Sélectionner le numéro de "Bases" à afficher
Scopus AI : une nouvelle façon de rechercher dans SCOPUS avec l’intelligence artificielle


La plateforme Scopus propose depuis longtemps des outils de recherche classiques : opérateurs booléens, et de proximité, navigation dans les citants/cités. Les fonctionnalités apportées par Scopus AI permettent d’expérimenter de nouvelles stratégies.
Tous les serveurs/agrégateurs présents sur le marché sont en train d’intégrer plus ou moins rapidement des fonctionnalités d’intelligence artificielle. Ils le font souvent en proposant à des bêta-testeurs, souvent des clients importants, de les aider à finaliser la mise au point de ces nouvelles fonctionnalités. D’autres, et ce n’est pas incompatible, mettent progressivement à disposition des séries d’outils innovants.
Nous ouvrons une rubrique dédiée à l’IA chez les grands serveurs de bases de données. Et nous commencerons cette série d’articles par Scopus AI, la nouvelle offre qu’Elsevier est en train de développer et qui est toujours en bêta.
Les caractéristiques de Scopus AI
Scopus AI s’appuie exclusivement sur le contenu de Scopus, c’est-à-dire sur les abstracts (donc pas les textes intégraux des documents) sur lesquels il a été entraîné. Pour le moment les documents pris en compte ne remontent pas plus loin que 1973. Il est nécessaire d’avoir accès à la plateforme Scopus pour accéder à Scopus AI.
Le contenu de Scopus
Rappelons que Scopus met à disposition plus de 91 millions de documents publiés depuis 1788, les références n’étant prises en compte que depuis 1970. Les documents référencés sont de différentes natures, essentiellement articles, comptes-rendus de conférences et chapitres d’ouvrages.
Accéder à Scopus AI
Poser une question
L’accès à Scopus AI se fait par un onglet sur l’écran d’accueil de Scopus. On est alors invité à poser une question dans la boîte de recherche. Scopus AI utilise une combinaison de technologies, certaines provenant d’Elsevier et d’autres non. Il utilise en particulier une combinaison de ses propres LLM (Large Language Model) avec d’autres, dont le modèle GPT développé par OpenAI. Mais il est précisé que cet usage est strictement privé et qu’il n’y a aucun échange d’information pouvant servir à entraîner GPT.
Le multilinguisme
La question se pose naturellement en anglais compte tenu du fait que les abstracts présents dans Scopus sont en anglais, mais des projets sont prévus pour développer le multilinguisme qui fonctionne déjà au moins en partie puisque nous avons posé une question en français qui a été parfaitement comprise et pour laquelle la réponse a été en anglais.
La structure de la réponse
Cette réponse est constituée de plusieurs éléments. On trouve un bref résumé suivi de plusieurs paragraphes qui sont autant de thématiques composant la réponse renvoyant chacune à des références sans abstract situées dans la partie droite de l’écran. Suit, enfin, une rapide conclusion indiquant, le cas échéant quelles questions n’ont pas trouvé de réponse satisfaisante. On peut à cette étape obtenir jusqu’à dix références.
Les documents fondamentaux

Déjà abonné ? Connectez-vous...
Search : quand les moteurs « recherchent pour vous »

Entre les annonces de Google et d’OpenAI, l’utilisation de l’IA dans la recherche redessine irrémédiablement les pratiques sur Internet. Aux agrégateurs traditionnels comme les moteurs de recherche et les médias sociaux, s’ajoutent donc les moteurs avec IA. Pour les veilleurs, le challenge se déplace de la synthèse à la vérification des résultats de recherche.
Il y a quelques jours, OpenAI volait la vedette à Google qui présentait pourtant sa Keynote, événement phare des groupes de la tech. La rumeur, qu’Open AI ne s’est pas empressé de démentir, annonçait le lancement de son propre moteur de recherche. Finalement, ce dernier a (en attendant?) présenté un nouveau modèle gratuit qui intègre le web et les GPTs, des fonctionnalités jusqu’alors payantes (environ 20 €/mois). Si l’on ajoute la liste d’accords de licences avec les médias qui s’allonge chaque semaine, on comprend que l’ambition de ce dernier est réelle et se veut à la hauteur des attentes.
Les utilisateurs utilisent en effet les chats d’IA comme des moteurs de recherche et y font leurs recherches malgré le risque d’hallucination. La recherche d’informations fait ainsi partie des usages inattendus des modèles de langage, créés à l’origine pour deviner des suites de phrases. D’après une étude de The Verge, 53 % des utilisateurs et 61 % des Millenials utilisent les chats IA plutôt que les moteurs de recherche traditionnels pour faire leurs recherches.
Une recherche sans liens…
De son côté, Google, qui représente encore près de 87 % de part de marché dans le monde, a annoncé le futur de Google SGE, son moteur de recherche enrichi à l’IA. Il s’appelle « AI Overviews » (« Aperçus IA ») et pourrait être disponible en France à la fin de l’année 2024. Cette version, qui utilise Gemini pour comprendre les requêtes, propose un résumé des résultats de recherche, notamment pour les recherches les plus complexes, ainsi que d’autres innovations comme les réponses sous forme d’images ou la catégorisation des résultats de recherche.
Mais surtout, Google présente son futur moteur comme suit : « Google fera la recherche sur Google pour vous ». Ce qui n’est pas sans rappeler la fonctionnalité « Browse for Me » (Recherche pour moi) du navigateur Arc (voir notre article Search : Arc ouvre la voie à de nouvelles pratiques de recherche, BASES N° 424, avril 2024). Mais si Google prévoit d’ajouter quelques liens à ses résumés de requêtes pour « aller plus loin », l’utilisation d’Arc a déjà montré aux utilisateurs français à quel point cliquer sur ceux-ci devient… inutile, voire superflu, y compris pour le professionnel de l’information.

Figure 1 : Avec Google Overviews, les résultats de recherche « aperçus » fournis par IA disposent de trois niveaux de réponse différents : original, simplifié ou développé.
Après « un monde sans sources » (voir notre article IA : la veille dans un monde sans sources, BASES N° 416, juillet 2023), le veilleur découvre donc un monde sans liens (ou presque), voire « sans clic », puisque les résultats disparaissent de la première page de recherche.
Certes, à la liste de liens à parcourir et à lire, succède donc une réponse immédiate, personnalisée. De quoi mettre fin à la surabondance de l’information par des résultats fournis sous forme de synthèse composée des sources (rarement identifiés) ayant servi à alimenter l’IA. Cela constitue aussi moins de saisie, moins d’onglets et plus de discussions avec un moteur de recherche.
… et sans sites internet ?
Jusqu’à présent, l’écosystème de Google constituait un point d’entrée d’internet basé sur des liens vers le contenu des éditeurs. Et comme Google reste de loin la plus grande source de trafic sur le Web aujourd’hui, s’il « garde ce trafic pour lui-même » en répondant aux questions avec l’IA, ou « s’il remplace le web par lui-même », comme le notent certains observateurs américains, il est susceptible changer l’écosystème tel que nous le connaissons.
Déjà abonné ? Connectez-vous...
La pérennité en question des informations sur le web

Deux études récentes révèlent que la durabilité des informations sur le web est loin d’être garantie.
La première traite des liens DOI et montre qu’environ 27 % des documents ne sont pas conservés dans des archives pérennes. La seconde étude indique que 25 % des pages web créées il y a dix ans ont disparu, et de nombreux liens sur ces pages sont brisés. Ces résultats mettent en lumière les défis de la préservation de l’information numérique à long terme.
C’est un grand changement si on se réfère à l’ère du papier qui a débuté en 1 450 et a duré environ cinq siècles sans partage. En effet, pendant cette période, le support papier pour l’information paraissait relativement éternel préservé au moins pendant très longtemps dans les bibliothèques sauf incident majeur tel qu’un incendie ou les conséquences d’un conflit armé.
Les deux études récentes que nous allons présenter portent sur l'accessibilité de l'information sur le web. Elles montrent que la possibilité de se connecter pour accéder à ces informations a une fâcheuse tendance à diminuer à mesure que le temps passe.
La première étude est consacrée à la pérennité des liens attachés à un DOI (digital object identifier), très souvent un article scientifique tandis que la seconde s’est attachée d’une part à l’accessibilité dans la durée des pages web et, d’autre part à la pérennité des liens présents dans une page web.
Plusieurs millions d’articles deviendraient inaccessibles sur Internet
L’analyse à partir des DOIs
Tous les documents sous forme électronique (articles, comptes rendus de conférences, ouvrages…) se voient attribuer depuis 1998 un numéro de DOI (digital object identifier) de même que certains documents imprimés, même publiés avant 1998.
Ce DOI est le plus souvent attribué par l’éditeur, mais, par exemple pour un preprint l’auteur cherchera une archive qui attribue des DOIs.
Le DOI est une suite de caractères alphanumériques commençant par « 10. ». Il est lié de façon définitive au document auquel il est rattaché quels que soient ses mouvements, et même en cas de disparition de l’éditeur.
L’International DOI Foundation attribue à chaque « DOI registration agency » un préfixe unique qui vient après le « 10. ».
Chaque agence fournit ensuite à ses organisations membres (éditeurs, sociétés savantes…) des DOIs à attribuer à leurs publications (articles, livres, jeux de données…) intégrant son préfixe.
Ces agences gèrent un système de « résolution » de DOI permettant de faire le lien entre un DOI et l’emplacement en ligne de la ressource identifiée même si elle a été déplacée.
Les principales agences d’enregistrements de DOIs sont CROSSREF pour les publications académiques, DataCite pour les jeux de données de recherche, EIDR (Entertainment Identifier Registry) pour les films, les émissions de télévision, les enregistrements de spectacles, les podcasts et autres documents audiovisuels d’intérêt commercial ou culturel.
Il existe aussi des agences à vocation plus territoriales comme KISTI (Korean DOI Center) pour la Corée du Sud, CNKI (China National Knowledge Infrastructure) pour la Chine, ce dernier proposant également une banque de données de publications scientifiques chinoises.
Une recherche à partir de Crossref
Martin EVE, un chercheur de l’université anglaise de BIRBECK à Londres qui travaille aussi pour Crossref en tant que « principal R&D developer » s’est interrogé sur la réelle pérennité des liens permettant, à partir d’un DOI, d’accéder au document (1).
Méthodologie :
L’auteur a considéré que, pour garantir un accès pérenne au document, il était préférable qu’il soit présent dans plusieurs archives (instances de préservation).
Il a mené une étude en avril 2023 à partir des documents dont les DOIs sont attribués par des membres de Crossref.
Comme il n’était pas question de travailler sur les 144 millions de documents concernés, il a extrait de façon aléatoire 1 000 DOIs issus de chaque membre, ce qui l’a conduit à un total de près de 7,5 millions de DOIs.
Le professeur Eve a d’abord considéré qu’un document avait plus de chances d’être retrouvé dans le futur s’il était stocké dans plusieurs archives.
En définissant un critère relativement complexe, il a constaté que seul un petit nombre, soit 204 membres de Crossref, soit 0, 96 % préservaient au moins 75 % de leurs documents dans au moins trois archives. On trouvera dans l’article de cet auteur d’autres mesures selon des critères analogues et détaille des résultats inquiétants.
Déjà abonné ? Connectez-vous...
ResearchGate développe ses liens avec les éditeurs

ResearchGate est un réseau social consacré aux chercheurs leur permettant d’échanger entre eux sur différentes questions et de partager leurs publications.
Récemment ResearchGate a signé des accords avec de nombreux éditeurs offrant ainsi un contenu de plus en plus important, avec, malheureusement des possibilités de recherche très limitées.
ResearchGate multiplie depuis quelques mois les annonces de partenariat avec des éditeurs scientifiques.
Cette stratégie peut être décomposée en deux volets :
• La mise en ligne d’articles, essentiellement en open access, de nombreux éditeurs;
• D’autre part, des accords particuliers confidentiels avec Elsevier et ACS (American Chemical Society) signés en fin de l’année dernière.
La mise en ligne de nouveaux contenus open access d’un grand nombre d’éditeurs
Le premier volet est donc le chargement sur la plateforme ResearchGate des contenus de nombreux éditeurs, et pas les moindres.
On peut, en effet, citer, rien que pour les quatre premiers mois de 2024 : Trans Tech Publications (7 titres), SAGE (100 titres), Cambridge University Press (16 titres), Taylor & Francis (400 titres), Wiley (700 titres), Optica Publishing (105 000 articles depuis 2012). Pour sa part, l’accord avec Emerald Journals (18 titres) date de juillet 2023.
Ces contenus sont principalement en open access. Pour les articles payants, le système vérifie quels sont les droits d’accès de l’utilisateur liés à son affiliation académique s’il en a une. Il peut aussi demander directement à l’auteur une copie à usage privé, mais l’expérience montre que si l’on n’a pas une adresse mail montrant sans ambiguïté que l’on appartient au monde académique on n’a pratiquement aucune chance d’obtenir une réponse positive de l’auteur.
Restent donc, le cas échéant, l'outil Unpaywall, les bibliothèques, les sites d’éditeurs, ou, pour les entreprises, les fournisseurs de documents primaires comme Reprints Desk aux États-Unis.
Les accords signés avec Elsevier et ACS
Ces accords ont été signés fin 2023 entre ACS et Elsevier d’une part et ResearchGate d’autre part. Ils mettent un terme aux poursuites qui avaient été engagées depuis 2007 par ces deux éditeurs.
Ce qu’on comprend de ces accords particuliers et confidentiels, c’est qu’au moment du téléchargement d’un article par un auteur sur le site, une vérification automatique est effectuée pour identifier les différentes possibilités de partage disponibles.
Un changement radical de relation avec les éditeurs
Les relations avec les éditeurs n’ont pas été un long fleuve tranquille (cf. notre article « ResearchGate contraint de supprimer 200 000 articles », Bases N° 396 - oct 2021). Une nouvelle politique a initiée vis-à-vis d’eux en 2022, selon le rapport financier relatif à cette année-là (le dernier disponible).
Déjà abonné ? Connectez-vous...
Faire ses recherches avec un GPT

Utiliser un assistant IA monotâche comme les GPTs d’OpenAI permet d’utiliser un modèle de langage dans un but spécifique et de façon plus précise qu’avec un chatbot généraliste comme ChatGPT, Gemini ou Copilot. Nous en avons testé une vingtaine dédiés à la recherche et voici les résultats de notre sélection.
Les agents virtuels ne sont pas simplement capables de converser et de guider l’utilisateur comme un chatbot, mais ils peuvent aussi adapter leurs réponses au contexte et à l’intention de celui-ci.
Les plus connus sont les GPTs d’OpenAI, même si d’autres agents sont apparus comme les Hugging Chat Assistants de Hugging Face et les copilotes de Microsoft.
Mais les GPTs d’OpenAI, d’après nos tests, restent les plus opérationnels. Attention, ils ne sont toutefois disponibles qu’avec la version payante GPT Plus, pour un résultat qui reste inégal.
Consensus, l’as de la recherche scientifique
Consensus intègre intelligemment la capacité d’analyse des IA pour l’appliquer à la recherche d’articles scientifiques. L’outil existe sous forme de GPT à utiliser avec ChatGPT et sous forme de plateforme (https://consensus.app/) à part entière pour une utilisation plus complète. Pour le retrouver dans le GPT Store, il faut se rendre sur « Explorer les GPTs » dans la barre de gauche, puis taper directement le mot-clé Consensus.
Quel que soit le point d’entrée, le fonctionnement général est le même : on pose une question précise dans la barre de dialogue, comme « Le sauna est-il bon pour la santé ? » ou « la méditation peut-elle modifier notre cerveau ? » et Consensus s’applique à retrouver la réponse, avec un niveau de précision inédit. Pour juger de sa fiabilité, cette réponse est constituée des extraits issus des sources identifiées par un lien qui renvoie à la plateforme Consensus (voir Figure 1).
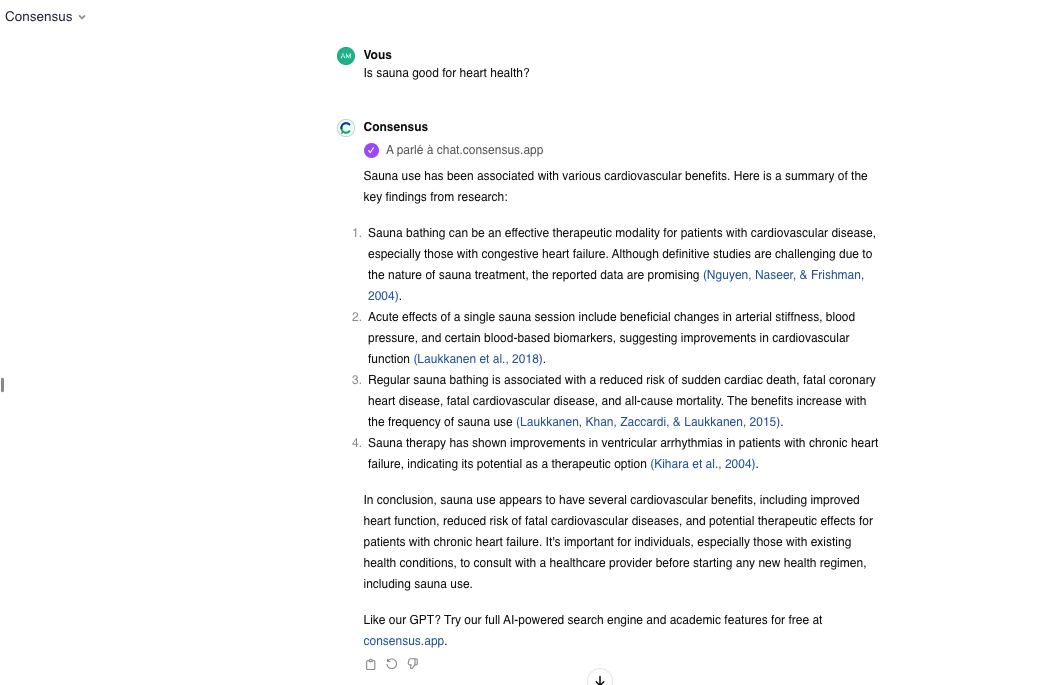
Figure 1 : Les résultats du GPT Consensus sont présentés sous forme de synthèse avec des exergues qui dirigent vers les sources.
Sur la plateforme, les extraits permettent de trouver rapidement si le document est pertinent et pointent vers l’endroit où l’extrait se situe précisément dans l’article scientifique (un gain de temps inestimable !). De plus, un bouton Study snapshot donne un descriptif rapide de la méthodologie des recherches de chaque article cité (échantillon, etc.) afin de pouvoir en juger en un clin d’œil.
Enfin, une fonctionnalité de synthèse fonctionne également pour les questions fermées. Dans ce cas, la réponse est analysée sous forme de pourcentage du nombre d’études qui penchent en faveur de « oui » et « non » ou « possible », en plus d’un résumé des réponses (voir Figure 1 bis). Enfin, la recherche peut être approfondie à l’aide de nombreux filtres comme : les échantillons ou la réputation de la revue. En revanche, il est nécessaire de filtrer les résultats par dates afin d’obtenir les dernières études.

Figure 1bis : Les résultats de la plateforme Consensus… nettement plus complets que son GPT.
Alimenté par les quelque 200 millions d’articles académiques de Semantic Scholar, Consensus est mis à jour régulièrement. À noter, l’historique archivé sur OpenAI reste aléatoire et n’apparaît pas à la connexion suivante du GPT, contrairement à la plateforme, qui permet d’archiver recherches et articles, même en version gratuite. La plateforme, disponible avec une version gratuite, permet d’ailleurs de s’affranchir de l’abonnement payant à ChatGPT, puisqu’elle propose un nombre de recherches illimité et quelques crédits pour utiliser l’IA.
Déjà abonné ? Connectez-vous...
Search : Arc ouvre la voie à de nouvelles pratiques de recherche

La nouvelle fonctionnalité de recherche IA « Browse for Me » du navigateur Arc n’est disponible que sur iPhone et elle fait déjà grand bruit.
Non seulement elle a été rapidement adoptée par les utilisateurs, mais la presse y voit une fonctionnalité qui réinvente la façon de s’informer… et pourrait être le pire cauchemar des éditeurs.
Pour les professionnels de la veille, son impact pourrait bien aller au-delà du Search.
Disponible depuis quelques mois sur Windows après avoir été adopté par les utilisateurs de Mac (voir notre article « Arc browser réinvente la navigation en ligne », BASES N° 420, décembre 2023), le navigateur Arc vient à nouveau d’attirer l’attention du monde de la tech avec sa nouvelle fonctionnalité « Browse for Me » (que l’on pourrait traduire en français par « cherche pour moi »).
Disponible uniquement sur les iPhones actuellement, le bouton « Browse for Me » apparaît au cours de l’écriture dans la barre de recherche (voir Figure 1).

Figure 1 : La fonctionnalité « Browse for Me » apparaît au cours de l’écriture dans la barre de recherche.
Pour s’informer des dernières actualités, on peut rédiger une invite simple, de type : « quelle est l’actualité internationale aujourd’hui en France ? » ou « quelle est l’actualité du secteur cosmétique aujourd’hui en France ? », Arc fournit une liste factuelle, composée de résumés générés par IA (voir Figures 2 et 3).
Exit la liste de liens qui renvoient vers des articles payants, les autorisations de cookies, les publicités et autres boutons d’abonnement… En bref, tout ce qui fait obstacle à l’information brute.

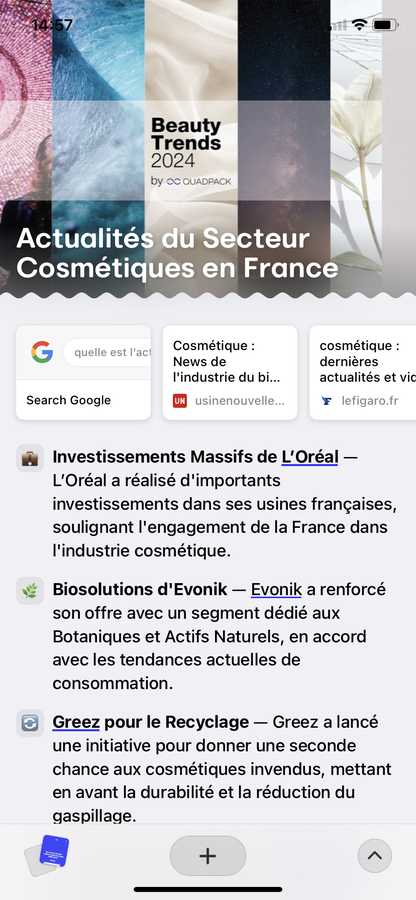
Figures 2 et 3 : Les premiers résultats apparaissent sous forme d’une liste de résumés d’une phrase (on peut cliquer sur des liens proposés au-dessus de la liste, sous forme de snippets)
Lorsqu’une requête est effectuée, Arc explore le contenu des médias en ligne, le résume et… consent à laisser quelques liens en haut et en bas de la réponse. Mais il n’y a fondamentalement plus besoin de cliquer puisque la réponse est déjà fournie.
Et au lieu d’apparaître sous forme d’une liste de liens sur lesquels cliquer pour obtenir des bribes de réponses comme sur Google ou de chat comme sur Copilot, Arc propose une page web personnalisée selon les requêtes de recherche et générée par IA : sous une première liste des grands titres de l’actualité, des sous-sections apparaissent (voir le résultat de notre requête en cliquant sur ce lien, même si vous n’êtes pas doté du navigateur ou de l’app).
Déjà abonné ? Connectez-vous...
Les statistiques au service de la stratégie documentaire

Qu’il s’agisse du pilotage, de la valorisation ou de la communication de l’activité documentaire, comment les fonctionnalités statistiques de ces outils aident le documentaliste à tirer le meilleur parti de ses outils numériques ?
En documentation, nous avons recours à divers outils numériques pour accompagner nos activités, diffuser nos produits ou offrir des abonnements adaptés à nos utilisateurs.
Ces outils ne sont pas utilisés de la même façon selon la mission du service, la période de l’année et le type d’utilisateurs visés.
Grâce à l’analyse statistique, il est possible d’en tirer le meilleur parti en fonction de son propre usage. Voici trois exemples concrets, tirés de trois types d’outils différents.
Les outils de pilotage interne
L’analyse des statistiques fournies par les outils de gestion des fournisseurs d’information, les outils métier comme les logiciels documentaires ou un Système intégré de gestion de bibliothèque (SIBG) ou encore les outils de diffusion, permettent aux services d’information d’adapter leur offre de produits et services documentaires à leurs utilisateurs.
Par exemple, l’analyse de statistiques des bases de données proposées par Factiva, Orbis, Dalloz, etc. apporte un éclairage sur l’utilisation de leurs contenus comme le taux de consultation ou de téléchargement des informations.
Compte tenu de leur coût d’abonnement souvent très élevé, le service d’information doit évaluer les statistiques de ces outils afin de garantir leur rentabilité. En fonction des chiffres recueillis, plusieurs conclusions peuvent être tirées et un plan d’action être établi.
Que la ressource soit sous-exploitée ou au contraire surexploitée, il faudra en comprendre les raisons : les utilisateurs connaissent-ils l’existence de l’outil ? Savent-ils s’en servir correctement ? Rencontrent-ils des difficultés de connexion ? L’outil répond-il à leurs besoins ?
Ces statistiques apportent ainsi autant d’informations nécessaires pour décider de façon éclairée de l’arrêt de l’abonnement ou au contraire de l’augmentation du « forfait » de mener une campagne de communication ou encore d’organiser des sessions de formation.
Déjà abonné ? Connectez-vous...
Comment les technologies cessibles enrichissent la veille technologique

Dans le cadre d’une veille technologique, souvent couplée à une démarche d’innovation/diversification, il peut être intéressant de surveiller non seulement les publications (articles, conférences, brevets), mais aussi les technologies cessibles.
Les technologies (à céder ou à licencier) peuvent constituer des compléments très pertinents et aussi des amorces de nouvelles collaborations. Ce peut être aussi l’occasion pour l’acquéreur d’une de ces technologies de gagner du temps, notamment en R&D et, éventuellement, de l’argent, en fonction des conditions de cession.
Ces technologies sont les résultats des travaux de chercheurs d’une université, d’une école d’ingénieur ou d’un centre de recherche. Elles peuvent faire l’objet d’une licence ou être vendues (en général, c’est le brevet qui est vendu). En effet, tous ces organismes cherchent à valoriser les technologies qu’ils ont développées en les cédant, car ils n’ont pas vocation à les emmener sur le marché, sauf en cas de création d’une startup.
Notre société de conseil FLA Consultants propose par ailleurs cette prestation de veille professionnelle, n'hésitez pas à nous contacter pour en savoir plus Cette adresse e-mail est protégée contre les robots spammeurs. Vous devez activer le JavaScript pour la visualiser..
Comment les détecter ?
Nous ne nous sommes pas intéressés ici au cas des entreprises cherchant à valoriser des technologies, mais à celui des universités et des centres de recherches qui « produisent » des technologies.
En application de cette démarche, nous avons ainsi enrichi plusieurs veilles technologiques effectuées par notre cabinet FLA Consultants en cherchant des technologies cessibles dans leurs domaines technologiques, qui ont chez plusieurs clients suscité leur intérêt.
Nous nous sommes focalisés dans un premier temps sur les technologies européennes et nord-américaines. Nous consacrons aux technologies d’origine française un autre article dans ce numéro : « En France, la prééminence du réseau des SATT ».
Pour identifier les sources de technologies, nous avons procédé ainsi :
- Une première recherche dans Google avec l’expression
« technology transfer »donne surtout des définitions, ce qui n’est pas ce que nous recherchons.
Cette première recherche fait apparaître également l’expression plus précise « technology transfer office » (TTO en abrégé), qui paraît bien décrire le service s’occupant effectivement du transfert de technologies, ce qui nous intéresse. Nous relançons la recherche avec cette expression, ce qui donne un nombre important de résultats pertinents. - Nous avons ensuite recherché dans le moteur d’IA Perplexity en utilisant la formulation assez logique au point où nous en étions :
« Où trouver une liste des technology transfer offices des universités ? ».
Le premier résultat est particulièrement pertinent puisqu’il s’agit de l’« University Licensing Offices Top 50 » pour les universités américaines. Précisons que la même recherche effectuée à nouveau dans Perplexity ne génère pas nécessairement les mêmes résultats.
À partir de là, nous avons poursuivi les recherches avec diverses stratégies dans Google, en remarquant que les pages dans lesquelles se trouvent les descriptions des technologies offertes sont souvent difficiles à localiser dans le site d’une université. Ceci est surprenant, compte tenu de leur vocation à être le plus visibles possible.
Le volume de technologies offertes est ici très variable, allant de quelques dizaines de technologies, voire moins d’une dizaine, à plusieurs milliers.
Une université ne présentant qu’un petit nombre de technologies peut néanmoins présenter de l’intérêt, car ses technologies peuvent être considérées comme un prétexte à une prise de contact pouvant aboutir à des collaborations — d’ailleurs non nécessairement liées à ces technologies.
Il faudra être attentif à la date de création de l’offre, car certains sites ont la fâcheuse habitude de maintenir la présence d’offres anciennes, voire très anciennes. On peut d’ailleurs parfois se demander si les offres qui ne sont plus d’actualité, quelle qu’en soit la raison, sont effectivement retirées. Cependant, il peut arriver qu’une technologie proposée il y a longtemps résolve un problème d’aujourd’hui.
Déjà abonné ? Connectez-vous...
En France, la prééminence du réseau des SATT

Les Sociétés d’Accélération du Transfert de Technologies (SATT) en France jouent un grand rôle dans le développement technologique des innovations issues de la recherche publique française.
Les SATT (Sociétés d’Accélération du Transfert de Technologies) sont au nombre de 13, réparties sur l’ensemble du territoire français. Ce réseau a été créé en trois vagues de 2012 à 2014 dans le cadre du Programme d’Investissement d’Avenir, selon un rapport du Sénat (1), « pour répondre à certaines lacunes du système de valorisation français ». Les SATT sont des SAS de droit privé. Les actionnaires « outre l’État par le biais de Bpifrance » sont tous des organismes publics (enseignement et recherche).
« Elles financent le développement technologique des innovations issues de la recherche publique française (laboratoires et centres de recherche) grâce à un fonds d’investissement (…) de 856 M€. ». Au moins certaines de ces SATT bénéficient de subventions de leur Conseil Régional et de fonds européens FEDER (Fonds Européen de Développement Régional). « Elles détectent, évaluent, protègent et conduisent ces inventions jusqu’au marché en les confiant à une entreprise existante ou à une future startup. »
Les SATT couvrent environ 165 établissements de recherche et 150 000 chercheurs/docteurs, ce qui représente environ 80 % de la recherche publique française. Plus précisément ces technologies ont, pour 44 % d’entre elles été à l’origine de la création de startups, 45 % ont été transférées vers des TPE/PME et 11 % vers de grands groupes.
Source : service de communication du réseau des SATT
Récemment, en particulier après l’organisation de Deep Tech Meetings, des conventions d’affaires ayant pour but de mettre en relation offreurs et demandeurs de technologie, le besoin est apparu d’une plateforme/marketplace regroupant des offres de technologies sélectionnées. Cela a conduit au lancement de la plateforme TECH-365.fr.
Celle-ci propose, à la date d’écriture de cet article, 387 technologies réparties au sein de quatre grandes filières stratégiques : Greentech, Numtech, Biotech et Medtech.
Ces technologies ont nécessairement fait l’objet d’une demande de brevet et sont à un stade de développement de TRL3 à TRL6 (2).
Cette plateforme pensée pour la prise de rendez-vous est dérivée de celle utilisée par la société Proximum qui organise de nombreuses conventions d’affaires dans le domaine des technologies tels Les Rendez-vous Carnot ou Techinnov.
Contrairement à ce que l’on observe dans quasiment tous les pays dans lesquels nous avons trouvé de nombreuses marketplaces en accès libre, l’accès à cette banque de données est non seulement payant, mais aussi soumis à une sorte d’examen de passage pour s’assurer du sérieux du demandeur et de la qualité de sa démarche.
“C’est un choix stratégique et de sécurité. Nous filtrons les inscriptions pour éviter l’accès au catalogue à des structures non identifiées. Les technologies que nous portons sont des brevets issus de la recherche publique, il convient donc de savoir à qui nous donnons accès à ces informations " explique le service de communication du réseau des SATT.
Le « service central » des SATT qui gère la plateforme se définit comme un gardien. Cette « centralisation » n’empêche pas la plupart des SATT de présenter des technologies cessibles sur leur site dont le total est supérieur à ce que l’on trouve dans TECH 365.
Notre commentaire
On retrouve bien là un penchant bien français consistant à confier à l’État des missions a priori d’intérêt public et de bien en verrouiller la réalisation.
On est quand même un peu gêné par cet « examen de passage » pour accéder à « TECH-365 » d’autant que la plupart des SATT proposent des technologies en libre accès. Nous avions gardé de l’ANVAR (intégrée aujourd’hui dans Bpifrance qui est un des financeurs des SATT) une impression de liberté et d’efficacité avec un système nettement moins verrouillé. Il semblerait que cet état d’esprit se soit un peu perdu.
Avec une couverture de 80 %, il est très probable que lors de la recherche d’un service de transfert de technologies d’une école d’ingénieur ou d’une université, vous soyez redirigé vers la SATT de sa région.Il y a néanmoins des « récalcitrants » qui préfèrent continuer à valoriser eux-mêmes leurs technologies. On pense par exemple à INSERM transfert, INRAE transfert, au réseau CURIE, etc.
Nous avons eu récemment une expérience qui ternit quelque peu le discours du service de communication du réseau des SATT. Dans le cadre de notre recherche de technologies, nous avons identifié. deux technologies dans deux SATT différentes auprès desquelles nous avons manifesté notre intérêt en demandant des informations complémentaires.
Nous attendons toujours…
References:
(1) Rapport d’information n° 683 (2016-2017), déposé le 26 juillet 2017 : « Les SATT : des structures de valorisation de la recherche publique qui doivent encore faire la preuve de leur concept ».
(2) L’échelle TRL (Technology readiness level) évalue le niveau de maturité d’une technologie jusqu’à son intégration dans un système complet et son industrialisation.
Booster sa bureautique gratuitement ... ou presque

Avec les modules complémentaires (appelés aussi « add-ons » et « add-ins ») des suites bureautiques de Microsoft et Google, il est possible de booster à l’IA ses logiciels de rédaction, tableurs et présentations. Cela permet de bénéficier des fonctionnalités de ChatGPT tout en restant dans son environnement de travail. Nous avons testé une douzaine d’extensions gratuites, et voici les quatre utiles à connaître.
GPT for Work (Excel Word et GPT for Sheets and Docs)
Notre chouchou, et pas seulement car il est développé par une entreprise française ! Talarian a développé deux modules, un pour la suite Microsoft (Word+Excel) et un autre pour la suite Google (Docs+Sheets).
On les trouve sur le site de Talarian, sur la Marketplace de Google Workspace ou dans le catalogue de modules complémentaires de Microsoft, via notamment le menu. Pour faire fonctionner ce logiciel avec ChatGPT, il est nécessaire créer une clé API sur ChatGPT (voir le tuto réalisé par WeDoData).
Avec Excel ou Sheets, cette extension permet de nettoyer et d’enrichir sa base de données en introduisant directement dans son document les invites (ou prompts) prérédigées de ChatGPT. Le plus impressionnant est sans doute lorsqu’on extrait ou ajoute des informations en ligne en décrivant simplement son besoin en langage naturel, sans recourir à des formules complexes.
Par exemple, pour compléter une liste de noms d’entreprises avec leurs départements, numéros de téléphones ou les villes d’établissement, on ajoute une colonne et il suffit d’insérer une invite préenregistrée dans une cellule, comme
=GPT(« indique les numéros de téléphone »). Pour plus d’exemples, voir notre article Maîtriser l’open data et l’IA pour transformer et exploiter les données différemment, NETSOURCES N° 168, Janvier-février 2024.
Attention toutefois au risque d’hallucinations dans ce cas. Pour le limiter, penser au prompt, testé et approuvé « Si tu ne sais pas, n’invente pas », qui réduit grandement la marge d’erreur. Sur Word et Docs, l’extension fonctionne en français et il est possible de créer ou modifier du texte.
La version actuellement en ligne est une bêta gratuite, mais elle est aussi soumise aux limites de l’offre d’essai l’API de ChatGPT. Pour l’utiliser, il vaut mieux disposer de la version payante de ChatGPT. Il est aussi possible dans certains pays de choisir le modèle Claude en se connectant à l’API d’Anthropic, mais cette dernière n’est pas disponible en Europe.
Enfin, sur la suite Google, il faut savoir que le menu « Extension » qui permet d’afficher les « add-ons » ne s’affiche que sur les documents non partagés !
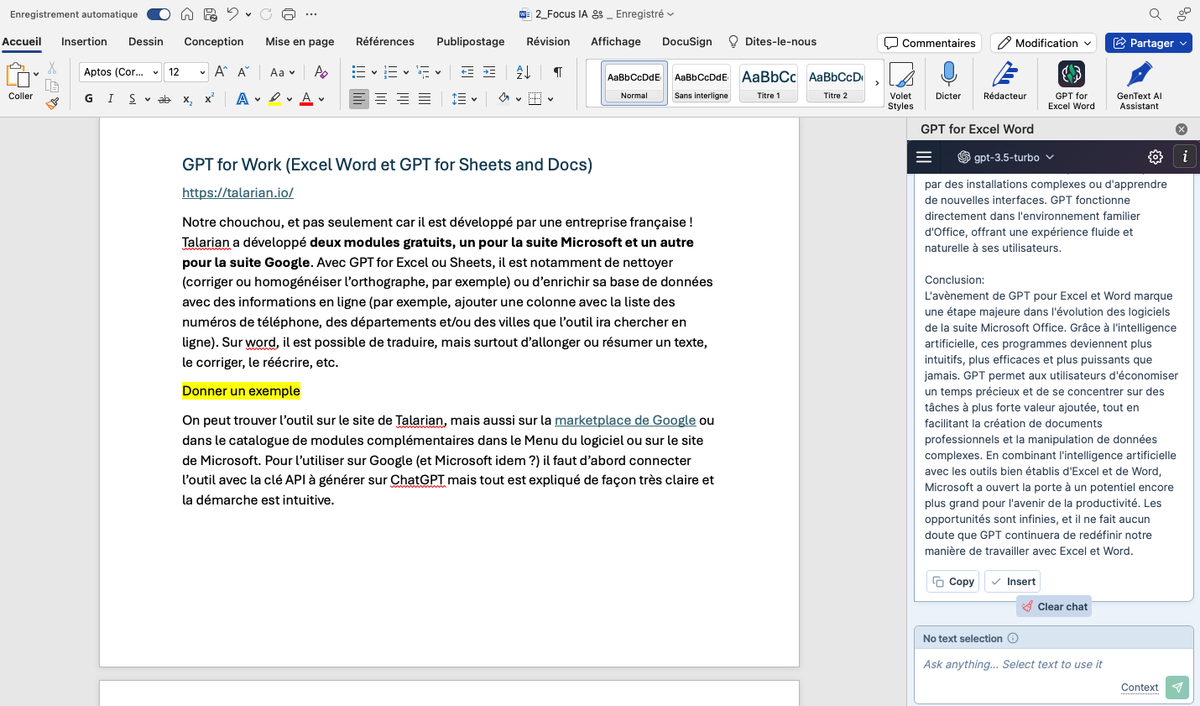
Figure 1 : Sur Word, GPT for Work s’affiche dans la barre d’outils et pour l’utiliser, une barre latérale s’ouvre à droite du document.
Déjà abonné ? Connectez-vous...




















