux entreprises de développer et de déployer des applications d’intelligence artificielle générative pour les flux de travail et la productivité des entreprises.
Dropbox a quant à lui lancé Dropbox Dash et Dropbox AI qui permettent pour le premier une recherche universelle dopée à l’IA dans l’ensemble des contenus, outils et apps de l’utilisateur et pour l’autre, offre des fonctionnalités de résumé automatique pour n’importe quel document.
Les réseaux sociaux introduisent aussi progressivement des fonctionnalités d’IA générative :
X a fait le choix d’une IA conversationnelle (Grok) sur le même créneau génératif que ChatGpt, mais réservée pour l’instant aux abonnés premium plus aux États-Unis.
Du côté de Meta, l’entreprise a commencé à intégrer son IA conversationnelle Meta AI dans ses différents produits comme Facebook, WhatsApp ou encore Instagram : chat avec les contenus, suggestion de commentaires, de sujets pour les groupes, aide à la description de produit pour les marketplaces, génération d’images collaboratives sur Messenger et Instagram, etc.
LinkedIn a, de son côté, introduit de l’IA générative pour l’aide à la création de messages pour les recruteurs, pour améliorer la description des profils et la création d’articles collaboratifs.
On note également de nombreux développements d'IA générative du côté des outils multimédias.
C’est le cas des outils liés à l’image comme les bibliothèques de stocks Shutterstock ou encore Getty Images ou les outils de création visuelle comme Canva ou Piktochart.
Canva propose un « Magic Studio », une suite d’IA qui convertit les créations d’un clic dans un autre format et/ou dans une autre langue (une infographie en billet de blog par exemple), de créer des visuels à partir d’un texte/prompt, d’améliorer des designs existants, etc. Dans la même veine, Piktochart permet de créer une infographie à partir d’un prompt.
Shutterstock a lancé en octobre un générateur d’IA basé sur sa bibliothèque d’images et garantissant le droit d’auteur. Getty Images a quant à lui lancé récemment un générateur d’images appelé Generative AI by iStock mêlant les images propriétaires de Getty et la plateforme d’IA générative de Nvidia. Le produit garantit la protection juridique et les droits d’utilisation pour les images générées.
Et Adobe a lancé Firefly qui permet d’utiliser l’IA générative et des prompts pour obtenir des images, effets de texte originaux ou de palettes de couleurs inédites.
Du côté de la vidéo, YouTube teste pour les abonnés à YouTube premium un chatbot permettant de résumer et poser des questions à la vidéo. L’IA est également utilisée dans la section commentaires des vidéos pour mieux les organiser, les regrouper par catégories et les résumer.
Une deuxième vague d'IA dans les outils professionnels
Après cette première vague d’intégration dans les outils grand public utilisés par les pros de l’info, on assiste actuellement à une deuxième vague, cette fois-ci dans les outils professionnels.
Déjà abonné ? Connectez-vous...
FOCUS IA : maîtriser et gérer ses prompts

S’il n’est pas la seule clé du succès pour garantir un résultat satisfaisant d’un outil IA, un bon prompt augmente néanmoins ses chances d’obtenir satisfaction. Des milliers d’outils permettent de copier, améliorer ou encore stocker ses prompts. Ils varient en fonction des algorithmes concernés, des thèmes et des formats à générer et/ou des usages. En voici quatre sur une trentaine testés, sélectionnés pour leur efficacité et leur facilité de prise en main : Prompt Genius, PromptBase, SnackPrompt et FlowGPT.
Lire aussi :
L’art du prompt pour le professionnel de l’information, Netsources N°164 - juin 2023
AI Prompt Genius, pour stocker ses prompts personnels
AI Prompt Genius s’adresse aux personnes ayant déjà trouvé des prompts (ou « invites » en français) qui répondent à leurs besoins et ont besoin de les stocker dans un endroit accessible quelle que soit l’IA générative utilisée. Plutôt qu’une longue liste ingérable, cette extension accessible sans inscription permet de créer sa propre bibliothèque de prompts.
Elle s’ouvre sur une barre de recherche au centre et les prompts sont rangés en dossiers dans la barre de gauche.
Pour stocker un prompt, on clique sur « Nouveau prompt » et une fenêtre s’ouvre. Les champs à remplir pour créer son prompt sont « Titre », Texte (avec les variables), Description, Étiquette et on sélectionne le nom du dossier.
Prompt Genius s’utilise sur toutes les plateformes. L’outil suggère de créer des dossiers en fonction du modèle de langage concerné (ChatGPT, Bard, DALL-E, etc.) et des étiquettes sur des tonalités différentes. Ce qui rappelle qu’un même prompt n’aura pas le même résultat avec des modèles différents. Et comme chaque modèle d’IA a son propre langage, les invites doivent s’adapter à chacune.
En termes d’ergonomie, il s’affiche soit en pop-up comme la plupart des extensions, soit en barre latérale à droite de l’écran, sur ordinateur ou sur mobile. Il est aussi possible d’importer des prompts au format CSV et de les exporter en CSV ou JSON. L’outil, souvent recommandé par les professionnels de l’information et qui s’avère facile à utiliser et pratique à l’usage, est gratuit et disponible en français.
Promptbase, le supermarché des prompts
Promptbase est LA Marketplace de prompts. Intuitivement, on y choisit son domaine d’usage (éditorial, marketing, création de logos, illustrations, etc.) et son thème (animal, santé, finances, etc.) ou le modèle de langage de l’IA générative utilisée (Midjourney, DALL-E, Stable Diffusion, GPT).
Déjà abonné ? Connectez-vous...
Matilda, le nouveau moteur académique sans IA

En septembre dernier, le nouveau moteur académique Matilda était officiellement lancé. Explorez ses fonctionnalités de recherche avancées, ses fonctionnalités de veille, son vaste corpus et découvrez comment il se positionne par rapports aux outils de recherche académique.
À l’origine du projet, une équipe de chercheurs français coordonnée par Didier Torny du CNRS qui a pour ambition « de redonner une place équitable aux contenus académiques exclus des outils propriétaires actuellement utilisés, WoS et Scopus » et de « permettre aux bibliothécaires et aux chercheurs d’exercer le plus grand contrôle possible dans la manière dont ils recherchent et réutilisent les informations textuelles et les métadonnées. »
Lire aussi :
La vague d’outils IA pour l’Information Scientifique et Technique (IST) (Bases N° 420 - dec 2023)
Consensus, un moteur académique dopé à l’IA (Bases N° 410 - jan 2023)
Zendy : un moteur académique 100 % open access (Bases N° 406 - sept 2022)
Elicit, un nouveau moteur scientifique au banc d’essai (Bases N° 404 - juin 2022)
Comment faire évoluer sa recherche d’information scientifique avec les nouveautés de Google Scholar ? (Bases N° 404 - juin 2022)
Quel corpus ?
Premier aspect important : le corpus. Matilda se base sur la littérature scientifique indexée depuis 2019 dans Crossref, Pubmed Central, ArXiv et RePec soit plus de 128 millions d’articles. À cela s’ajoutent les données d’auteurs venant d’ORCID, et les articles référencés dans Unpaywall et pour lesquels on a directement accès au texte intégral.
Pour chaque article, on dispose des citations et références si elles sont disponibles.
Quelles fonctionnalités de recherche ?
Deuxième aspect important pour le veilleur : les fonctionnalités de recherche.
On revient ici aux fondamentaux, les opérateurs avec :
- Les classiques
AND,OR,NOT - Les guillemets pour l’expression exacte
- Possibilité d’utiliser les parenthèses
- L'antislash
\permet de rechercher des termes qui fonctionnent comme opérateurs pour les appliquer comme des caractères ordinaires (par exempleAND) author:pour rechercher sur le nom d’auteurorcid:pour rechercher un mot ou une expression dans l’ORCID de l’auteur du documentdescription:pour rechercher dans la description d’un documentid:pour rechercher un mot ou une expression dans les identifiants du documentpublisher:pour rechercher sur le nom de l’éditeursource:pour rechercher un mot ou une expression spécifique à la source du document (par exemple ArXiv)title:pour rechercher un mot ou une expression dans le titre du document
Plusieurs filtres sont ensuite disponibles : par titre, par type de publication, par auteur, par intervalle de dates. On peut également choisir de rechercher ou non dans les références des publications. Les résultats peuvent être classés par pertinence ou par ordre chronologique. Tous les résultats peuvent en principe être visualisés (contrairement à Google Scholar par exemple) et il est possible d’exporter les références au format BibTex.
Au départ, Matilda ne recherchait que sur les métadonnées des articles (titre, abstract, etc.). Puis il était prévu que cela soit étendu en texte intégral mais cela ne semble pas encore implémenté.
Il est également prévu que l’antériorité proposée augmente progressivement : 2019 à aujourd’hui pour le moment, mais à terme, tous les documents indexés dans Crossref, Pubmed Central, ArXiv et RePec devraient l’être aussi dans Matilda.
Quelles fonctionnalités de veille ?
Déjà abonné ? Connectez-vous...
Comment utiliser Threads pour la recherche et la surveillance de l’information ?

Threads, le réseau de micro-blogging de Meta, est accessible en France depuis quelques semaines. Le public commence à s’y rendre, y faire sa veille peut-il donc devenir intéressant ?
Threads a été créé par Meta en juillet 2023. Lancé au départ aux États-Unis, il lui a fallu plusieurs mois pour se conformer à la législation européenne. S’il a très vite dépassé les 100 millions d’utilisateurs, laissant croire à une relève assurée de X (ex. Twitter), les chiffres sont aussi très vite retombés et le manque de fonctionnalités essentielles perdure. Le terme Threads désigne ces longs fils de discussions - un post et les commentaires auxquels il donne lieu - apparus pour la première fois sur X.
Lire aussi :
Blueskyredessine la veille en feeds (Bases N° 418 - oct 2023)
Les veilleurs face au déclin de X (Twitter) - Brève de veille de novembre (nov 2023)
La veille sur les réseaux sociaux s’annonce de plus en plus fragmentée (Bases N° 417- sept 2023)
Quelques spécificités par rapport à X :
- La limite d’un post (appelé thread) est de 500 caractères et 5 minutes par vidéo,
- Les publications peuvent être modifiées dans un délai de 5 minutes (uniquement le texte, pas les pièces jointes),
- La description visuelle des photos et des vidéos pour les populations malvoyantes est automatique (mais modifiable),
- Le nombre de mentions « J’aime » sur les publications peut être masqué,
- L’insertion de sondages est prise en charge.
Lors de l’inscription, il est requis d’avoir un compte Instagram pour publier et interagir (voir Figure 1). Sans « Insta », on peut uniquement consulter des contenus et rechercher des comptes. Ce choix est réversible à tout moment, tout comme la possibilité d’avoir un profil public ou privé (cette deuxième option s’applique par défaut pour les moins de 18 ans). On peut en effet créer son compte en public (tout le monde peut nous voir et nous suivre) ou en privé.
À noter : si l’on possède plusieurs comptes Instagram (un personnel et un professionnel, par exemple), le premier pris en compte sera le compte principal, c’est-à-dire le premier créé.
Premiers constats
Une fois sur l’écran d’accueil, celui-ci propose cinq fonctionnalités en haut de l’écran (voir Figure 2) :
- Le fil d’actualité. Il s’ouvre par défaut en accueil avec un flux algorithmique, mais on bascule facilement sur le fil des comptes suivis, en bas de l’écran sur ordinateur. En revanche, sur le mobile, il faut cliquer sur le logo de Threads en haut de l’écran pour que les deux fils d’actualité, algorithmique et des comptes suivis, s’affichent. Ce flux est donc caché.
- La recherche (voir ci-dessous),
- La rédaction d’un thread,
- Le suivi de l’activité. Bien que l’icône, un cœur, laisse penser que l’on y trouverait des favoris, comptes ou publications, il n’en est rien. Il ne s’agit pas non plus du suivi de notre propre activité. Il s’agit des comptes qui nous suivent - y compris vérifiés dans un fil à part - et des réponses, mentions, citations (quotes) et republications qui sont faites de nos threads,
- Son profil.
À noter, la publicité n’est pas encore arrivée sur Threads, qui n’a pas encore la taille critique pour intéresser les annonceurs.

Figure 2. Écran d’accueil par défaut sur ordinateur. Threads a été rendu disponible sur ordinateur après la mise à disposition de l’appli sur mobile.
Premier constat, on y retrouve finalement peu de personnes de son profil Instagram, à moins d’avoir utilisé ce réseau social pour faire sa veille, ce qui est rarement le cas. Or, il est impossible d’identifier automatiquement les comptes Twitter qui auraient basculé sur Threads, sauf à faire une recherche laborieuse de chaque compte.
Déjà abonné ? Connectez-vous...
La vague d’outils IA pour l’Information Scientifique et Technique (IST)


L’Information scientifique et technique intéresse particulièrement les développeurs d’outils IA. En 2023, nous avons repéré au total plus de 20 outils IA spécifiquement dédiés à l’IST. Voici un tour d’horizon, le plus complet possible, pour aider le professionnel de la recherche d’information et de la veille à y voir plus clair et comprendre quelle place leur donner dans son activité.
Si les outils IA dédiés à l’IST s’adressent avant tout aux chercheurs, nombre d’entre eux sont également adaptés aux pros de l’info. Leur promesse ? Gain de temps et augmentation de la productivité, aux niveaux de la recherche d’information, de l’analyse et de la rédaction.
Pour cela, ces outils proposent notamment les fonctionnalités suivantes :
- Recherche dans la littérature scientifique ;
- Recommandation d’articles ;
- Résumé automatique et dialogue avec les documents ;
- Extraction de données ou concepts.
Une vingtaine d’outils répondent ainsi à un ou plusieurs de ses critères (voir l’infographie Figure 1). Ils se divisent en trois grandes catégories :
- Des outils de recherche ;
- Des plug-ins et des assistants spécialisés IST ;
- Des outils de résumé automatique, dialogue avec des documents, extractions de données.
Les moteurs IA pour l’IST
Les outils de recherche IA spécialisés dans l’IST se positionnent comme des alternatives aux moteurs académiques classiques comme Google Scholar, Dimensions ou The Lens, voire aux serveurs et outils de recherche payants comme Scopus, Web of Science, STNext, etc. Ils sont reliés à des corpus volumineux de littérature scientifique.
Leur créneau : recourir à l’IA pour fournir rapidement une sélection d’articles scientifiques pertinents issus d’un large corpus, accompagné parfois d’un résumé ou d’une synthèse des articles jugés les plus pertinents par l’outil. Plusieurs d’entre eux se présentent d’ailleurs comme des Literature review assistant.
Leur contenu : la majorité d’entre eux utilisent le corpus de Semantic Scholar (contenant plus de 200 millions d’articles scientifiques soit plus que Scopus ou Web of Science mais moins que STN et ses 320 millions - attention : parmi les 200 000 millions, seule une partie est recherchable en texte intégral, pour le reste, on ne recherche que sur les métadonnées). Ils ont aussi un fonctionnement de base similaire, où l’on entre sa recherche sous forme de question en langage naturel.
Leur modèle économique : freemium, donc avec une version gratuite pour commencer, puis un ou plusieurs niveaux d’abonnement(s).
Notre panorama des outils IA pour l’IST en une infographie :
Déjà abonné ? Connectez-vous...




















